編輯:關於android開發
GTID(Global Transaction ID)是MySQL5.6引入的功能,可以在集群全局范圍標識事務,用於取代過去通過binlog文件偏移量定位復制位置的傳統方式。借助GTID,在發生主備切換的情況下,MySQL的其它Slave可以自動在新主上找到正確的復制位置,這大大簡化了復雜復制拓撲下集群的維護,也減少了人為設置復制位置發生誤操作的風險。另外,基於GTID的復制可以忽略已經執行過的事務,減少了數據發生不一致的風險。
GTID雖好,要想運用自如還需充分了解其原理與特性,特別要注意與傳統的基於binlog文件偏移量復制方式不一樣的地方。本文概述了關於GTID的幾個常見問題,希望能對理解和使用基於GTID的復制有所幫助。
根據官方文檔定義,GTID由source_id加transaction_id構成。
GTID = source_id:transaction_id
上面的source_id指示發起事務的MySQL實例,值為該實例的server_uuid。server_uuid由MySQL在第一次啟動時自動生成並被持久化到auto.cnf文件裡,transaction_id是MySQL實例上執行的事務序號,從1開始遞增。 例如:
e6954592-8dba-11e6-af0e-fa163e1cf111:1
一組連續的事務可以用'-'連接的事務序號范圍表示。例如
e6954592-8dba-11e6-af0e-fa163e1cf111:1-5
更一般的情況是GTID的集合。GTID集合可以包含來自多個source_id的事務,它們之間用逗號分隔;如果來自同一source_id的事務序號有多個范圍區間,各組范圍之間用冒號分隔,例如:
e6954592-8dba-11e6-af0e-fa163e1cf111:1-5:11-18,e6954592-8dba-11e6-af0e-fa163e1cf3f2:1-27
即,GTID集合擁有如下的形式定義:
gtid_set: uuid_set [, uuid_set] ... | ''uuid_set: uuid:interval[:interval]...uuid: hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhhh: [0-9|A-F]interval: n[-n] (n >= 1)
可以通過MySQL的幾個變量查看相關的GTID信息。
gtid_executed
在當前實例上執行過的GTID集合; 實際上包含了所有記錄到binlog中的事務。所以,設置set sql_log_bin=0後執行的事務不會生成binlog 事件,也不會被記錄到gtid_executed中。執行RESET MASTER可以將該變量置空。
gtid_purged
binlog不可能永遠駐留在服務上,需要定期進行清理(通過expire_logs_days可以控制定期清理間隔),否則遲早它會把磁盤用盡。gtid_purged用於記錄已經被清除了的binlog事務集合,它是gtid_executed的子集。只有gtid_executed為空時才能手動設置該變量,此時會同時更新gtid_executed為和gtid_purged相同的值。gtid_executed為空意味著要麼之前沒有啟動過基於GTID的復制,要麼執行過RESET MASTER。執行RESET MASTER時同樣也會把gtid_purged置空,即始終保持gtid_purged是gtid_executed的子集。
gtid_next
會話級變量,指示如何產生下一個GTID。可能的取值如下:
這些變量可以通過show命令查看,比如
mysql> show global variables like 'gtid%';+----------------------+------------------------------------------+| Variable_name | Value |+----------------------+------------------------------------------+| gtid_deployment_step | OFF || gtid_executed | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-6 || gtid_mode | ON || gtid_owned | || gtid_purged | |+----------------------+------------------------------------------+5 rows in set (0.02 sec)mysql> show variables like 'gtid_next';+---------------+-----------+| Variable_name | Value |+---------------+-----------+| gtid_next | AUTOMATIC |+---------------+-----------+1 row in set (0.00 sec)
GTID的生成受gtid_next控制。 在Master上,gtid_next是默認的AUTOMATIC,即在每次事務提交時自動生成新的GTID。它從當前已執行的GTID集合(即gtid_executed)中,找一個大於0的未使用的最小值作為下個事務GTID。同時在binlog的實際的更新事務事件前面插入一條set gtid_next事件。
以下是一條insert語句生成的binlog記錄
mysql> use `test`Database changedmysql> insert into tbx1 values(1);Query OK, 1 row affected (0.01 sec)mysql> show binlog events IN 'binlog.000015';+---------------+-----+----------------+-----------+-------------+-------------------------------------------------------------------+| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |+---------------+-----+----------------+-----------+-------------+-------------------------------------------------------------------+...| binlog.000015 | 707 | Gtid | 1 | 755 | SET @@SESSION.GTID_NEXT= 'e10c75be-5c1b-11e6-ab7c-000c296078ae:9' || binlog.000015 | 755 | Query | 1 | 834 | BEGIN || binlog.000015 | 834 | Query | 1 | 934 | use `test`; insert into tbx1 values(1) || binlog.000015 | 934 | Xid | 1 | 965 | COMMIT /* xid=20 */ |
在Slave上回放主庫的binlog時,先執行set gtid_next ...,然後再執行真正的insert語句,確保在主和備上這條insert對應於相同的GTID。
一般情況下,GTID集合是連續的,但使用多線程復制(MTS)以及通過gtid_next進行人工干預時會導致gtid空洞。比如下面這樣:
mysql> show master status;+---------------+----------+--------------+------------------+------------------------------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+---------------+----------+--------------+------------------+------------------------------------------+| binlog.000015 | 965 | | | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-9 |+---------------+----------+--------------+------------------+------------------------------------------+1 row in set (0.00 sec)mysql> set gtid_next='e10c75be-5c1b-11e6-ab7c-000c296078ae:12';Query OK, 0 rows affected (0.00 sec)mysql> begin;Query OK, 0 rows affected (0.00 sec)mysql> commit;Query OK, 0 rows affected (0.00 sec)mysql> set gtid_next='AUTOMATIC';Query OK, 0 rows affected (0.00 sec)mysql> show master status;+---------------+----------+--------------+------------------+---------------------------------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+---------------+----------+--------------+------------------+---------------------------------------------+| binlog.000015 | 1158 | | | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-9:12 |+---------------+----------+--------------+------------------+---------------------------------------------+1 row in set (0.00 sec)
繼續執行事務,MySQL會分配一個最小的未使用GTID,也就是從出現空洞的地方分配GTID,最終會把空洞填上。
mysql> insert into tbx1 values(1);Query OK, 1 row affected (0.01 sec)mysql> show master status;+---------------+----------+--------------+------------------+----------------------------------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+---------------+----------+--------------+------------------+----------------------------------------------+| binlog.000015 | 1416 | | | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10:12 |+---------------+----------+--------------+------------------+----------------------------------------------+1 row in set (0.00 sec)
這意味著嚴格來說我們即不能假設GTID集合是連續的,也不能假定GTID序號大的事務在GTID序號小的事務之後執行,事務的順序應由事務記錄在binlog中的先後順序決定。
GTID相關的信息存儲在binlog文件中,為此MySQL5.6新增了下面2個binlog事件。
示例如下:
mysql> show binlog events IN 'binlog.000015';+---------------+-----+----------------+-----------+-------------+-------------------------------------------------------------------+| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |+---------------+-----+----------------+-----------+-------------+-------------------------------------------------------------------+| binlog.000015 | 4 | Format_desc | 1 | 120 | Server ver: 5.6.31-77.0-log, Binlog ver: 4 || binlog.000015 | 120 | Previous_gtids | 1 | 191 | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-6 || binlog.000015 | 191 | Gtid | 1 | 239 | SET @@SESSION.GTID_NEXT= 'e10c75be-5c1b-11e6-ab7c-000c296078ae:7' || binlog.000015 | 239 | Query | 1 | 318 | BEGIN || binlog.000015 | 318 | Query | 1 | 418 | use `test`; insert into tbx1 values(1) || binlog.000015 | 418 | Xid | 1 | 449 | COMMIT /* xid=13 */ || binlog.000015 | 449 | Gtid | 1 | 497 | SET @@SESSION.GTID_NEXT= 'e10c75be-5c1b-11e6-ab7c-000c296078ae:8' || binlog.000015 | 497 | Query | 1 | 576 | BEGIN || binlog.000015 | 576 | Query | 1 | 676 | use `test`; insert into tbx1 values(1) || binlog.000015 | 676 | Xid | 1 | 707 | COMMIT /* xid=17 */ || binlog.000015 | 707 | Gtid | 1 | 755 | SET @@SESSION.GTID_NEXT= 'e10c75be-5c1b-11e6-ab7c-000c296078ae:9' || binlog.000015 | 755 | Query | 1 | 834 | BEGIN || binlog.000015 | 834 | Query | 1 | 934 | use `test`; insert into tbx1 values(1) || binlog.000015 | 934 | Xid | 1 | 965 | COMMIT /* xid=20 */ |+---------------+-----+----------------+-----------+-------------+-------------------------------------------------------------------+14 rows in set (0.00 sec)
MySQL服務器啟動時,通過讀binlog文件,初始化gtid_executed和gtid_purged,使它們的值能和上次MySQL運行時一致。
由於這兩個重要的變量值記錄在binlog中,所以開啟gtid_mode時必須同時在主庫上開啟log_bin在備庫上開啟log_slave_updates。
但是,在MySQL5.7中沒有這個限制。MySQL5.7中,新增加一個系統表mysql.gtid_executed用於持久化已執行的GTID集合。當主庫上沒有開啟log_bin或在備庫上沒有開啟log_slave_updates時,mysql.gtid_executed會跟用戶事務一起每次更新。否則只在binlog日志發生rotation時更新mysql.gtid_executed。
MySQL服務器的my.cnf配置文件中增加GTID相關的參數
log_bin = /mysql/binlog/mysql_binlog_slave_updates = truegtid_mode = ON enforce_gtid_consistency = true relay_log_info_repository = TABLErelay_log_recovery = ON
然後在Slave上指定MASTER_AUTO_POSITION = 1執行CHANGE MASTER TO即可。比如:
CHANGE MASTER TO MASTER_HOST='node1',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_AUTO_POSITION=1;
在MASTER_AUTO_POSITION = 1的情況下 ,MySQL會使用COM_BINLOG_DUMP_GTID協議進行復制。過程如下:
備庫發起復制連接時,將自己的已接受和已執行的gtids的並集(後面稱為slave_gtid_executed)發送給主庫。即下面的集合:
UNION(@@global.gtid_executed, Retrieved_gtid_set - last_received_GTID)
主庫將自己的gtid_executed與slave_gtid_executed的差集的binlog發送給Slave。主庫的binlog dump過程如下:
從上面的過程可知,在指定MASTER_AUTO_POSITION = 1時,Master發送哪些binlog記錄給Slave,取決於Slave的gtid_executed和Retrieved_Gtid_Set以及Master的gtid_executed,和relay_log_info以及master_log_info中保存的復制位點沒有關系。
在基於GTID的復制拓撲中,要想修復Slave的SQL線程錯誤,過去的SQL_SLAVE_SKIP_COUNTER方式不再適用。需要通過設置gtid_next或gtid_purged完成,當然前提是已經確保主從數據一致,僅僅需要跳過復制錯誤讓復制繼續下去。比如下面的場景:
在從庫上創建表tb1
mysql> set sql_log_bin=0;Query OK, 0 rows affected (0.00 sec)mysql> create table tb1(id int primary key,c1 int);Query OK, 0 rows affected (1.06 sec)mysql> set sql_log_bin=1;Query OK, 0 rows affected (0.00 sec)
在主庫上創建表tb1
mysql> create table tb1(id int primary key,c1 int);Query OK, 0 rows affected (1.06 sec)
由於從庫上這個表已經存在,從庫的復制SQL線程出錯停止。
mysql> show slave status\G*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.125.134 Master_User: sn_repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: binlog.000001 Read_Master_Log_Pos: 1422 Relay_Log_File: mysqld-relay-bin.000003 Relay_Log_Pos: 563 Relay_Master_Log_File: binlog.000001 Slave_IO_Running: Yes Slave_SQL_Running: No Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 1050 Last_Error: Error 'Table 'tb1' already exists' on query. Default database: 'test'. Query: 'create table tb1(id int primary key,c1 int)' Skip_Counter: 0 Exec_Master_Log_Pos: 1257 Relay_Log_Space: 933 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULLMaster_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 1050 Last_SQL_Error: Error 'Table 'tb1' already exists' on query. Default database: 'test'. Query: 'create table tb1(id int primary key,c1 int)' Replicate_Ignore_Server_Ids: Master_Server_Id: 1 Master_UUID: e10c75be-5c1b-11e6-ab7c-000c296078ae Master_Info_File: mysql.slave_master_info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: 161203 15:14:17 Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: e10c75be-5c1b-11e6-ab7c-000c296078ae:5-6 Executed_Gtid_Set: e10c75be-5c1b-11e6-ab7c-000c296078ae:1-5 Auto_Position: 11 row in set (0.00 sec)
從上面的輸出可以知道,從庫已經執行過的事務是'e10c75be-5c1b-11e6-ab7c-000c296078ae:1-5',執行出錯的事務是'e10c75be-5c1b-11e6-ab7c-000c296078ae:6',當前主備的數據其實是一致的,可以通過設置gtid_next跳過這個出錯的事務。
在從庫上執行以下SQL:
mysql> set gtid_next='e10c75be-5c1b-11e6-ab7c-000c296078ae:6';Query OK, 0 rows affected (0.00 sec)mysql> begin;Query OK, 0 rows affected (0.00 sec)mysql> commit;Query OK, 0 rows affected (0.00 sec)mysql> set gtid_next='AUTOMATIC';Query OK, 0 rows affected (0.00 sec)mysql> start slave;Query OK, 0 rows affected (0.02 sec)
設置gtid_next的方法一次只能跳過一個事務,要批量的跳過事務可以通過設置gtid_purged完成。假設下面的場景:
主庫上已執行的事務
mysql> show master status;+---------------+----------+--------------+------------------+-------------------------------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+---------------+----------+--------------+------------------+-------------------------------------------+| binlog.000001 | 2364 | | | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10 |+---------------+----------+--------------+------------------+-------------------------------------------+1 row in set (0.00 sec)
從庫上已執行的事務
mysql> show master status;+---------------+----------+--------------+------------------+------------------------------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+---------------+----------+--------------+------------------+------------------------------------------+| binlog.000001 | 1478 | | | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-6 |+---------------+----------+--------------+------------------+------------------------------------------+1 row in set (0.00 sec)
假設經過修復從庫已經和主庫的數據一致了,但由於復制錯誤Slave的SQL線程依然處於停止狀態。現在可以通過把從庫的gtid_purged設置為和主庫的gtid_executed一樣跳過不一致的GTID使復制繼續下去,步驟如下。
在從庫上執行
mysql> reset master;Query OK, 0 rows affected (0.01 sec)mysql> set GLOBAL gtid_purged='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10';Query OK, 0 rows affected (0.03 sec)mysql> show master status;+---------------+----------+--------------+------------------+-------------------------------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+---------------+----------+--------------+------------------+-------------------------------------------+| binlog.000002 | 191 | | | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10 |+---------------+----------+--------------+------------------+-------------------------------------------+1 row in set (0.00 sec)
此時從庫的Executed_Gtid_Set已經包含了主庫上'1-10'的事務,再開啟復制會從後面的事務開始執行,就不會出錯了。
mysql> start slave;Query OK, 0 rows affected (0.01 sec)
使用gtid_next和gtid_purged修復復制錯誤的前提是,跳過那些事務後仍可以確保主備數據一致。如果做不到,就要考慮pt-table-sync或者拉備份的方式了。
在做備份恢復的時候,有時需要恢復出來的MySQL實例可以作為Slave連上原來的主庫繼續復制,這就要求從備份恢復出來的MySQL實例擁有和數據一致的gtid_executed值。這也是通過設置gtid_purged實現的,下面看下mysqldump做備份的例子。
通過mysqldump做一個全量備份
[root@node1 ~]# mysqldump --all-databases --single-transaction --routines --events --host=127.0.0.1 --port=3306 --user=root > dump.sql
生成的dump.sql文件裡包含了設置gtid_purged的語句
dump.sql:
SET @MYSQLDUMP_TEMP_LOG_BIN = @@SESSION.SQL_LOG_BIN;SET @@SESSION.SQL_LOG_BIN= 0;...SET @@GLOBAL.GTID_PURGED='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10';...SET @@SESSION.SQL_LOG_BIN = @MYSQLDUMP_TEMP_LOG_BIN;
恢復數據前需要先通過reset master清空gtid_executed變量
[root@node2 ~]# mysql -h127.1 -e 'reset master'[root@node2 ~]# mysql -h127.1 <dump.sql
否則執行設置GTID_PURGED的SQL時會報下面的錯誤
ERROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty.
此時恢復出的MySQL實例的GTID_EXECUTED和備份時點一致
mysql> show master status;+---------------+----------+--------------+------------------+-------------------------------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+---------------+----------+--------------+------------------+-------------------------------------------+| binlog.000002 | 191 | | | e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10 |+---------------+----------+--------------+------------------+-------------------------------------------+1 row in set (0.00 sec)
由於恢復出的MySQL實例已經被設置的正確的GTID_EXECUTED,以master_auto_postion = 1的方式CHANGE MASTER到原來的主節點即可開始復制。
CHANGE MASTER TO MASTER_HOST='node1', MASTER_USER='repl', MASTER_PASSWORD='repl', MASTER_AUTO_POSITION = 1
如果不希望備份文件中生成設置GTID_PURGED的SQL,可以給mysqldump傳入--set-gtid-purged=OFF關閉。
相比mysqldump,Xtrabackup是效率更高並且被廣泛使用的備份方式。使用Xtrabackup進行備份的舉例如下。
通過Xtrabackup創一個全量備份(可以在Slave上創建備份,以避免對主庫的性能沖擊)
innobackupex --defaults-file=/etc/my.cnf --host=127.1 --user=root --password=mysql --no-timestamp --safe-slave-backup --slave-info /mysql/bak
應用日志
innobackupex --apply-log /mysql/bak
查看備份目錄中的xtrabackup_binlog_info文件可以找到備份時已經執行過的gtids
[root@node2 ~]# cat /mysql/bak/xtrabackup_binlog_infomysql_bin.000001 191 e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10
由於備份時添加了”--slave-info”選項並且從Slave節點拉取的備份,所以會生成xtrabackup_slave_info文件,也可以從這個文件裡查找建立復制的SQL語句。
[root@node2 ~]# cat /mysql/bak/xtrabackup_slave_infoSET GLOBAL gtid_purged='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10';CHANGE MASTER TO MASTER_AUTO_POSITION=1
將備份文件傳送到新的節點node3的/mysql/bak目錄並恢復(如果直接把備份傳輸到數據目錄了,這一步可以省略)。
[root@node3 ~]# innobackupex --defaults-file=/etc/my.cnf --copy-back /mysql/bak
啟動MySQL。
[root@node3 ~]# mysqld --defaults-file=/home/mysql/etc/my.cnf --skip-slave-start &
如果是從Slave拉的備份,一定不能直接開啟Slave復制,這時的gtid_executed是錯誤的。需要手動設置gtid_purged後再start slave
reset master;SET GLOBAL gtid_purged='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10';CHANGE MASTER TO MASTER_HOST='node1',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_AUTO_POSITION=1;start slave;
MHA是被廣泛使用MySQL HA組件,MHA 0.56以後支持基於GTID的復制。 MHA在failover時會自動判斷是否是GTID based failover,需要滿足下面3個條件即為GTID based failover
和之前的基於binlog文件位置的復制相比,基於GTID復制下,MHA在故障切換時的變化主要如下:
基於binlog文件位置的復制
基於GTID的復制
在GTID模式下MHA不會嘗試從舊Master上拷貝binlog日志進行補償,所以在MySQL進程crash而OS仍然健康的情況下,應盡量不要做主備切換而是原地重啟MySQL,除非有其它能確保切換後不丟數據的措施。
在GTID模式下MHA支持在復制拓撲中增加一個或多個binlog server起到日志補償的作用,非GTID模式下即使配置了binlog server也會被MHA忽略。
日志補償可以說是MHA中最復雜也最精華的部分,有了GTID後故障切換變得更簡單了,不再需要原本復雜的binlog日志解析和補償。所以Oracle官方推出了只支持GTID復制的切換工具mysqlfailover,在GTID的幫助下,我們有更多靠譜的HA工具可以選擇。
crash safe slave是MySQL 5.6提供的功能,意思是說在slave crash後,把slave重新拉起來可以繼續從Master進行復制,不會出現復制錯誤也不會出現數據不一致。
在基於binlog文件位置的復制下,要保證crash safe slave,配置下面的參數即可。
relay_log_info_repository = TABLErelay_log_recovery = ON
這樣可行的原因是,relay_log_info_repository = TABLE時,apply event和更新relay_log_info表的操作被包含在同一個事務裡,innodb要麼讓它們同時生效,要麼同時不生效,保證位點信息和已經應用的事務精確匹配。同時relay_log_recovery = ON時,會拋棄master_log_info中記錄的復制位點,根據relay_log_info的執行位置重新從Master獲取binlog,這就回避了由於未同步刷盤導致的binlog文件接受位置和實際不一致以及relay log文件被截斷的問題。
在同時使用MTS(multi-threaded slave)時,為保證crash safe slave基於binlog文件位置的復制還需要設置sync_relay_log=1,因為MySQL在Crash恢復時必須先通過讀取relay log補齊MTS導致的事務空洞。
上面的設置並不適用於基於GTID的復制。在基於GTID的復制下,crash的Slave重啟後,從binlog中解析的gtid_executed決定了要apply哪些binlog記錄,所以binlog必須和innodb存儲引擎的數據保持一致。要做到這一點,需要把sync_binlog和innodb_flush_log_at_trx_commit都設置為1,即所謂的"雙1"。
另外mysql啟動時,會從relay log文件中獲取已接收的GTIDs並更新Retrieved_Gtid_Set。由於relay log文件可能不完整,所以需要拋棄已接收的relay log文件。因此relay_log_recovery = ON也是必須的。
這樣,對於基於GTID的復制,保證crash safe slave的設置就是下面這樣。
sync_binlog = 1innodb_flush_log_at_trx_commit = 1relay_log_recovery = ON
關於如何設置以確保crash safe slave,官方文檔有明確記載,見17.3.2 Handling an Unexpected Halt of a Replication Slave。
但是其中關於GTID的記載中存在筆誤,將relay_log_recovery=1寫成了relay_log_recovery=0(#83711)。同時也沒有提到必須設置"雙1",但是"雙1"是必要的,否則crash的Slave重啟後,可能會重復應用binlog event也可能會遺漏應用binlog event(#70659)。其中遺漏應用binlog event的情況更可怕,因為Slave在不觸發SQL錯誤的情況下就默默的和Master不一致了。
出於安全考慮,強烈推薦設置"雙1"。"雙1"會增大每個事務的RT,但得益於MySQL的組提交機制,高並發下"雙1"對系統整體tps的影響在可接受范圍內。
sysbencholtp.lua10張表每張表100w記錄(qps/並發數)
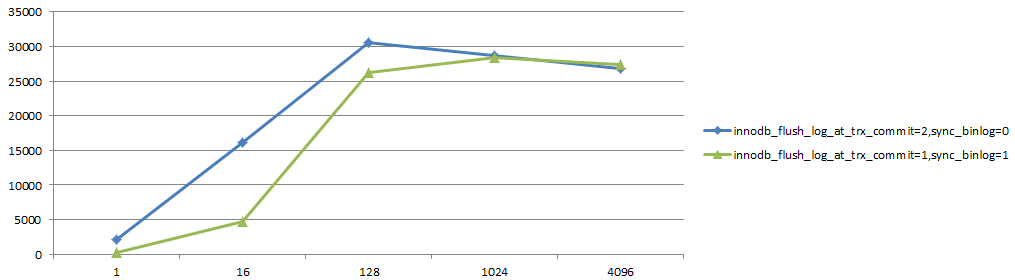
對更新同一行這樣無法有效並行的場景,"雙1"對性能的影響非常大。
sysbenchupdate_non_index.lua1張表1條記錄(qps/並發數)
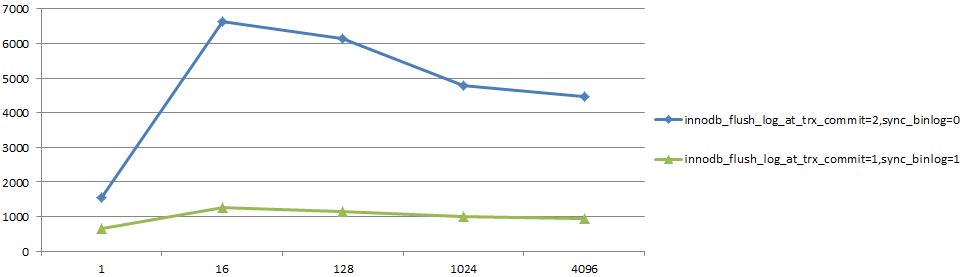
對不能有效並行的Slave replay,存在同樣的問題。
通過指定tx-rate執行sysbench的update_non_index.lua腳本壓測30秒,完成後檢查主備延遲。
可以發現在Slave被配置為"雙1"的情況下,延遲非常嚴重,1000以上的qps就會出現延遲,非"雙1"下qps到5000以上才會出現延遲(主庫配置為"雙1")。
sysbenchupdate_non_index.lua1張表100w條記錄 128並發(延遲/qps)
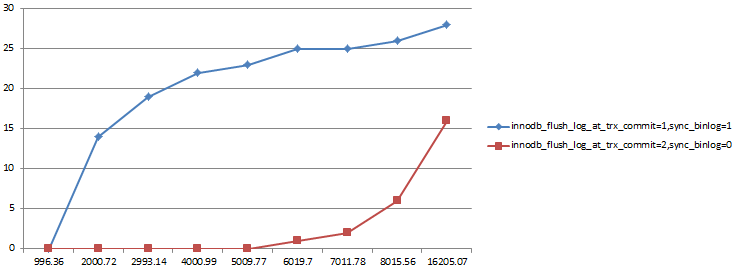
以上測試環境是Percona Server 5.6運行在配置HDD的8 core虛機,由於測試結果和系統IO能力有很大關系,僅供參考。
如果是MySQL 5.7可以關閉log_slave_updates,這樣MySQL會將已執行的GTIDs實時記錄到系統表mysql.gtid_executed中,mysql.gtid_executed是和用戶事務一起提交的,因此可以保證和實際的數據一致。
log_slave_updates = OFFrelay_log_recovery = ON
如果是MySQL 5.6可以采用如下變通的方式。
按照基於binlog文件復制時crash safe slave的要求設置relay_log_info_repository = TABLE
relay_log_info_repository = TABLErelay_log_recovery = ON
在Slave crash後,根據relay_log_info_repository設置相應的gitd_purged再開啟復制,步驟如下。
啟動mysql,但不開啟復制
mysqld --skip-slave-start
在Slave上修改為基於binlog文件位置的復制
change master to MASTER_AUTO_POSITION = 0
啟動slave IO線程
start slave io_thread
這裡不能啟動SQL線程,如果接受到的GTID已經在Slave的gtid_executed裡了,會被Slave skip掉。
檢查binlog傳輸的開始位置(即Retrieved_Gtid_Set的值)
show slave status\G
假設輸出的Retrieved_Gtid_Set值為e10c75be-5c1b-11e6-ab7c-000c296078ae:7-10
在Master上檢查gtid_executed
show master status
假設輸出的Executed_Gtid_Set值為e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10
在Slave上設置gitd_purged為binlog傳輸位置的前面的GTID的集合
reset master;set global gitd_purged='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-6';
修改回auto position的復制
change master to MASTER_AUTO_POSITION = 1
啟動slave SQL線程
start slave sql_thread
但是,這種變通的方法不適合多線程復制。因為多線程復制可能產生gtid gap和Gap-free low-watermark position,這會導致Salve上重復apply已經apply過的event。後果就是數據不一致或者復制中斷,除非設置binlog格式為row模式並且slave_exec_mode=IDEMPOTENT,slave_exec_mode=IDEMPOTENT允許Slave回放binlog時忽略重復鍵和找不到鍵的錯誤,使得binlog回放具有冪等性,但這也意味著如果真的出現了主備數據不一致也會被它忽略。
在同時使用MTS(slave_parallel_workers> 1)時,即使按上面crash safe slave的要求設置了基於GTID的復制,Slave crash後再重啟還是會導致復制中斷。
通過強制殺掉MySQL所在虛機的方式模擬Slave宕機,然後再啟動MySQL,mysql日志中有如下錯誤消息:
---------------------------------2016-10-26 21:00:23 2699 [Warning] Neither --relay-log nor --relay-log-index were used; so replication may break when this MySQL server acts as a slave and has his hostname changed!! Please use '--relay-log=mysql-relay-bin' to avoid this problem.2016-10-26 21:00:24 2699 [Note] Slave: MTS group recovery relay log info based on Worker-Id 1, group_relay_log_name ./mysql-relay-bin.000011, group_relay_log_pos 2017523 group_master_log_name binlog.000007, group_master_log_pos 20173632016-10-26 21:00:24 2699 [ERROR] Error looking for file after ./mysql-relay-bin.000012.2016-10-26 21:00:24 2699 [ERROR] Failed to initialize the master info structure2016-10-26 21:00:24 2699 [Note] Check error log for additional messages. You will not be able to start replication until the issue is resolved and the server restarted.2016-10-26 21:00:24 2699 [Note] Event Scheduler: Loaded 0 events2016-10-26 21:00:24 2699 [Note] mysqld: ready for connections.Version: '5.6.31-77.0-log' socket: '/data/mysql/mysql.sock' port: 3306 Percona Server (GPL), Release 77.0, Revision 5c1061c---------------------------------
啟動slave時也會報錯
mysql> start slave;ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
出現這種現象的原因在於,relay_log_recovery=1且slave_parallel_workers>1的情況下,mysql啟動時會進入MTS Group恢復流程,即讀取relay log,嘗試填補由於多線程復制導致的gap。然後relay log文件由於不是實時刷新的,在relay log文件中找不到gap對應的relay log記錄(覆蓋了gap的relay log起始和結束位置分別被稱為低水位和高水位,低水位點即slave_relay_log_info.Relay_log_pos的值)就會報這個錯。
實際上,在GTID模式下,slave在apply event的時候可以跳過重復事件,所以可以安全的從低水位點應用日志,沒必要解析relay log文件。 這看上去是一個bug,於是提交了一個bug報告#83713,目前還沒有收到回復。
作為回避方法,可以通過清除relay log文件,跳過這個錯誤。執行步驟如下
reset slave;change master to MASTER_AUTO_POSITION = 1start slave;
在這裡,單純的調reset slave不能把狀態清理干淨,內部的Relay_log_info.inited標志位仍然處於未被初始化狀態,此時調用start slave仍然會失敗。因此需要補一刀change master。
前面一直在講crash safe slave,Master的crash safe同樣重要。 要想Master保持crash safe需要按下面的參數進行設置,否則不僅會丟失事務,gtid_executed還可能和實際的innodb存儲引擎中的數據不一致。
sync_binlog = 1innodb_flush_log_at_trx_commit = 1
在Master配置為"雙1"的情況下,Master crash後,如果沒有發生failover,可以繼續作為Master。 如果發生了failover,可以檢查舊Master和新Master上由舊Master執行的事務集合是否一致。
show master status
如果一致,可以按MASTER_AUTO_POSITION = 1的方式將舊Master作為Slave和新Master建立復制關系。否則,考慮做事務補償或從新Master上拉取備份進行恢復。
在Master配置不是"雙1"的情況下,在Master crash後由於難以准確知道舊Master上究竟執行了哪些事務,安全的做法是實施主備切換,並從新Master上拉取備份,把舊Master作為新Master的Slave進行恢復。
 Android黑科技,讀取用戶短信+修改系統短信數據庫,
Android黑科技,讀取用戶短信+修改系統短信數據庫,
Android黑科技,讀取用戶短信+修改系統短信數據庫, 安卓系統比起ios系統最大的缺點,相信大家都知道,就是系統安全問題。這篇博客就秀一波&ldquo
 [android] 天氣app布局練習,androidapp
[android] 天氣app布局練習,androidapp
[android] 天氣app布局練習,androidapp主要練習一下RelativeLayout和LinearLayout <RelativeLayout
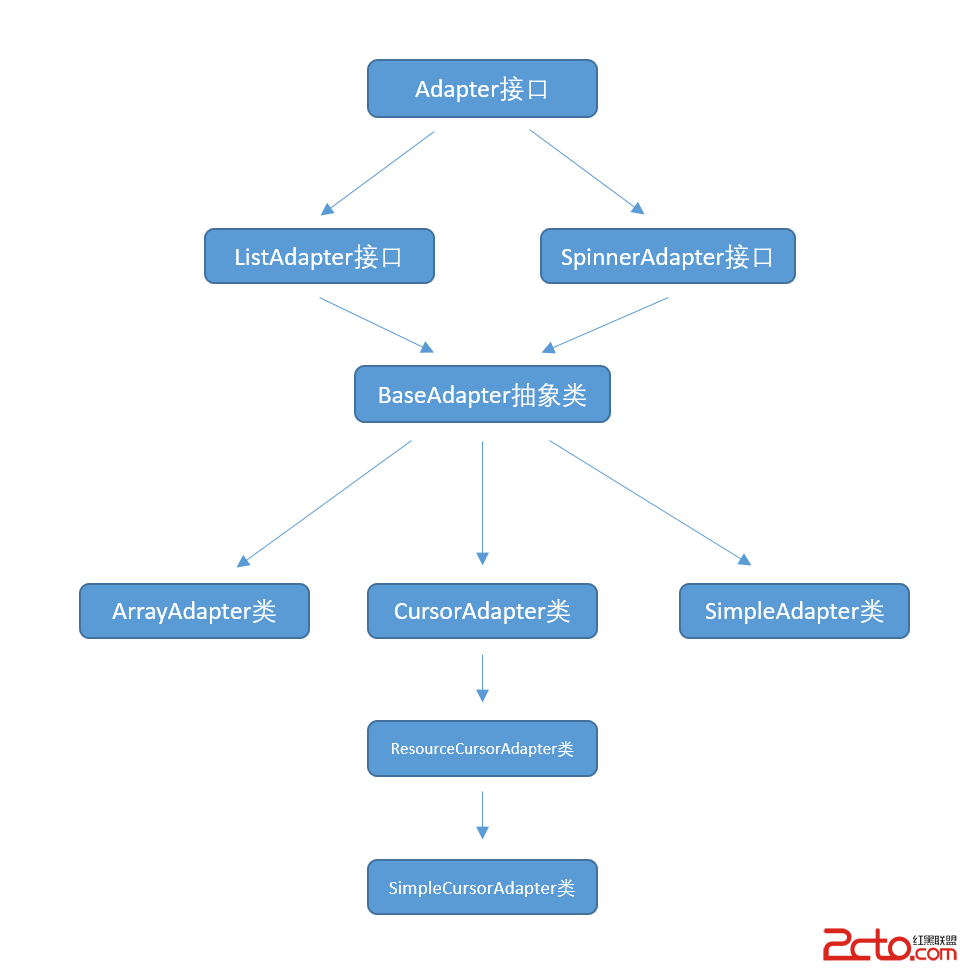 使用數據源碼解析Android中的Adapter、BaseAdapter、ArrayAdapter、SimpleAdapter和SimpleCursorAdapter
使用數據源碼解析Android中的Adapter、BaseAdapter、ArrayAdapter、SimpleAdapter和SimpleCursorAdapter
使用數據源碼解析Android中的Adapter、BaseAdapter、ArrayAdapter、SimpleAdapter和SimpleCursorAdapter
 Android NDK開發Hello Word!,androidndk
Android NDK開發Hello Word!,androidndk
Android NDK開發Hello Word!,androidndk 在之前的博客中已經為大家介紹了,如何在win環境下配置DNK程序,本篇我將帶大家實現一個簡單的H