編輯:關於android開發
查看原文:http://blog.csdn.net/u010818425/article/details/52490628
Gradle實戰系列文章:
《Gradle基本知識點與常用配置》
《Gradle實戰:Android多渠道打包方案匯總》
《Gradle實戰:不同編譯類型的包同設備共存》
《Gradle實戰:發布aar包到maven倉庫》
本文將介紹使用
groovy+sql的腳本,實現從hive抓取數據,為方便理解,重要語句有詳細注釋,關鍵處已標明“關鍵點”;在閱讀本文過程中,如對groovy還不是很熟悉的讀者可以查看《 Gradle基本知識點與常用配置》這篇文章
Gradle簡單操作mysql數據庫
import groovy.sql.Sql
class GroovySqlExample1{
static void main(args) {
sql = Sql.newInstance("jdbc:mysql://localhost:3306/tablename", "account", "password", "org.gjt.mm.mysql.Driver")
sql.eachRow("select * from tablename"){
row | println row.word_id + " " + row.spelling + " " + row.part_of_speech
//“row”表示查詢到的每一行數據,“row.word_id”表示“word_id”這個字段的值
}
}
}這是一個使用Gradle操作mysql數據庫的入門例子,配置好數據庫地址、驅動、賬號、密碼就可以執行sql語句操作數據庫了,但是現在越來越多的公司都轉向使用分布式存儲,以下我們來詳細介紹一下Gradle操作hive數據庫的實例(當然,你需要有這樣一個數據庫環境)。
以獲取udid(設備唯一識別碼)為例,條件是:1、近兩周內打開過我們app(即我們後台系統有其訪問記錄),我們認為這些是活躍用戶;2、滿足條件1的各城市用戶中,各取20%的用戶。以下分為5各部分來講述我們的實現方案:sql腳本、配置文件、groovy代碼、使用方法、數據產出。
首先,新建一個android工程,無需任何java代碼;然後在module中新建一個名為“getUdid.sql“的文件,裡面存放的就是我們用於查詢數據庫的sql腳本;但這個腳本還可以通過gradle運行過程中動態拼接一些參數,下文會有介紹。
SELECT count(DISTINCT udid) AS allCount FROM tablename WHERE dt>=date_sub(current_date,14);
SELECT DISTINCT udid FROM tablename WHERE dt>=date_sub(current_date,14)再在module中新建一個名為“hive.properties“的配置文件,用於存放連接數據庫所需的相關參數。
HiveUrl=jdbc:hive2://host:port/basename?useUnicode=true&characterEncoding=utf8
Account=xxx
Password=xxx
Driver=org.apache.hive.jdbc.HiveDriver //連接hive所用的驅動注:上述的HiveUrl中,scheme使用的是
hive2,因此與其配套的驅動是org.apache.hive.jdbc.HiveDriver,如果使用的是早期的hive,則scheme是hive,其配套的驅動是org.apache.hadoop.hive.jdbc.HiveDriver
import groovy.sql.Sql //關鍵點1
apply plugin: 'java'
apply plugin: 'groovy'
apply plugin: 'maven'
repositories {
mavenCentral()
}
configurations {
driver //關鍵點2
}
dependencies {
driver 'org.apache.hive:hive-jdbc:2.1.0' //數據庫連接驅動依賴,關鍵點3
}
//數據庫連接驅動下載,關鍵點4
URLClassLoader loader = GroovyObject.class.classLoader
configurations.driver.each { File file ->
loader.addURL(file.toURL())
}
task run << {
def File propFile = new File('hive.properties') //“hive.properties”為自定義的配置文件,上文有介紹
if (propFile.canRead()) {
def Properties props = new Properties()
props.load(new FileInputStream(propFile))
if (props != null && props.containsKey('HiveUrl') && props.containsKey('Account')
&& props.containsKey('Password') && props.containsKey('Driver')) {
//從配置文件中讀取各參數
String hiveUrl = props['HiveUrl']//數據庫地址
String account = props['Account']//訪問數據庫的賬號
String password = props['Password']//密碼
String driver = props['Driver'] //連接數據庫的驅動類名
String os = System.properties['os'] //讀取命令行設置的手機系統類型(設置見下文“使用方法”中的命令行)
String ver = System.properties['ver']//讀取命令行設置的app版本號(設置見下文“使用方法”中的命令行)
def sql = Sql.newInstance(hiveUrl, account, password, driver)//建立數據庫連接,關鍵點5
String udidName = "udid_" //存放udid的文件名
String summaryName = "summary_" //存放各城市概況的文件名
if (os.equals("Android")) {
udidName += "android.txt"
summaryName += "android.txt"
} else {
udidName += "ios.txt"
summaryName += "ios.txt"
}
String dirPath = getRootDir().toString() + '/result/' //結果存放路徑
def dir = new File(dirPath)
if (!dir.exists()) {
dir.mkdirs()
}
String udidPath = dirPath + '/' + udidName //udid文件路徑
String summaryPath = dirPath + '/' + summaryName //各城市概況文件路徑
def udidFile = new File(udidPath)
def summaryFile = new File(summaryPath)
if (udidFile.exists()) {
udidFile.delete()
}
udidFile.createNewFile()
if (summaryFile.exists()) {
summaryFile.delete()
}
summaryFile.createNewFile()
def resultPrintWriter = udidFile.newPrintWriter()
def summaryPrintWriter = summaryFile.newPrintWriter()
//制表
summaryPrintWriter.write('\n')
summaryPrintWriter.write(os + "用戶情況")
summaryPrintWriter.write('\n')
summaryPrintWriter.write('-------------------')
summaryPrintWriter.write('\n')
summaryPrintWriter.write(" 城市" + " 總數" + " 抽取")
summaryPrintWriter.write('\n')
summaryPrintWriter.write('-------------------')
summaryPrintWriter.write('\n')
def citys = ['北京市', '上海市', '廣州市', '深圳市']
int allcount = 0 // 活躍用戶總數
int allExtracted = 0 // 抽取20%的用戶數
try {
//各個城市遍歷
citys.each {
city ->
resultPrintWriter.write(city + ':')
resultPrintWriter.write('\n')
resultPrintWriter.write('--------------------------------------')
resultPrintWriter.write('\n')
boolean isGetCount = true
int num = 0
// 讀取sql腳本,每句以分號分隔,下方還需動態拼接參數
new File('getUdid.sql').text.split(";").each { //“getUdid.sql”裡面為查詢udid的sql語句,下文有介紹
sqlTemp ->
//動態拼接參數
String sqlString = sqlTemp +
' AND city=' + "'" + city + "'" +
' AND os=' + "'" + os + "'" +
' AND ver=' + "'" + ver + "'"
if (isGetCount) { // 執行第一句sql,獲取該城市總活躍用戶中的20%
println sqlString
sql.eachRow(sqlString) { // 執行sql,關鍵點6
num = it.allcount * 0.2 // 總數的20%
allcount += it.allcount
allExtracted += num
//制表
summaryPrintWriter.write(city + " " + it.allcount + getCount(it.allcount) + num)
summaryPrintWriter.write('\n')
summaryPrintWriter.write('-------------------')
summaryPrintWriter.write('\n')
}
isGetCount = false
} else { // 執行第二句sql,獲取該城市總活躍用戶數前20%的udid
sqlString = sqlString + " LIMIT " + num // 取前num個數據,動態拼接條件
println sqlString
sql.eachRow(sqlString) { // 執行sql
if (it.udid != null && it.udid != '') {
resultPrintWriter.write(it.udid + ",")
resultPrintWriter.write('\n')
}
}
}
}
resultPrintWriter.write('--------------------------------------')
resultPrintWriter.write('\n')
}
//制表
summaryPrintWriter.write(" 累計 " + " " + allcount + getCount(allcount) + " " + allExtracted)
summaryPrintWriter.write('\n')
summaryPrintWriter.write('-------------------')
summaryPrintWriter.write('\n')
summaryPrintWriter.write("統計日期:" + releaseTime())
summaryPrintWriter.write('\n')
} catch (Exception e) {
println e.message
}
//關閉打印
resultPrintWriter.flush()
summaryPrintWriter.flush()
resultPrintWriter.close()
summaryPrintWriter.close()
}
}
}
//獲取系統時間
def releaseTime() {
return new Date().format("yyyy-MM-dd", TimeZone.getTimeZone("UTC"))
}
//模擬制表符,用於summary文件裡面制作表格
String getCount(i) {
int temp = i
int count = 0
while (temp > 0) {
temp = temp / 10
count++
}
String space = ''
if (count == 1) {
space = " "
} else if (count == 2) {
space = " "
} else if (count == 3) {
space = " "
} else if (count == 4) {
space = " "
}
return space
}本地需安裝Gradle且配置環境變量;然後打開終端,按以下步驟輸入命令(第一次執行會下載hive數據庫驅動,耗時較長):
進入到工程目錄下(假設module名為executeSql):
cd executeSql抓取android數據:
gradle run -Dos='Android' -Dver='1.0.0'抓取iOS數據:
gradle run -Dos='iPhone OS' -Dver='2.0.0'注:上述命令中,
“-D”表示設置參數,在groovy代碼中有接收參數的語句String os = System.properties['os']
以android為例,開始執行後,每個城市都會執行以下兩句sql,即上述gradle腳本動態拼接成的sql:
SELECT count(DISTINCT udid) AS allCount FROM tablename WHERE dt>=date_sub(current_date,14) AND city='北京市' AND os='Android' AND ver='1.0.0';
SELECT DISTINCT udid FROM tablename WHERE dt>=date_sub(current_date,14) AND city='北京市' AND os='Android' AND ver='1.1.0' LIMIT 2000數據產出為兩個文件,一個是各城市用戶的總體情況,另一個是各城市用戶z紅20%的udid數據列表;
各城市用戶情況,summary_android.txt
Android用戶情況
-------------------
城市 總數 抽取
-------------------
北京市 10000 2000
-------------------
上海市 20000 4000
-------------------
廣州市 30000 6000
-------------------
深圳市 40000 8000
-------------------
累計 100000 20000
-------------------
統計日期:2016-09-09
各城市udid,udid_summary.txt(僅作示意)
北京市:
--------------------------------------
00123456-2c9c-4ab7-a256-4b86a2490318,
00234567-f9fb-4059-a1b8-49514fb17ac0,
...
--------------------------------------
上海市:
--------------------------------------
00345678-4910-4db5-b82c-42f85450c85c,
00456789-1047-470c-9bf2-af326fdac7f1,
...
--------------------------------------
廣州市:
--------------------------------------
01234567-d69f-40fa-aabd-88ac19f542cf,
02345678-b1c2-4005-a418-f6d1704b7f81,
...
--------------------------------------
深圳市:
--------------------------------------
03456789-0413-4cd1-9214-8544a07eecec,
04567891-4ac2-49cd-a1c8-f49c5edd9d9b,
...
--------------------------------------
查看原文:http://blog.csdn.net/u010818425/article/details/52490628
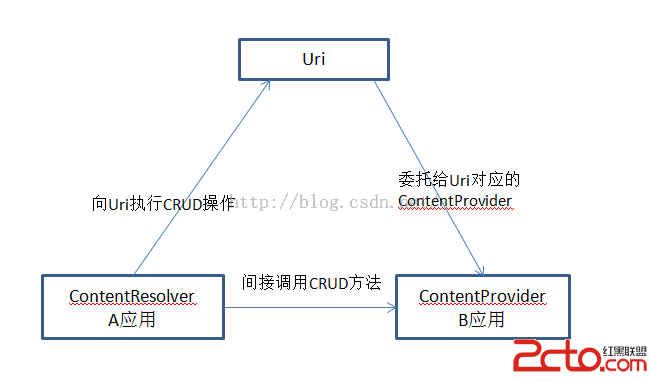 Android中ContentProvider組件數據共享
Android中ContentProvider組件數據共享
Android中ContentProvider組件數據共享 ContentProvider的功能和意義: 主要用於對外共享數據,也就是通過ContentProvide
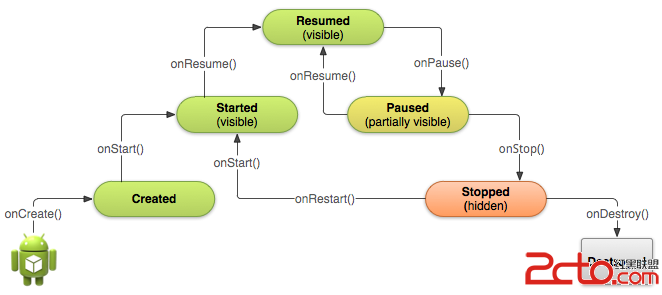 Android官方文檔翻譯 十七 4.1Starting an Activity
Android官方文檔翻譯 十七 4.1Starting an Activity
Android官方文檔翻譯 十七 4.1Starting an Activity Starting an Activity 開啟一個Activity This les
 《循序漸進Linux》第二版即將出版發行(附封面)
《循序漸進Linux》第二版即將出版發行(附封面)
《循序漸進Linux》第二版即將出版發行(附封面)從《循序漸進Linux》第一版發布,到現在已經近6年了,6年的時間,技術發生了很大的變化,Linux系統的內核版本從2.
 box-flex 彈性可伸縮盒模型
box-flex 彈性可伸縮盒模型
box-flex 彈性可伸縮盒模型 之前一直針對於PC端開發,自適應方面接觸甚少,一般來說用些的 css 方法就直接解決一些設計問題,直到目前現狀開始轉變為純移動端開