編輯:關於android開發
2016.4.11日廣州天河區東圃喜來登酒店參加了Tencent CC++後台技術一面,面試官人很溫和,經歷了大概70分鐘的問答,特將遇到的面試問題匯總如下,自己總結學習,亦供網友參考。
問題一:
不好意思,我有事,先處理一下,你先寫個非遞歸二分查找。
答:
這個和上次CVTE面試的第一個問題相同,之前復習過。感覺很多面試的第一個問題都是先寫段代碼。因此,手寫代碼感覺很重要,因為這是給面試官的第一印象。除了二分查找,快排,鏈表反轉,實現atoi()函數等等,在面試中也常被用來作為手寫代碼的考題。
//數組遞增有序 int binarySearch(int* array,int len,int value){ int mid=0; int low=0; int high=len-1; while(low<=high){ mid=(low+high)/2; if(array[mid]==value) //找到 return mid; if(value>array[mid]) //在右半區 low=mid+1; else //在左半區 high=mid-1; } return -1; //查找失敗 }問題二:
(面試官一直在打電話)如果你寫完了,你再寫一個從數組中找出第二大的數。
答:
找第幾大的數突然間想到了堆排序,因為自己之前練習過堆排序,所以就花了十分鐘左右的時間寫下了堆排序。寫堆排序需要知道節點下標index的左子節點的下標為2*index+1,2*index+2。以數組構造堆的話是一個完全二叉樹,數組長度為len,那麼最後一個非葉子節點的下標是len/2-1。以堆排序來尋找第二大數參考代碼如下:
//手寫大頂堆排序求大二大數 void adjust(int A[],int index,int len){ if(index>len/2-1)//葉子節點,不同調整 return; int biggestIndex=0; if(2*index+2A[2*index+2]?2*index+1:2*index+2; else biggestIndex=2*index+1; if(A[index]index]=A[index]+A[biggestIndex]; A[biggestIndex]=A[index]-A[biggestIndex]; A[index]=A[index]-A[biggestIndex]; adjust(A,biggestIndex,len); }} void createMaxHeap(int A[],int len){ for(int i=len/2-1;i>=0;--i){ adjust(A,i,len); } } int getSecondMax(int A[],int len){ createMaxHeap(A,len); //建堆 for(int i=0;i<2;++i){ A[0]=A[0]+A[len-1-i]; A[len-1-i]=A[0]-A[len-1-i]; A[0]=A[0]-A[len-1-i]; adjust(A,0,len-1-i); } return A[len-2];}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
很顯然,這個求解方法的時間復雜度是nlogn,不是較優解法,不是面試官想要的答案。面試官追問有沒有更好的方法,時間復雜度是O(n)。
稍微想了一下,回答冒泡排序和簡單選擇排序可以在O(2n)的時間復雜度找到第二大的數。他試官說還有沒有更快的方法呢?不要O(2n),只要O(n)。
正確答案是:
保存最大值和第二大值,掃描一遍數組即可找到,也就是以空間換時間。冒泡排序和簡單選擇排序都需要掃描兩遍。參考如下代碼:
int getSecondMax(int array[],int len){ if(len<=1) return -1; int max=0,secondMax=0; if(array[0]>array[1]){ max=array[0]; secondMax=array[1]; }else{ max=array[1]; secondMax=array[0]; } for(int i=2;isecondMax) //新的第二大數 secondMax=array[i]; else max=array[i]; //最大數 } return secondMax;}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
問題三:
C++中struct和class的區別?
答:
(1)關於繼承和訪問權限,struct默認的繼承訪問權限為public,class為private;
(2)關於大括號初始化,C++中的struct是對C中的struct的擴充,同時兼容C中struct應有的大括號初始化特性。
class和struct如果定義了構造函數的話,都不能用大括號進行初始化;
如果沒有定義構造函數,struct可以用大括號初始化;
如果沒有定義構造函數,且所有成員變量全是public的話,可以用大括號初始化。
事實上,這個區別是由上面的區別造成的,所以這個可以不算一個區別。
(3)關於模版,在模版中,類型參數前面可以使用class或typename,不能使用struct。
問題四:
說說C++多態的實現機制。
答:
簡單來說,就是通過虛函數表來實現的,具體請參考:CVTE面試問題匯總.
問題五:
C中static關鍵字的作用。
答:
(1)修飾變量,一是表名變量存儲空間在全局靜態存儲區,二是變量生命周期是真個程序的生命周期,三是變量作用域限定在當前文件。
(2)修飾函數,限制函數的作用域為當前文件。
問題五:
C中extern關鍵字的作用。
答:
extern修飾變量和函數起到聲明的作用,以表示變量或者函數的定義在別的文件中,提示編譯器遇到此變量和函數時在其他文件中尋找其定義。
問題六:
C++中extern "C"的作用。
答:
C++中extern "C"修飾函數時,指明該函數以C的方式進行編譯和鏈接。具體來說就是C++函數支持函數重載,C不支持函數重載,原因二者的函數簽名不同。
如函數void foo(int,int)被C編譯器編譯後在符號庫中的名字為_foo,而C++編譯器則會產生像_foo_int_int之類的名字(不同的編譯器可能生成的名字不同,但是都采用了相同的機制,生成的新名字稱為”mangledname”)。
問題七:
說一下CC++程序的內存布局。
答:
目前我還沒有找到很權威的著作對此問題有詳細的論述,肯定有,只是我還不知道。看了《C++高級進階教程》中描述如下。
如果內存地址由下到上的是從低地址到高地址,那麼程序的內存布局大致如下:
問題七:
僵屍進程是如何產生的。
答:
在UNIX 系統中,一個進程結束了,但是他的父進程沒有等待(調用wait / waitpid)他, 那麼他將變成一個僵屍進程。
問題八:
僵屍進程如何避免。
答:
(1)父進程通過wait和waitpid等函數等待子進程結束,但這會導致父進程掛起。
(2)如果父進程很忙,那麼可以用signal函數為SIGCHLD安裝handler,因為子進程結束後, 父進程會收到該信號,可以在handler中調用wait回收。
(3)如果父進程不關心子進程什麼時候結束,那麼可以用signal(SIGCHLD,SIG_IGN)通知內核,自己對子進程的結束不感興趣,那麼子進程結束後,內核會回收, 並不再給父進程發送信號。
(4)還有一些技巧,就是fork兩次,父進程fork一個子進程,然後繼續工作,子進程fork一 個孫進程後退出,那麼孫進程被init接管,孫進程結束後,init會回收。不過子進程的回收 還要自己做。
問題九:
寫一個宏,給定數組名求數組長度,數組類型未知。
答:
想到sizeof就可以很容易求出來了。思路是先用sizeof(array)求出數組占用的內存空間大小(單位字節),再通過sizeof求出數組單個元素的類型大小(單位字節),前者除以後者即可。
#define func(array) sizeof(array)/sizeof(array[0])
問題十:
Linux下awk和sed了解過吧,給定一個文本文件,編寫shell腳本將文件中重復的行刪除。
答:
使用sort+uniq/awk/sed可以來完成。
方法一:利用sort以不重復的方式打印出文件所有的行並排序-u,表示unique。
sort -u file
方法二:利用sort先對文件按行排好序之後再交由uniq處理。sort -k 指定列,-t指定列分隔符。
sort -k 1 -t ':' file|uniq
方法三:利用sort+awk來完成。
sort file | awk '{if ($0!=line) print;line=$0}'if ($0!=line) print;表示當前行是否等於上一行,不等於的話則打印,line開始是空的。line=$0表示當前行賦給line。
方法四:利用sort+sed來完成。
sort file | sed '$!N; /^\(.*\)\n\1$/!P;D'
稍後解釋。
問題十一:
有用過Linux中的epoll嗎?它的作用是什麼?
答:
epoll是Linux內核為處理大批量文件描述符而作了改進的poll,是Linux下多路復用IO接口select/poll的增強版本,它能顯著提高程序在大量並發連接中只有少量活躍的情況下的系統CPU利用率。
問題十二:
epoll和select的區別在哪,或者說優勢在哪?
答:
(1)epoll除了提供select/poll那種IO事件的水平觸發(Level Triggered)外,還提供了邊緣觸發(Edge Triggered);
(2)select的句柄數目受限,在linux/posix_types.h頭文件有這樣的聲明:#define __FD_SETSIZE 1024,表示select最多同時監聽1024個fd。而epoll沒有,epoll的最大並發的連接數的理論值無上限,但由於實際內存資源有限,實際並發的連接數受到資源的限制和最大的打開文件句柄數目的限制;
(3)epoll的最大好處是不會隨著FD的數目增長而降低效率,在selec中采用輪詢處理,其中的數據結構類似一個數組的數據結構,而epoll 是維護一個隊列,直接看隊列是不是空就可以了。
(4)使用mmap加速內核與用戶空間的消息傳遞。無論是select,poll還是epoll都需要內核把FD消息通知給用戶空間,如何避免不必要的內存拷貝就很重要,在這點上,epoll是通過內核於用戶空間mmap同一塊內存實現的。
此外,epoll創建時傳入的參數是什麼?
創建一個epoll的實例,size用來告訴內核這個監聽的數目一共有多大。這個參數不同於select()中的第一個參數,給出最大監聽的fd+1的值。需要注意的是,當創建好epoll句柄後,它就是會占用一個fd值,在linux下如果查看/proc/進程id/fd/,是能夠看到這個fd的,所以在使用完epoll後,必須調用close()關閉,否則可能導致fd被耗盡。
問題十三:
給定數據表table1如下,編寫SQL語句找出出現次數前三的年齡。
答:
在MS Access中測試跑通,參考語句如下:
select top 3 table2.Age,table2.num from (select Age,count(Age) as num from table1 group by Age) as table2 Order By table2.num DESC
問題十四:
網絡的五層協議模型。
答:
很簡單,如下圖所示:
問題十五:
咱們聊一下架構的事情。如果你現在是一位架構師,如何實現QQ的大量用戶並發登陸,應該考慮哪些問題?又該如何解決?
答:
(1)傳輸協議選擇。
(2)負載均衡。
(3)線程和進程的選擇,以及優化。
問題十六:
你了解過數據挖掘嗎。對這方面感興趣嗎?
答:
沒了解過但很感興趣。
問題十七:
你還有什麼問題要問的。
答:
請問您搞安全技術方面需要對數據庫和SQL掌握很精通嗎?
面試官:無需精通,但是要有良好的基礎,常用的SQL要會寫。
面試官也是比較溫和的人,很有耐心,整個過程節奏也很緩慢。不會的問題盡量去思考,面試官希望看到面試者的思考過程,不懂的我也向他請教,尋求提示,這也間接的產生了互動。
整個面試過程所遇到的問題,除了最後一個是比較開發的題目,前面都是比較基礎的題目。之所以問這些問題,還是就個人簡歷中提到的求職技能和相關項目進行相關問題提問。在SQL和shell腳本方面,因為很多年沒寫SQL了,所以基本忘記,shell腳本,盡管平時在Linux環境編程,但是很少寫,寫的話也是參考網上資源,一時無任何參考手寫確實有些不適,看來SQL和shell這方面要加強了。
 計時器(Chronometer)的使用,計時器chronometer
計時器(Chronometer)的使用,計時器chronometer
計時器(Chronometer)的使用,計時器chronometer安卓提供了一個計時器組件:Chronometer,該組件extends TextView,因此都會顯示
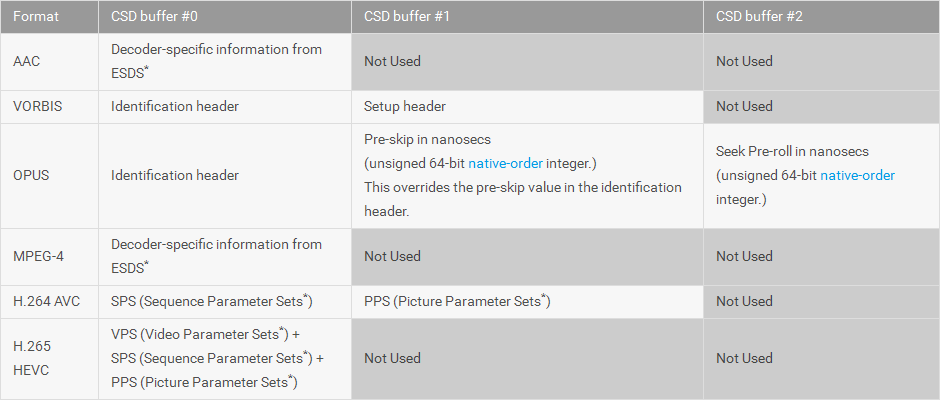 Android多媒體--MediaCodec 中文API文檔,mediacodecapi
Android多媒體--MediaCodec 中文API文檔,mediacodecapi
Android多媒體--MediaCodec 中文API文檔,mediacodecapi*由於工作需要,需要利用MediaCodec實現Playback及Transcod
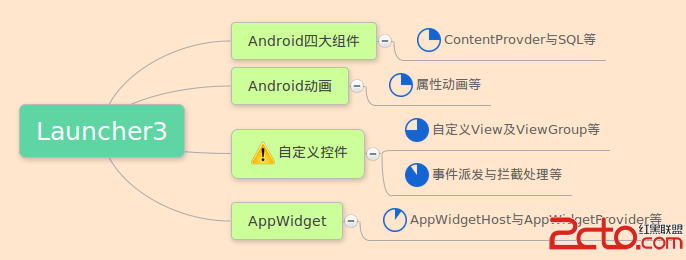 Android M Launcher3主流程源碼淺析
Android M Launcher3主流程源碼淺析
Android M Launcher3主流程源碼淺析 背景 關於Launcher是啥的問題我想這裡就沒必要再強調了。由於一些原因迫使最近開始需要研究一下Launcher3
 27個漂亮的移動端注冊/登錄界面設計作品,27登錄界面設計作品
27個漂亮的移動端注冊/登錄界面設計作品,27登錄界面設計作品
27個漂亮的移動端注冊/登錄界面設計作品,27登錄界面設計作品英文:medium 作者:Muzli 譯者:設計達人 鏈接:http://www.s