編輯:關於android開發

- # coding: utf-8
- import urllib.request
- import json
- import base64
- import sys
- def get_access_token():
- url = "https://openapi.baidu.com/oauth/2.0/token"
- grant_type = "client_credentials"
- client_id = "xxxxxxxxxxxxxxxxxx"
- client_secret = "xxxxxxxxxxxxxxxxxxxxxx"
- url = url + "?" + "grant_type=" + grant_type + "&" + "client_id=" + client_id + "&" + "client_secret=" + client_secret
- resp = urllib.request.urlopen(url).read()
- data = json.loads(resp.decode("utf-8"))
- return data["access_token"]
- def baidu_asr(data, id, token):
- speech_data = base64.b64encode(data).decode("utf-8")
- speech_length = len(data)
- post_data = {
- "format" : "wav",
- "rate" : 16000,
- "channel" : 1,
- "cuid" : id,
- "token" : token,
- "speech" : speech_data,
- "len" : speech_length
- }
- url = "http://vop.baidu.com/server_api"
- json_data = json.dumps(post_data).encode("utf-8")
- json_length = len(json_data)
- #print(json_data)
- req = urllib.request.Request(url, data = json_data)
- req.add_header("Content-Type", "application/json")
- req.add_header("Content-Length", json_length)
- print("asr start request\n")
- resp = urllib.request.urlopen(req)
- print("asr finish request\n")
- resp = resp.read()
- resp_data = json.loads(resp.decode("utf-8"))
- if resp_data["err_no"] == 0:
- return resp_data["result"]
- else:
- print(resp_data)
- return None
- def asr_main(filename):
- f = open(filename, "rb")
- audio_data = f.read()
- f.close()
- #token = get_access_token()
- token = "xxxxxxxxxxxxxxxxxx"
- uuid = "xxxx"
- resp = baidu_asr(audio_data, uuid, token)
- print(resp[0])
- return resp[0]
- import urllib.request
- import sys
- import json
- def robot_main(words):
- url = "http://apis.baidu.com/turing/turing/turing?"
- key = "879a6cb3afb84dbf4fc84a1df2ab7319"
- userid = "1000"
- words = urllib.parse.quote(words)
- url = url + "key=" + key + "&info=" + words + "&userid=" + userid
- req = urllib.request.Request(url)
- req.add_header("apikey", "xxxxxxxxxxxxxxxxxxxxxxxxxx")
- print("robot start request")
- resp = urllib.request.urlopen(req)
- print("robot stop request")
- content = resp.read()
- if content:
- data = json.loads(content.decode("utf-8"))
- print(data["text"])
- return data["text"]
- else:
- return None
- # coding: utf-8
- import urllib.request
- import json
- import sys
- def baidu_tts_by_post(data, id, token):
- post_data = {
- "tex" : data,
- "lan" : "zh",
- "ctp" : 1,
- "cuid" : id,
- "tok" : token,
- }
- url = "http://tsn.baidu.com/text2audio"
- post_data = urllib.parse.urlencode(post_data).encode('utf-8')
- #print(post_data)
- req = urllib.request.Request(url, data = post_data)
- print("tts start request")
- resp = urllib.request.urlopen(req)
- print("tts finish request")
- resp = resp.read()
- return resp
- def tts_main(filename, words):
- token = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
- text = urllib.parse.quote(words)
- uuid = "xxxx"
- resp = baidu_tts_by_post(text, uuid, token)
- f = open("test.mp3", "wb")
- f.write(resp)
- f.close()
- import asr
- import tts
- import robot
- words = asr.asr_main("test.wav")
- new_words = robot.robot_main(words)
- tts.tts_main("test.mp3", new_words)
 Android 6.0 運行時權限處理,android6.0
Android 6.0 運行時權限處理,android6.0
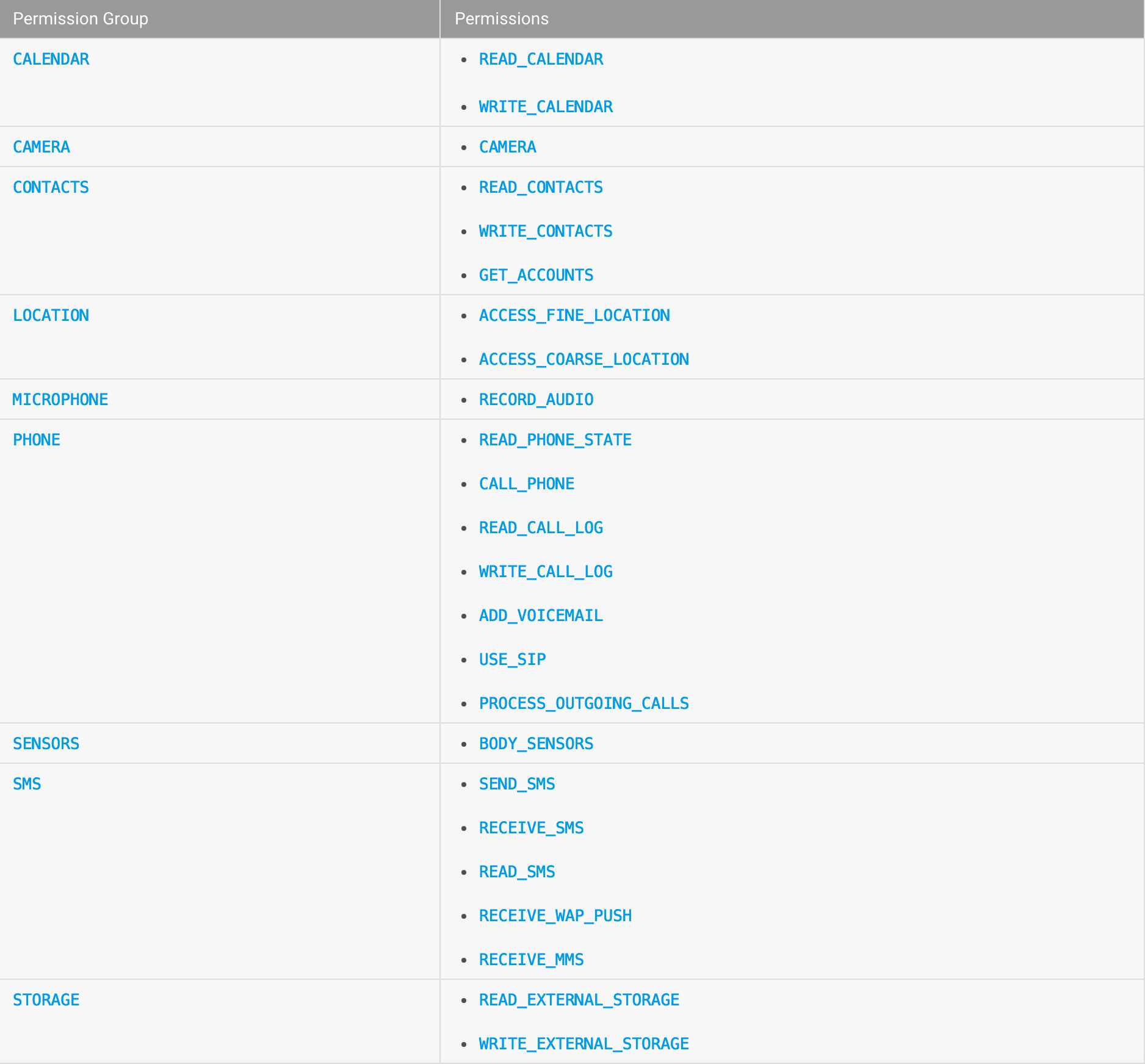
Android 6.0 運行時權限處理,android6.0在運行時請求權限 從Android 6.0(API級別23)開始,用戶權限授予應用程序在應用程序運行時,當他們
 安卓--selector簡單使用,安卓--selector
安卓--selector簡單使用,安卓--selector
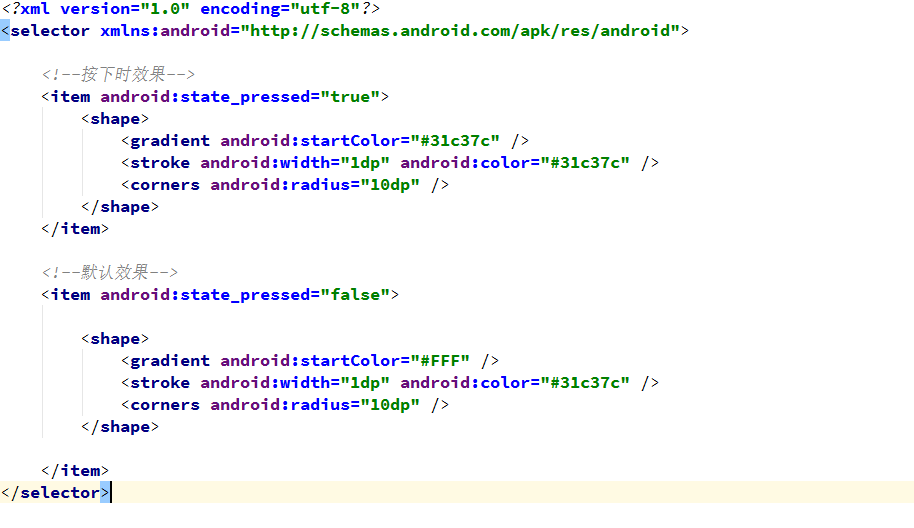
安卓--selector簡單使用,安卓--selectorselector ---選擇器 在App的使用中經常能看到selector的身影 如:一個按鍵看上去白色或者其它
 安卓應用的界面編程(2),安卓應用界面編程
安卓應用的界面編程(2),安卓應用界面編程
安卓應用的界面編程(2),安卓應用界面編程第一組UI組件:布局管理器(以ViewGroup為基類派生的布局管理器) 1.線性布局 LinearLayout類 1 <
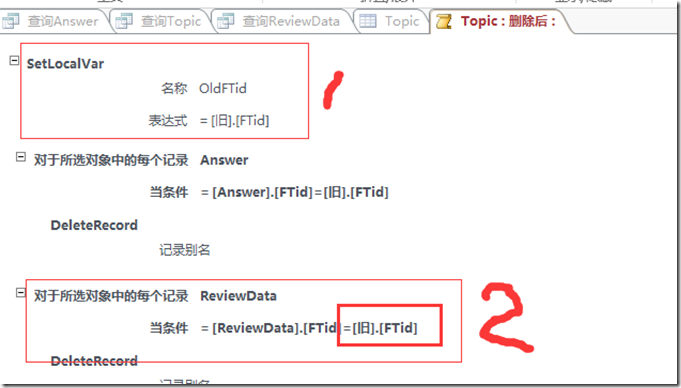 ACCESS 觸發器delete table事件變量使用及連續刪除
ACCESS 觸發器delete table事件變量使用及連續刪除
ACCESS 觸發器delete table事件變量使用及連續刪除ACCESS的TABLE DELETE 事件觸發後,會出現一個[舊]的記錄,這條記錄非常有用,可以用來作