Pacemaker Resource Agent的錯誤處理
1.前言 Pacemaker通過調用各個resource agent提供的操作(比如start,stop)實現對資源的控制,當這個方法執行出錯時,Pacemaker會根據執行的操作和錯誤類型進行不同的錯誤處理。
2. 錯誤類型
Pacemaker將錯誤分成3類:soft,hard和fatal,後兩種屬於環境或配置問題,如果沒有人工干預是不可能自動修復的。一般的故障都采用OCF_ERR_GENERIC作為返回值,比如,服務進程crash,網絡不通等,OCF_ERR_GENERIC屬於soft類型。
http://clusterlabs.org/doc/en-US/Pacemaker/1.1-plugin/html-single/Pacemaker_Explained/index.html#_how_are_ocf_return_codes_interpreted
B.3.How are OCF Return Codes Interpreted?
The first thing the cluster does is to check the return code against the expected result. If the result does not match the expected value, then the operation is considered to have failed and recovery action is initiated.There are three types of failure recovery:
TableB.3.Types of recovery performed by the cluster
Type | Description | Action Taken by the Cluster | softA transient error occurredRestart the resource or move it to a new location hardA non-transient error that may be specific to the current node occurredMove the resource elsewhere and prevent it from being retried on the current node fatalA non-transient error that will be common to all cluster nodes (eg. a bad configuration was specified)Stop the resource and prevent it from being started on any cluster node
Assuming an action is considered to have failed, the following table outlines the different OCF return codes and the type of recovery the cluster will initiate when it is received.
B.4.OCF Return Codes
TableB.4.OCF Return Codes and their Recovery Types
RC | OCF Alias | Description | RT | 0OCF_SUCCESSSuccess. The command completed successfully. This is the expected result for all start, stop, promote and demote commands. soft1OCF_ERR_GENERIC Generic "there was a problem" error code. soft2OCF_ERR_ARGSThe resource’s configuration is not valid on this machine. Eg. refers to a location/tool not found on the node. hard3OCF_ERR_UNIMPLEMENTEDThe requested action is not implemented. hard4OCF_ERR_PERMThe resource agent does not have sufficient privileges to complete the task. hard5OCF_ERR_INSTALLEDThe tools required by the resource are not installed on this machine. hard6OCF_ERR_CONFIGUREDThe resource’s configuration is invalid. Eg. required parameters are missing. fatal7OCF_NOT_RUNNINGThe resource is safely stopped. The cluster will not attempt to stop a resource that returns this for any action. N/A8OCF_RUNNING_MASTERThe resource is running in Master mode. soft9OCF_FAILED_MASTERThe resource is in Master mode but has failed. The resource will be demoted, stopped and then started (and possibly promoted) again. softotherNACustom error code. soft
Although counterintuitive, even actions that return 0 (aka.OCF_SUCCESS) can be considered to have failed.
3. 錯誤處理
每個資源的操作(operation)有一個on-fail屬性,用於控制如何進行出錯處理。
http://clusterlabs.org/doc/en-US/Pacemaker/1.1-plugin/html-single/Pacemaker_Explained/index.html#_monitoring_resources_for_failure
Table5.3.Properties of an Operation
Field | Description | idYour name for the action. Must be unique. nameThe action to perform. Common values: monitor, start, stop intervalHow frequently (in seconds) to perform the operation. Default value: 0, meaning never. timeoutHow long to wait before declaring the action has failed. on-failThe action to take if this action ever fails. Allowed values:*
ignore - Pretend the resource did not fail*
block - Don’t perform any further operations on the resource*
stop - Stop the resource and do not start it elsewhere*
restart - Stop the resource and start it again (possibly on a different node)*
fence - STONITH the node on which the resource failed*
standby - Move
all resources away from the node on which the resource failedThe default for the stop operation is fence when STONITH is enabled and block otherwise. All other operations default to stop. enabledIf false, the operation is treated as if it does not exist. Allowed values: true, false
但是,實際測試驗證後,發現不管如何設置on-fail,效果都不會變,也就是說永遠是缺省行為。
以下是讓Resource Agent的各個操作返回OCF_ERR_GENERIC時資源管理器的處理:
操作 | 錯誤處理 | 對應的on-fail值 | start
設置fail-count=1000000
在本節點上調用stop
在其它節點上start該資源
restartstop
設置fail-count=1000000
阻止該資源的進一步操作,該資源成為unmanaged FAILED狀態,如下
dummy(ocf::heartbeat:Dummy2):Started srdsdevapp69 (unmanaged) FAILED
blockmonitor
設置fail-count+=1
在本節點上依次調用stop,start,monitor。如果monitor依然出錯,重復stop,start,monitor,直到fail-count達到migration-threshold後,保持資源為stop狀態。
restartpromote
設置fail-count+=1
在本節點上依次調用demote,stop,start。
在其它節點上調用promote以提升其它節點上的資源為master
restartdemote
設置fail-count+=1
在本節點上依次調用stop,start,demote。如果demote依然出錯,重復stop,start,demote,直到fail-count達到migration-threshold後,保持資源為stop狀態。
restart notify無視ignore
注1:超時的處理與OCF_ERR_GENERIC相同
注2:Pacemaker不會對已經stop了的資源調用post stop notify。
注3:測試環境Pacemaker 1.1.7-6 ,CentOS 6.3
4.啟示
上面關於錯誤處理的測試結果,可以給Resource Agent編寫者提供幾點啟示:
- 1. 如非確實必要,不要讓stop操作返回錯誤
- 2. monitor和start的判斷要保持一致,即不應該出現start成功後立刻執行monitor卻失敗的情況,否則可能導致循環。
- 3. restart成功後執行demote不應該失敗,否則可能導致循環。
- 4. migration-threshold設置為一個比較小的值(默認值是INFINITY,即100000),也可以減少上面的2和3的影響。
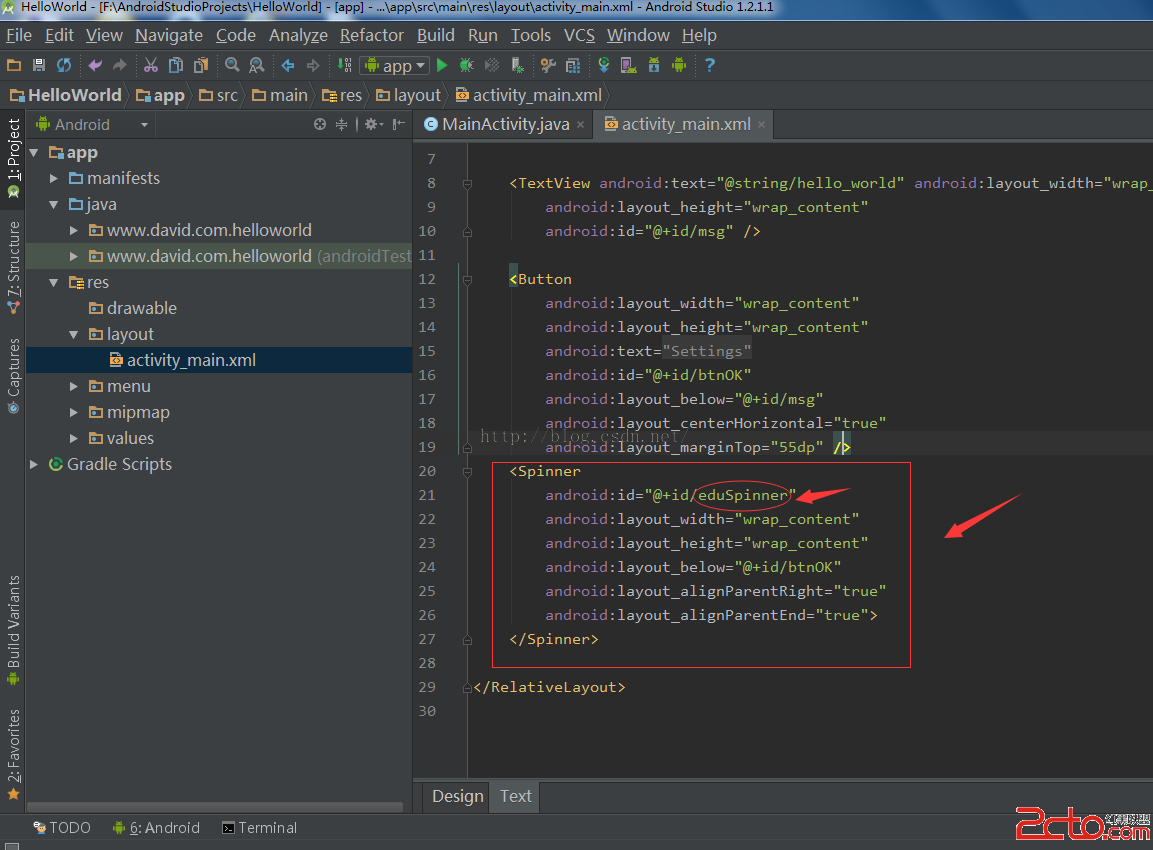 Android Studio中Spinner控件的數據綁定實現
Android Studio中Spinner控件的數據綁定實現
 Android中實時預覽UI和編寫UI的各種技巧,androidui
Android中實時預覽UI和編寫UI的各種技巧,androidui
 使用android.support.design.widget.TabLayout出現java.lang.reflect.InvocationTargetException,androidtablayout
使用android.support.design.widget.TabLayout出現java.lang.reflect.InvocationTargetException,androidtablayout
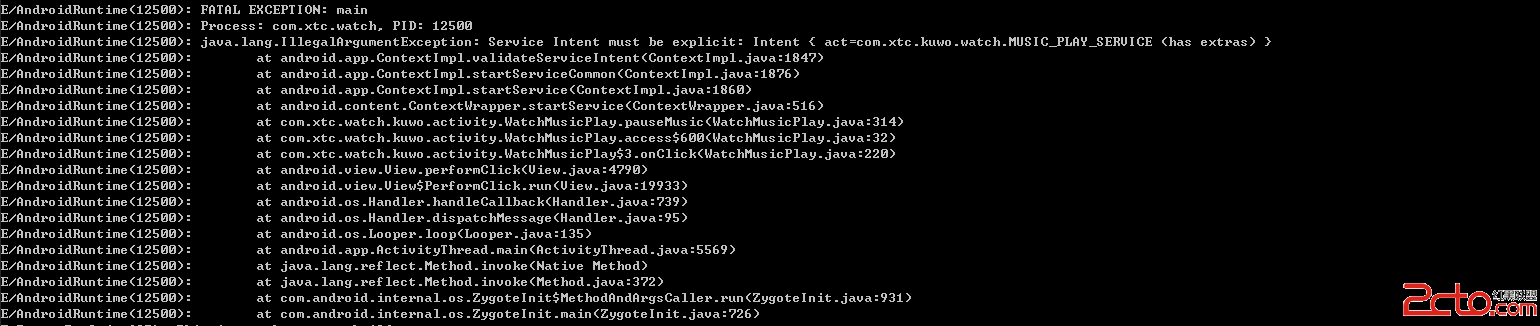 我的Android進階之旅------Android 5.0中出現警告的解決方法: Service Intent must be explicit:
我的Android進階之旅------Android 5.0中出現警告的解決方法: Service Intent must be explicit: