編輯:關於android開發
testDB=# create table t_hash(id int,name varchar(50)) distributed by (id);
CREATE TABLE
testDB=#
testDB=# \d t_hash
Table "public.t_hash"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) |
Distributed by: (id)
添加主鍵後,主鍵升級為分布鍵替代了id列。
testDB=# alter table t_hash addprimary key (name);
NOTICE: updating distribution policy to match new primary key
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "t_hash_pkey" for table "t_hash"
ALTER TABLE
testDB=# \d t_hash
Table "public.t_hash"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) | not null
Indexes:
"t_hash_pkey" PRIMARY KEY, btree (name)
Distributed by: (name)
驗證hash分布表可實現主鍵或者唯一鍵值的唯一性
testDB=# insert into t_hash values(1,'szlsd1');
INSERT 0 1
testDB=#
testDB=# insert into t_hash values(2,'szlsd1');
ERROR: duplicate key violates unique constraint "t_hash_pkey"(seg2 gp-s3:40000 pid=3855)
testDB=# create unique index u_id on t_hash(name);
CREATE INDEX
testDB=#
testDB=#
testDB=# \d t_hash
Table "public.t_hash"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) | not null
Indexes:
"t_hash_pkey" PRIMARY KEY, btree (name)
"u_id" UNIQUE, btree (name)
Distributed by: (name)
testDB=# create unique index uk_id on t_hash(id);
ERROR: UNIQUE indexmust contain all columns in the distribution keyof relation "t_hash"
testDB=# create unique index uk_id on t_hash(id,name);
CREATE INDEX
testDB=# \d t_hash
Table "public.t_hash"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) | not null
Indexes:
"t_hash_pkey" PRIMARY KEY, btree (name)
"uk_id" UNIQUE, btree (id, name)
Distributed by: (name)
testDB=# alter table t_hash drop constraint t_hash_pkey;
ALTER TABLE
testDB=# \d t_hash
Table "public.t_hash"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) | not null
Distributed by: (name)
testDB=#insert into t_hash values(1,'szlsd');
INSERT 0 1
testDB=#insert into t_hash values(2,'szlsd');
INSERT 0 1
testDB=#insert into t_hash values(3,'szlsd');
INSERT 0 1
testDB=#insert into t_hash values(4,'szlsd');
INSERT 0 1
testDB=#insert into t_hash values(5,'szlsd');
INSERT 0 1
testDB=#insert into t_hash values(6,'szlsd');
INSERT 0 1
testDB=#
testDB=#
testDB=# select gp_segment_id,count(*) from t_hash group by gp_segment_id;
gp_segment_id | count
---------------+-------
2 |7
(1 row)
testDB=# create table t_random(id int ,name varchar(100))distributed randomly;
CREATE TABLE
testDB=#
testDB=#
testDB=# \d t_random
Table "public.t_random"
Column | Type | Modifiers
--------+------------------------+-----------
id | integer |
name | character varying(100) |
Distributed randomly
testDB=# alter table t_random add primary key (id,name);
ERROR: PRIMARY KEY and DISTRIBUTED RANDOMLY are incompatible
testDB=#
testDB=# create unique index uk_r_id on t_random(id);
ERROR: UNIQUE and DISTRIBUTED RANDOMLY are incompatible
testDB=#
testDB=# insert into t_random values(1,'szlsd3');
INSERT 0 1
testDB=# select gp_segment_id,count(*) from t_random group by gp_segment_id;
gp_segment_id | count
---------------+-------
1 | 1
(1 row)
testDB=#
testDB=# insert into t_random values(1,'szlsd3');
INSERT 0 1
testDB=# select gp_segment_id,count(*) from t_random group by gp_segment_id;
gp_segment_id | count
---------------+-------
2 | 1
1 | 1
(2 rows)
testDB=# insert into t_random values(1,'szlsd3');
INSERT 0 1
testDB=# select gp_segment_id,count(*) from t_random group by gp_segment_id;
gp_segment_id | count
---------------+-------
2 | 1
1 | 2
(2 rows)
testDB=# insert into t_random values(1,'szlsd3');
INSERT 0 1
testDB=# select gp_segment_id,count(*) from t_random group by gp_segment_id;
gp_segment_id | count
---------------+-------
2 | 2
1 | 2
(2 rows)
testDB=# insert into t_random values(1,'szlsd3');
INSERT 0 1
testDB=# select gp_segment_id,count(*) from t_random group by gp_segment_id;
gp_segment_id | count
---------------+-------
2 | 2
1 | 3
(2 rows)
testDB=# insert into t_random values(1,'szlsd3');
INSERT 0 1
testDB=# select gp_segment_id,count(*) from t_random group by gp_segment_id;
gp_segment_id | count
---------------+-------
2 |2
1 |3
0 | 1
(3 rows)
testDB=# \d t_hash;
Table "public.t_hash"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) | not null
Indexes:
"t_hash_pkey" PRIMARY KEY, btree (name)
"uk_id" UNIQUE, btree (id, name)
Distributed by: (name)
testDB=#
testDB=#
testDB=# create table t_hash_1 as select * from t_hash;
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column(s) named 'name' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
SELECT 0
testDB=# \d t_hash_1
Table "public.t_hash_1"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) |
Distributed by: (name)
testDB=#
testDB=# create table t_hash_2 (like t_hash);
NOTICE: Table doesn't have 'distributed by' clause, defaulting to distribution columns from LIKE table
CREATE TABLE
testDB=# \d t_hash_2
Table "public.t_hash_2"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) | not null
Distributed by: (name)
testDB=# create table t_hash_3 as select * from t_hash distributed by (id);
SELECT 0
testDB=#
testDB=# \d t_hash_3
Table "public.t_hash_3"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) |
Distributed by: (id)
testDB=#
testDB=#
testDB=# create table t_hash_4 (like t_hash) distributed by (id);
CREATE TABLE
testDB=#
testDB=# \d t_hash4
Did not find any relation named "t_hash4".
testDB=# \d t_hash_4
Table "public.t_hash_4"
Column | Type | Modifiers
--------+-----------------------+-----------
id | integer |
name | character varying(50) | not null
Distributed by: (id)
testDB=# \d t_random
Table "public.t_random"
Column | Type | Modifiers
--------+------------------------+-----------
id | integer |
name | character varying(100) |
Distributed randomly
testDB=#
testDB=# \d t_random_1
Table "public.t_random_1"
Column | Type | Modifiers
--------+------------------------+-----------
id | integer |
name | character varying(100) |
Distributed by: (id)
testDB=# create table t_random_2 as select * from t_randomdistributed randomly;
SELECT 7
testDB=#
testDB=# \d t_random_2
Table "public.t_random_2"
Column |Type| Modifiers
--------+------------------------+-----------
id| integer|
name| character varying(100) |
Distributed randomly
 【項目篇】Android團隊項目開發之統一代碼規范
【項目篇】Android團隊項目開發之統一代碼規范
【項目篇】Android團隊項目開發之統一代碼規范 前言 團隊項目開發前的統一三要素:統一需求/開發文檔,統一代碼規范,統一環境(編譯/測試/發布)。 一個項目團隊,要想
 RecyclerView 結合 CardView 使用,recyclerview使用
RecyclerView 結合 CardView 使用,recyclerview使用
RecyclerView 結合 CardView 使用,recyclerview使用准備工作:導入 1.activity_mian.xml <android.sup
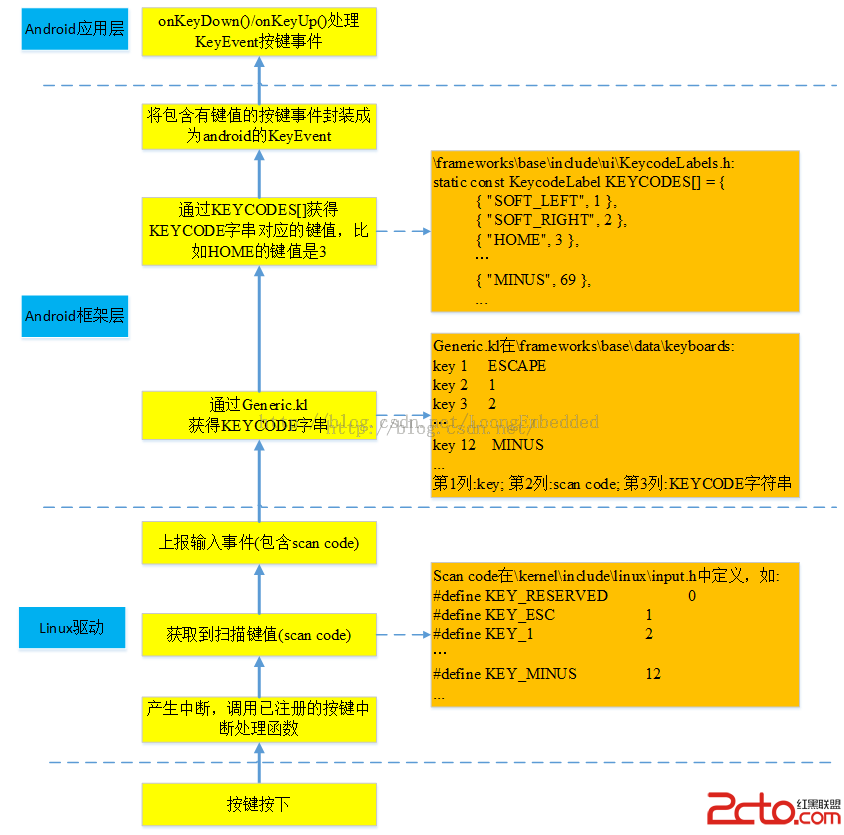 MSM8909+Android5.1.1鍵盤驅動淺析
MSM8909+Android5.1.1鍵盤驅動淺析
MSM8909+Android5.1.1鍵盤驅動淺析 MSM8909+Android5.1.1鍵盤驅動------概述 采用SN7326帶智能指掃描的鍵
 在eclipse中安裝上genymotion插件,eclipsegenymotion
在eclipse中安裝上genymotion插件,eclipsegenymotion
在eclipse中安裝上genymotion插件,eclipsegenymotion1.安裝genymotion-vbox,選擇安裝目錄。 具體安裝過程可見http://