android上的緩存、緩存算法和緩存框架
1.使用緩存的目的
緩存是存取數據的臨時地,因為取原始數據代價太大了,加了緩存,可以取得快些。緩存可以認為是原始數據的子集,它是從原始數據裡復制出來的,並且為了能被取回,被加上了標志。
在android開發中,經常要訪問網絡數據比如大量網絡圖片,如果每次需要同一張圖片都去網絡獲取,這代價顯然太大了。可以考慮設置本地文件緩存和內存緩存,存儲從網絡取得的數據;本地文件緩存空間並非是無限大的,容量越大讀取效率越低,可設置一個折中緩存容量比如10M,如果緩存已滿,我們需要采用合適的替換策略換掉一個已有的數據對象,並替之已一個新的數據對象;內存緩存作為最先被讀取的數據,應該存儲那些經常使用的數據對象,且內存容量有限,內存緩存的容量也應該限定。依照這樣的做法,取得一個圖片(總圖片數為N)的流程應該是這樣的:
a.先在內存緩存取(設存儲K個),若取到則返回(命中率為K/N,時間為tA),否則進行b;
b.在本地文件緩存(設能存儲M個)中取,若取到則返回並更新內存緩存(命中率為(M-K)/N,時間為tB),否則進行c;
c.通過網絡下載圖片,並更新本地文件緩存和內存緩存(命中率為(N-M)/N,時間為tC);
取一張圖片的時間期望為:W = tA * (K/N) + tB * (M-K)/N + tC * (N-M)/N ,其中tA < tB < tC ,為使W代價小,即盡可能快的取得數據,我們應該提高內存緩存的命中率和本地文件緩存的命中率,但兩者的容量都是有限制的,所以必須使用適合替換算法來更新兩者所存儲的對象。選擇合適的替換算法是緩存的難點所在。
2.常見緩存算法
Least Frequently Used(LFU)
對每個緩存對象計算他們被使用的頻率。把最不常用的緩存對象換走。
Least Recently User(LRU)
把最近最少使用的緩存對象給換走。總是需要去了解在什麼時候,用了哪個緩存對象。如果有人想要了解為什麼總能把最近最少使用的對象踢掉,是非常困難的。浏覽器就是使用了LRU作為緩存算法。新的對象會被放在緩存的頂部,當緩存達到了容量極限,我會把底部的對象踢走,而技巧就是:我會把最新被訪問的緩存對象,放到緩存池的頂部。
所以,經常被讀取的緩存對象就會一直呆在緩存池中。可以用數據或者鏈表實現。其改進算法有LRU2 和 2Q。
Least Recently Used 2(LRU2)
把被兩次訪問過的對象放入緩存池,當緩存池滿了之後,我會把有兩次最少使用的緩存對象踢走。因為需要跟蹤對象2次,訪問負載就會隨著緩存池的增加而增加。如果用在大容量的緩存池中,就會有問題。另外,還需跟蹤那麼不在緩存的對象,因為他們還沒有被第二次讀取。這比LRU好。
Two Queues(2Q)
把被訪問的數據放到LRU的緩存中,如果該對象再一次被訪問,就把他轉移到第二個更大的LRU緩存。替換掉緩存對象是為了保持第一個緩存池是第二個緩存池的1/3。當緩存的訪問負載是固定的時候,把 LRU 換成 LRU2,就比增加緩存的容量更好。這種機制使得該算法比 LRU2 更好。
Adaptive Replacement Cache(ARC)
這種算法介於 LRU 和 LFU 之間,由2個 LRU 組成,第一個,也就是 L1,包含的條目是最近只被使用過一次的,而第二個 LRU,也就是L2,包含的是最近被使用過兩次的條目。因此,L1 放的是新的對象,而 L2 放的是常用的對象。該算法是是性能最好的緩存算法之一,能夠自調,並且是低負載的。保存著歷史對象,這樣,就可以記住那些被移除的對象,同時,也可以看到被替換掉的對象是否可以留下,取而代之的是替換別的對象。該算法記憶力很差,但是很快,適用性也強。
Most Recently Used(MRU)
該算法與 LRU是對應的。它替換掉最近最多被使用的對象,你一定會問為什麼。原因是,當一次訪問過來的時候,有些事情是無法預測的,並且在緩存系統中找出最少最近使用的對象是一項時間復雜度非常高的運算。該算法在數據庫內存緩存中很見!每當一次緩存記錄的使用,會把它放到棧的頂端。當棧滿了的時候,會把棧頂的對象給換成新進來的對象!
First in First out(FIFO)
這是一個低負載的算法,並且對緩存對象的管理要求不高。通過一個隊列去跟蹤所有的緩存對象,最近最常用的緩存對象放在後面,而更早的緩存對象放在前面,當緩存容量滿時,排在前面的緩存對象會被踢走,然後把新的緩存對象加進去。很快,但是不適用。
Second Chance
改進的FIFO算法,比 FIFO 好的地方是改善了 FIFO 的成本。一樣是在觀察隊列的前端,但是很FIFO的立刻替換不同,它會檢查即將要被踢出的對象有沒有之前被使用過的標志(1一個bit表示),如果沒有被使用過,就把他換出;否則,把這個標志位清除,然後把這個緩存對象當做新增緩存對象加入隊列。你可以想象就這就像一個環隊列。當再一次在隊頭碰到這個對象時,由於它已經沒有標志位,可以立刻就它換出。在速度上比FIFO快。
CLock
這是一個更好的FIFO,也比 second chance更好。因為它不會像second chance那樣把有標志的緩存對象放到隊列的尾部,但是也可以達到second chance的效果。它持有一個裝有緩存對象的環形列表,頭指針指向列表中最老的緩存對象。當緩存miss發生並且沒有新的緩存空間時,它會根據指針指向的緩存對象的標志位去決定應該怎麼做。如果標志是0,直接用新的緩存對象替代這個緩存對象;如果標志位是1,把頭指針遞增,然後重復這個過程,直到新的緩存對象能夠被放入。
Simple time-based
通過絕對的時間周期去失效那些緩存對象。對於新增的對象,保存特定的時間。很快,但不適用。
Extended time-based expiration
通過相對時間去失效緩存對象的;對於新增的緩存對象,保存特定的時間,比如是每5分鐘,每天的12點。
Sliding time-based expiration
被管理的緩存對象的生命起點是在這個緩存的最後被訪問時間算起。很快,不太適用。
緩存算法主要考慮到了下面幾點:
成本。如果緩存對象有不同的成本,應該把那些難以獲得的對象保存下來。
容量。如果緩存對象有不同的大小,應該把那些大的緩存對象清除,這樣就可以讓更多的小緩存對象進來了。
時間。一些緩存還保存著緩存的過期時間。電腦會失效他們,因為他們已經過期了。
3.增強用戶體驗的圖片緩存框架
詳見 android上的一個網絡接口和圖片緩存框架enif 。
 《Android源碼設計模式解析與實戰》讀書筆記(二十)
《Android源碼設計模式解析與實戰》讀書筆記(二十)
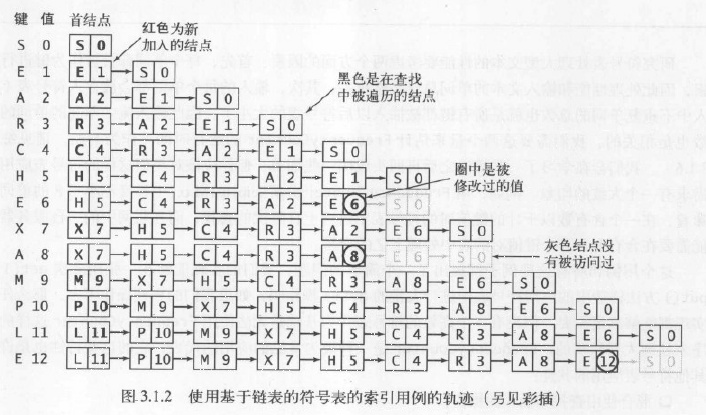 算法—7.無序鏈表中的順序查找,算法無序
算法—7.無序鏈表中的順序查找,算法無序
 Android開發3:Intent、Bundle的使用和ListView的應用 、RelativeLayout(相對布局)簡述(簡單通訊錄的實現),relativelayout
Android開發3:Intent、Bundle的使用和ListView的應用 、RelativeLayout(相對布局)簡述(簡單通訊錄的實現),relativelayout
 Android 字符亂碼問題的處理,android亂碼
Android 字符亂碼問題的處理,android亂碼