編輯:中級開發
簡介: BFS 是一款專門為 Linux 桌面環境所設計的內核調度器,它基於 Staircase Deadline 和 EEVDF 算法,支持 Linux 2.6.31 之後的內核。它提供了前所未有的流暢桌面性能,不僅得到了用戶的認可,也為一些商業系統所采用。本文簡單介紹了 BFS 的基本原理,希望能對想深入了解 Linux 調度器的讀者提供一些幫助。
概述
BFS 是一個進程調度器,可以解釋為“腦殘調度器”。這古怪的名字有多重含義,比較容易被接受的一個說法為:它如此簡單,卻如此出色,這會讓人對自己的思維能力產生懷疑。
BFS 不會被合並進入 Linus 維護的 Linux mainline,BFS 本身也不打算這麼做。但 BFS 擁有眾多的擁趸,這只有一個原因:BFS 非常出色,它讓用戶的桌面環境達到了前所未有的流暢。在硬件越來越先進,系統卻依然常顯得遲鈍的時代,這實在讓人興奮。
進入 2010 年,android 使用 BFS 作為其操作系統的標准調度器,這也證明了 BFS 的價值。
BFS vs CFS,性能測試比拼
BFS 出現後得到了很多用戶的好評,得到了諸如“快,感覺的到的快”,“桌面的急速未來”等評價。這些詞讓人側目,於是我便開始四下尋找關於 BFS 的測試數據,希望能找到說明這一切的數字或者曲線。但結果卻頗令人失望。。。
Jens Axboe 的測試
BFS 發布後不久,即 2009 年 9 月,Ingo Molnar 發布了他的測評報告,比較了 CFS 和 BFS。作為 CFS 的作者 , 他所宣稱的測試結果並不讓人覺得意外:CFS 在各個方面優於 BFS。不過人們對他的測評結果有不同的反應,有人認同,也有人心存疑惑。Jens Axboe 就是心存懷疑的一位,他自己寫了一個名為 Latt.c 的程序,試圖測試調度器的兩個神秘屬性:”Interactivity”和 “Fluidness”。
他的測試結果剛好相反,表明 BFS 在交互性方面優於 CFS,而且其 CPU 利用率更高。不過 BFS 穩定性較差,並且在某些情況下也表現出了糟糕的交互性問題。
從 Jens 的測試數據來看,BFS 稍微優於 CFS,但優勢並非如同坊間流傳的那樣誇張。感興趣的讀者可以在 lkml 的郵件列表中找到 Jens 測試的詳細數據:http://thread.gmane.org/gmane.Linux.kernel/886319/focus=887636
結果讓翹首以盼的我有些失望,並沒有看到 BFS 遙遙領先。反而有些類似奧運會男子百米的決賽,究竟誰是冠軍一時竟難以分辨。但值得注意的是,該測試意外地讓人們認識到了 CFS 本身的一個嚴重問題。
CFS 的 sleeper fairness 特性導致在一些情況下將出現嚴重的調度延遲,在 Jens 的 xmodmap測試中甚至出現了 10s 的延遲。並且圍繞 Jens 的測試,人們紛紛發表聲明,使用 CFS 時有很多交互性問題,比如編譯內核時,同時的音頻視頻會出現嚴重的停頓,而使用 BFS 則沒有這些問題。不過這些 CFS 的問題都在關閉了 sleeper fairness 特性後神秘地消失了。
這讓 CFS 調度器的開發者不得不暫時關閉了 sleeper fairness 特性,並一度曾號稱將在即將發布的 2.6.32 中正式關閉該特性,直到問題被解決為止。令人吃驚的是,Ingo 在一周之內就拋出了新的 patch,即 Gentle Fairness。使用這個 patch,10s 延遲消失了,其他的關於鼠標滯後,視頻停頓的關於 CFS 的負面報告也都消失了。。。
Phoronix 的測試
您可以在 http://www.phoronix.com/scan.PHP?page=article&item=bfs_scheduler_benchmarks&num=1和http://global.phoronix-test-suite.com/?k=profile&u=zero-9274-28890-6247看到 Phoronix 對 BFS 的專業測試。該測試也是在 2009 年 9 月完成的,如前所述,此後 BFS 和 CFS 都有了一些更新,因此該測試也不能完全反映這兩款調度器最新的狀態。但作為權威的測評機構,該測評結果還是值得一看。
從 Phoronix 的測試結果來看,BFS 在多項測試中稍微領先,CFS 則在其余一些測試項目中反超。我不禁又有些黯然。
唯一能體現 BFS“急速”的測試項目來自針對網絡服務器吞吐量的測試,特在此處張貼這張最具有說服力和震撼力的直方圖。
圖 1. 網絡吞吐量測試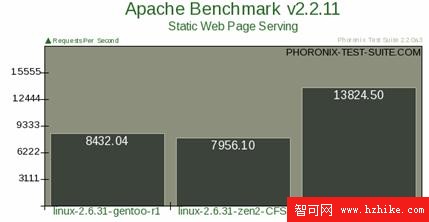
但除此一項之外,總的來講,Phoronix 的測試結果終究只是表明 BFS 和 CFS 旗鼓相當。
University of New Mexico 計算機系的測評
新墨西哥大學的 Taylor Groves, Je Knockel, Eric Schulte 在 2009 年 12 月也發布了一個 BFS vs. CFS 的評測報告。
他們的測評關注於三個方面:延遲 , Turnaround Time 還有交互性。下面摘錄他們的測試結果。
圖 2. 延遲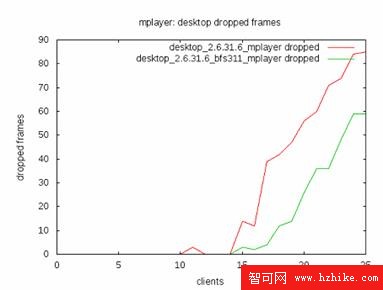
圖 3. Turnaround Time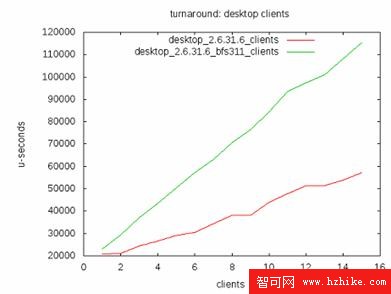
圖 4. 交互性
這三張圖總算聊以安慰我四處找尋的辛苦,根據這個評測結果,終於可以得到這樣的結論:
在 turnaround time 方面,CFS 優於 BFS。但是 BFS 的調度延遲小於 CFS。這說明 BFS 更加適應於交互式應用環境。CFS 更加適合於批處理作業環境。這跟許多用戶的體驗相同。
小結
以上三個測評都是在 Linux2.6.32 發布前完成的。然而 CFS 在 Linux2.6.32 中引入了 GENTLE_FAIR_SLEEPERS 特性,正如 2.1 節中所說,這個 patch 據說是極大地提高了交互性。不幸的是,在那以後,卻似乎再也沒有人做關於 CFS 和 BFS 的比較測試了。因此在 Linux 已經進入 2.6.35 的時代,我們更無法輕易得出 BFS 和 CFS 孰優孰劣的結論。
從另一方面講,雖然專業評測沒有顯示出 BFS 的明顯優勢,但從 Internet 上能收集到的信息來看,大多數用戶都覺得 BFS 能夠顯著地提高交互式應用的體驗,這是一種個人的體驗,比如鼠標的移動是否流暢等等。在這類體驗中,兩款調度器的差異卻是相當大,這無法用前面的測試數據來加以說明。
因此我認為,目前人們並沒有理解影響交互性的真正原因,專業測試所關注的數據尚無法准確描述諸如“流暢”這類主觀的感覺。因此,對於 BFS,我們不妨相信感覺一次吧。
那麼 BFS 究竟做了哪些改進,如果這些改進如此有效,為什麼主流內核不願意接納 BFS 呢?
BFS vs CFS,設計上的不同
白天 Con Kolivas 在醫院裡當麻醉師,為人們解除痛苦,業余的時候借 Linux 解除自己的痛苦。額,Kolivas 學習 Linux 並不是為了解決痛苦,我臆測而已。但據 Kolivas 自述,他接觸 Linux 內核時連 C 語言也沒有學習過。。。這個事實證明,語言只是一項工具,對問題本質的深入理解才是寫程序的關鍵。可能還有執著,CFS 和 RSDL 之爭導致 Kolivas 離開 Linux 社區,此去經年,當 Kolivas 再次開始看內核代碼的時候,他立即發現 CFS 存在以下幾個設計上的問題:
CFS 的目標是支持從桌面到高端服務器的所有應用場景,這種大而全的設計思路導致其必須做一些實現上的折中,此外,那些只有在高端機器中才需要的特性將引入不必要的復雜代碼。
其次,為了維護多 CPU 上的公平性,CFS 采用了負載平衡機制,Kolivas 認為,這些復雜代碼抵消了 per cpu queue 曾帶來的好處。
最後,主流內核的 CFS 還是對睡眠進程存在一些偏好,這意味著“不公平”。
設計目標的不同
在現實中,調度算法類似一個處境尴尬的主婦,滿足孩子對晚餐的要求便有可能傷害到老人的食欲。Linux 內核一直試圖做出一道讓全家老少都喜歡的菜,在這方面,CFS 已經做的很好。但一道能被所有人接受的菜,或許就意味著稍許平淡。而 BFS 只打算滿足一種口味,以便將這種口味發展到極限。
根據 Linux Magazine 的說法,Con Kolivas 是看到了下面這則來自 xkcd 的漫畫而開始思考 BFS 的。
圖 5. 譏諷 Linux 調度器的 xkcd 漫畫
事情源於一些 Linux 用戶,他們發現 Linux 雖然號稱能夠充分發揮 4096 顆 CPU 系統的計算能力,但在普通的 laptop 上卻無法流暢地播放 Youtube 視頻。
這讓人們開始思考,對於 Desktop 環境來講,CFS 哪些復雜的特性究竟是否還有意義?人們是否有必要在自己的個人電腦中使用一個支持 4096 個 CPU 的調度器?
BFS 正是對這種質疑的自然反應。它不打算支持 4096 個 CPU 的龐然大物,BFS 的目標是普通人使用的桌面電腦。此外,BFS 還刪除了那些只有在服務器上才需要的特性。比如,BFS 拋棄了 CFS 的組調度特性,類似 CGROUP 這樣的特性對於普通的桌面用戶是多余的技術。
這很容易理解:在只有一個 CPU 的系統中,誰還會設計多個 CGroup,哪裡還能用到 NUMA domain 等概念呢?
此外 BFS 使用單一的 run queue,不再需要復雜的負載均衡機制。由於不再有 CGROUP 概念,也不再需要 Group 間的負載均衡。
這些簡單的裁剪使得 BFS 的代碼極大地簡化,簡化的代碼意味著執行一次調度所需要的指令數減少了,相應的 footprint 自然也減少了。
當然簡化代碼只是一個顯而易見的方面,更重要的是,這種理念的不同會對最終的調度器實現產生更加深遠的影響,這實在是難以盡述。
多隊列 vs 單一隊列
在 Linux 內核進入 2.6 時,調度器采用 per cpu run queue 從而克服了單一 run queue 的局限。在多 CPU 系統中,單一 run queue 意味著 run queue 成為了系統的瓶頸,因為在同一時刻,一個 CPU 訪問 run queue 時,其他的 CPU 即使空閒也必須等待。當使用 per CPU 的 run queue 之後,每個 CPU 不必再使用大鎖,從而能夠並行地處理調度。
但很多事情都不像第一眼看上去那樣簡單。
Kolivas 發現,采用 per cpu run queue 所帶來的好處會被追求公平性的 load balance 代碼所抵消。在目前的 CFS 調度器中,每顆 CPU 只維護本地 run queue 中所有進程的公平性,為了實現跨 CPU 的調度公平性,CFS 必須定時進行 load balance,將一些進程從繁忙的 CPU 的 run queue 中移到其他空閒的 run queue 中。
這個 load balance 的過程需要獲得其他 run queue 的鎖,這種操作降低了多運行隊列帶來的並行性。
並且在復雜情況下,這種因 load balance 而引入的 footprint 將非常可觀。
當然,load balance 引入的加鎖操作依然比全局鎖的代價要低,這種代價差異隨著 CPU 個數的增加而更加顯著。但請您注意,BFS 並不打算為那些擁有 1024 個 CPU 的系統工作,假若系統中的 CPU 個數有限時,多 run queue 的優勢便不明顯了。
而 BFS 采用單一隊列之後,每一個需要調度的新進程都可以在全局范圍內查找最合適的 CPU,而無需 CFS 那樣等待 load balance 代碼來決定,這減少了多 CPU 之間裁決的延遲,最終的結果是更小的調度延遲。
向前看還是向後看?
多年來 Kolivas 一直關注著 Linux 在 desktop 上的表現。對於 desktop 的用戶,最注重的不是系統的吞吐量,而是交互性程序的流暢體驗。從 SD 開始,Kolivas 就告訴內核黑客們,完全公平能夠從根本上保證交互性。他始終堅持一個基本觀點:調度器應該 forward look only。決不要去考慮一個進程的過去。
CFS 卻偏偏要考慮進程的過去。2.6.23 的時候,CFS 記錄並使用 sleep time。之後不久,在 2.6.24 發布的時候,CFS 合並了“Real Fair Scheduler”,刪除了 sleep time。因此在 2.6.24 之後的內核中,CFS 終於也不再考慮進程過去的睡眠時間。
但 CFS 還是保留了 sleeper fairness 的思想,當進程 wakeup 的時候,在 place_entity() 函數中,CFS 將對 sleeper 進行獎勵,以便其能盡快得到 CPU。這個策略是非常微妙的,我們在 2.1 節中詳細介紹了 sleeper fairness 的演進過程。假如您花些時間回頭再看看,就會發現 sleeper fairness 曾造成怎樣嚴重的延遲問題。雖然 Ingo 自稱 Gentle fairness 解決了延遲問題,但從代碼上看,Gentle Fairness 只是對 sleeper 的獎勵減半而已。因此我們可以說,CFS 依然對 Sleeper 進程進行獎勵,這代表著一種偏好,一種“不公平”。而這,正是 BFS 所反對的。
BFS 中,當一個進程 wakeup 時,調度器將根據進程的 deadline 來進行選擇(關於 deadline 本文將在第 4 章中詳細描述),其結果是,更早睡眠的進程能更快地得到調度;CFS 的 sleeper fairness 則意味著要根據 wakeup 的時間來選擇下一個被調度的進程,更早 wakeup 的進程會更快得到調度。
這種不同究竟會對桌面應用造成何種影響尚沒有理論依據可以參考。但我個人認為,BFS 的策略更加合理。
您現在可能已經讀得有些煩躁了 ( 這些英文加中文的說些啥啊 ),所以我還是盡快介紹一下 BFS 的實現細節吧。然後或許您會理解我,有些詞還是不翻譯更好。
BFS 實現原理
調度器是非常復雜的話題,尤其是 CFS 調度器,想要描述清楚,需要一支非凡的筆,我還沒有找到。但 BFS 非常簡單,所以我才有勇氣在這裡寫點兒 BFS 的實現原理什麼的。首先介紹幾個關鍵概念。
虛擬 Deadline ( Virtual Deadline )
當一個進程被創建時,它被賦予一個固定的時間片,和一個虛擬 Deadline。該虛擬 deadline 的計算公式非常簡單:
Virtual Deadline = jiffIEs + (user_priority * rr_interval) 公式一
其中 jiffIEs 是當前時間 , user_priority 是進程的優先級,rr_interval 代表 round-robin interval,近似於一個進程必須被調度的最後期限,所謂 Deadline 麼。不過在這個 Deadline 之前還有一個形容詞為 Virtual,因此這個 Deadline 只是表達一種願望而已,並非很多領導們常說的那種 deadline。
虛擬 Deadline 將用於調度器的 picknext 決策,這將在後續章節詳細描述。
進程隊列的表示方法和調度策略
在操作系統內部,所有的 Ready 進程都被存放在進程隊列中,調度器從進程隊列中選取下一個被調度的進程。因此如何設計進程隊列是我們研究調度器的一個重要話題。BFS 采用了非常傳統的進程隊列表示方法,即 bitmap 加 queue。
BFS 將所有進程分成 4 類,分別表示不同的調度策略 :
實時進程總能獲得 CPU,采用 Round Robin 或者 FIFO 的方法來選擇同樣優先級的實時進程。他們需要 superuser 的權限,通常限於那些占用 CPU 時間不多卻非常在乎 Latency 的進程。
SCHED_ISO 在主流內核中至今仍未實現,Con 早在 2003 年就提出了這個 patch,但一直無法進入主流內核,這種調度策略是為了那些 near-realtime 的進程設計的。如前所述,實時進程需要用戶有 superuser 的權限,這類進程能夠獨占 CPU,因此只有很少的進程可以被配置為實時進程。對於那些對交互性要求比較高的,又無法成為實時進程的進程,BFS 將采用 SCHED_ISO,這些進程能夠搶占 SCHED_NORMAL 進程。他們的優先級比 SCHED_NORMAL 高,但又低於實時進程。此外當 SCHED_ISO 進程占用 CPU 時間達到一定限度後,會被降級為 SCHED_NORMAL,防止其獨占整個系統資源。
SCHED_NORMAL 類似於主流調度器 CFS 中的 SCHED_OTHER,是基本的分時調度策略。
SCHED_IDELPRO 類似於 CFS 中的 SCHED_IDLE,即只有當 CPU 即將處於 IDLE 狀態時才被調度的進程。
在這些不同的調度策略中,實時進程分成 100 個不同的優先級,加上其他三個調度策略,一共有 103 個不同的進程類型。對於每個進程類型,系統中都有可能有多個進程同時 Ready,比如很可能有兩個優先級為 10 的 RT 進程同時 Ready,所以對於每個類型,還需要一個隊列來存儲屬於該類型的 ready 進程。
BFS 用 103 個 bitmap 來表示是否有相應類型的進程准備進行調度。如下圖所示:
圖 6. BFS 進程隊列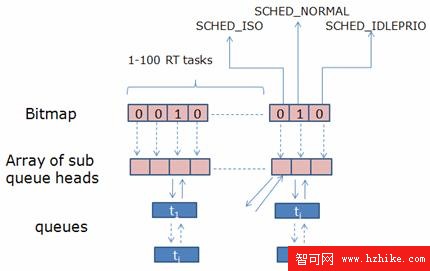
當任何一種類型的進程隊列非空時,即存在 Ready 進程時,相應的 bitmap 位被設置為 1。
調度器如何在這樣一個 bitmap 加 queue 的復雜結構中選擇下一個被調度的進程的問題被稱為 Task Selection 或者 pick next。
Task Selection i.e. Pick Next
當調度器決定進行進程調度的時候,BFS 將按照下面的原則來進行任務的選擇:
圖 7. Task Selection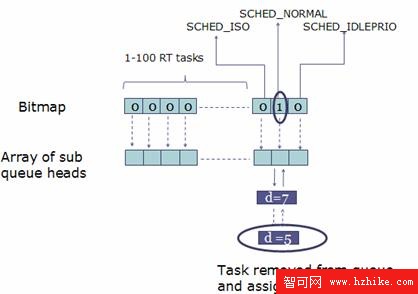
首先查看 bitmap 是否有置位的比特。比如上圖,對應於 SCHED_NORMAL 的 bit 被置位,表明有類型為 SCHED_NORMAL 的進程 ready。如果有 SCHED_ISO 或者 RT task 的比特被置位,則優先處理他們。
選定了相應的 bit 位之後,便需要遍歷其相應的子隊列。假如是一個 RT 進程的子隊列,則選取其中的第一個進程。如果是其他的隊列,那麼就采用 EEVDF 算法來選取合適的進程。
EEVDF,即 earlIEst eligible virtual deadline first。BFS 將遍歷該子隊列,一個雙向列表,比較隊列中的每一個進程的 Virtual Deadline 值,找到最小的那個。最壞情況下,這是一個 O(n) 的算法,即需要遍歷整個雙向列表,假如其中有 n 個進程,就需要進行 n 此讀取和比較。
但實際上,往往不需要遍歷整個 n 個進程,這是因為 BFS 還有這樣一個搜索條件:
當某個進程的 Virtual Deadline 小於當前的 jiffIEs 值時,直接返回該進程。並將其從就緒隊列中刪除,下次再 insert 時會放到隊列的尾部,從而保證每個進程都有可能被選中,而不會出現饑餓現象。
這條規則對應於這樣一種情況,即進程已經睡眠了比較長的時間,以至於已經睡過了它的 Virtual Deadline,如下圖所示:
圖 8. 睡眠和喚醒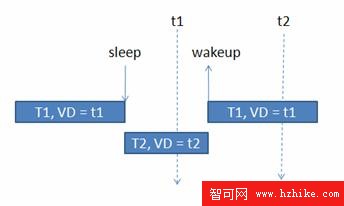
T1 本來的 virtual deadline 為 t1,它 sleep 之後,其他的進程比如 T2 開始運行,等到 T1 再次 wakeup 的時候,當時的 jiffIEs 已經大於 t1,在這種情況下,T1 無需和其他進程的 virtual deadline 相比較,而直接被 BFS 調度器選取。
基本的調度場景
三個基本的 scenario 可以概括多數的調度情景。系統中發生的每一次調度都屬於以下三種情景之一。
進程 wakeup:Task Insertion
睡眠進程 wakeup 時,調度器需要執行 task insertion 的操作,將該進程插入到 run queue 中。BFS 將進程插入相應隊列的操作就是執行一個雙向隊列的插入操作,計算機常用算法結構告訴我們,這個操作是 O(1) 的。不過,BFS 在執行插入操作之前需要首先查看當前進程是否可以搶占當前正在系統中運行的進程。因此它會用新進程的 virtual deadline 值和當前在每個 CPU 上正在運行的進程的 virtual deadline 值進行比較,如果新進程的值小,則直接搶占該 CPU 上正在運行的進程。這個算法是 O(m) 的,其中 m 是 CPU 的個數,假如系統中有 16 個 CPU,那麼每次都需要進行 16 次比較。但這個設計卻保證了非常好的 low-latency 特性。
進程 Sleep
當前正在運行的進程有可能主動睡眠,此時,調度器需要將該進程從 run queue 中移除,並選擇另外一個進程運行。但該進程的 virtual deadline 的值保持不變。
這樣該進程 wakeup 時,其 virtual deadline 將相對較小,因為 jiffIEs 隨著時間流逝而不斷增加。較小的 Virtual Deadline 可以保證該進程能更快得到調度。
仍然以圖 8 為例,系統中有兩個進程,T1 和 T2,T1 進入 sleep 狀態後其 virtual deadline 仍然為 t1。T2 此時被調度,根據公式一,計算得出其 virtual deadline 為 t2。此後,T1 進程 wakeup 了,此時雖然 T2 的時間片尚未用完,但由於 T1 的 virtual deadline 小於 T2 的,(t1<t2),因此 T1 立即得到調度。
進程用完自己的時間片
每個進程都擁有自己的時間片,即使不被其他進程搶占,假如屬於自己的時間片用完時,當前進程也一定會被剝奪 CPU 時間,以便讓別的進程有機會執行。
當前進程的時間片用完後就必須讓出 CPU, 此時將它的 virtual deadline 按照公式一重新計算。
這保證了一個特性:只有其他就緒進程都獲得 CPU 之後,用完當前時間片的進程才可以再次得到運行,這避免了饑餓。
結束語
此時此刻我有一種力不從心之感,介紹似乎不該在此處就戛然截止,但我的確已經講完了我想要講的。唯一能做的,便是想在這裡抓住最後一個機會進行一個小小的總結。
BFS 專注於單一的目標,因此能夠將代碼精簡到極致。它采用單一 Queue,從而免除了 load balance 的需要,雖然並發性減低,但對於少量 CPU 的桌面系統而言,其快速切換 CPU 的能力應該能夠補償並發的損失,說不定還有盈余。
BFS 只關注未來,它完全公平,一個進程的睡眠習慣以及其過去的種種都不能影響它下一次調度的時機。在 BFS 世界中,調度器嚴格按照每個進程的 Deadline 進行公平調度,簡單,嚴肅甚至有些單調。
嗯,我必須承認,無法從這些描述中看出什麼先進的思想或者特性,但廣大用戶的真實體驗說明了那一切。我想,這或許也正說明用於描述桌面交互性的理論基礎還極其缺乏,我只能通過感性而非理性來總結它了。想說的是,我的使用體驗是“快,真的很快”。
或許我並不客觀,人的感受往往受到感情的影響。我認為 Kovalis 得到了不公正的對待,直到我寫這篇文章的今天,主流的內核黑客們還是依然指責 Kovalis,Kovalis 不合群。我想在人群擁擠的咖啡館裡,Kovalis 應該是那個不想也不知道如何表達自己,只能在某個角落裡獨自寫點兒什麼的人吧。這種同情讓我覺得 BFS 更加流暢了?
無論如何,我還是希望能有更多的人關注 BFS,也希望能有更專業的分析和評測。
 使用混合應用程序編程模型為 WebSphere Commerce 構建移動應用程序(2)
使用混合應用程序編程模型為 WebSphere Commerce 構建移動應用程序(2)
可翻頁的產品細節屏幕為增強產品細節屏幕的可用性,我們定義了一個自定義視圖控制器(ProductScrollVIEwController 類)來支持用戶通過翻頁
 聯合使用 HTML 5、地理定位 API 和 Web 服務來創建移動混搭程序
聯合使用 HTML 5、地理定位 API 和 Web 服務來創建移動混搭程序
簡介: 在這個由五個部分所組成的系列的第一部分中,您將接觸到移動 Web 應用程序中最流行的新技術:地理定位。高端智能手機都內置 GPS,現在您將了解 Web
 Android的多媒體框架OpenCore介紹(1)
Android的多媒體框架OpenCore介紹(1)
本文為個人總結,不代表官方觀點。 分為幾個階段: 1、整個android的多媒體框架OpenCore 2、Player和Author的詳細介紹 2、OpenCo
 Android 開發教程之本地數據存儲 API(一)
Android 開發教程之本地數據存儲 API(一)
簡介: 對於需要跨應用程序執行期間或生命期而維護重要信息的應用程序來說,能夠在移動設備上本地存儲數據是一種非常關鍵的功能。作為一名開發人員,您經常需要存儲諸如



