編輯:Android編程入門
PS:最近這兩天發現了Fast Json 感覺實在是強大..
學習內容:
1.什麼是Fast Json
2.如何使用Fast Json
3.Fast Json的相關原理
4.Fast Json的優勢,以及為什麼推薦使用Fast Json
1.Fast Json的相關介紹
說道Json想必我們都不陌生,數據傳輸的兩種形式之一,另一種就是我們的xml了.不過現在更多的還是使用基於Json的格式來進行數據傳輸,Java的api接口為我們提供了相關的api接口用於對Json數據進行處理,如何將數據打包成Json的格式,以及如何將Json數據解析成JavaBean.但是Java內部的api接口雖然可以滿足我們的要求,但是往往能夠滿足要求的不一定就是最好的.
就來說說Fast Json吧.Fast Json是阿裡創建的一款api接口,用於對Json的處理,Fast Json的性能是非常的良好的,解析的速度要超過其他的接口然而他的有點遠遠不止這些,我們來列舉一下他的相關優點吧.
i.首先就是速度上.Fast Json的解析速度是非常高效的,速度快的原因就是使用了優化算法,因此他的速度要遠遠好於其他的api接口.
ii.沒有依賴性,在JDK 5.0開始被正式的啟用,支持Android,支持的數據類型也是非常的多.
多的廢話我也就不多說了,寫這篇文章的主要目的是推薦大家去使用Fast Json。
2.如何使用Fast Json
說道如何使用無非就是如何把現有的數據轉化成Json的格式,以及如何將現有的Json格式的數據解析成我們想要的數據.說白了就是將數據封裝和解析.
我們現在使用Java提供的現有的api接口也可以完成將數據封裝成Json格式的數據,也可以將現有的Json格式數據解析成JsonObject和JsonArray,然後在我們的應用程序中去使用這些數據.但是關於這章我只說一說如何使用Fast Json對數據進行封裝,以及如何將現有的Json格式的數據進行相關的解析.
還是來看一下Fast Json如何在應用當中去使用才是重要的.先說使用方式,然後在說相關的內部原理.
package com.example.FastJson;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
public class Fastjson {
//將List集合中保存的數據轉化成Json類型數據.
public void ListToJson(List<User> list){
String text = JSON.toJSONString(list, true);
System.out.println(text);
}
//將List集合中保存的數據生成多級Json數據..
public void ListToMutiJson(List<User> list){
String text = JSON.toJSONString(list,true);
System.out.println(text);
}
//將數據封裝成Json.
public String toJsonString(){
User user = new User("1", "a", 18);
String text = JSON.toJSONString(user);
System.out.println("toJsonString:將JavaBean轉化成Json數據"+text);
return text;
}
//將現有的Json數據解析成JavaObject對象
public void toParseJson(String text){
JSONObject object = JSON.parseObject(text);
System.out.println("toParseJson:將現有的Json解析成JavaObject"+object);
}
//將JavaBean轉化成Json對象.
public void JavaBeanToJson(User user){
JSONObject jsonObject = (JSONObject) JSON.toJSON(user);
System.out.println("將JavaBean轉化成Json對象"+jsonObject);
}
//將Json對象轉化成JavaBean
public void JsonToJavaBean(String text){
User user = (User) JSON.parseObject(text, User.class);
System.out.println("將Json對象轉化成JavaBean後的數據獲取"+user.getId()+" "+user.getName()+" "+user.getAge());
}
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
Fastjson fastjson = new Fastjson();
String test = fastjson.toJsonString();
fastjson.toParseJson(test);
User user_1 = new User("2","b",19);
fastjson.JavaBeanToJson(user_1);
fastjson.JsonToJavaBean(test);
List<User>lists = new ArrayList<User>();
User user = new User("1", "a", 18);
lists.add(user);
fastjson.ListToJson(lists);
lists.clear();
User user2 = new User("2", "b", 19, new From("中國", "山東省", "淄博市", "張店區"));
lists.add(user2);
fastjson.ListToMutiJson(lists);
}
}
User.java和From.java就是兩個簡單的Java Bean.在這裡我就不進行粘貼了..沒有什麼必要..最後這些數據都會被封裝成Json格式的數據.封裝其實並不是我們想要的..一般而言,我們主要還是針對Json的解析,通過服務器發送來的Json數據,客戶端對其進行解析,然後獲取到服務器的數據,才是最重要的..解析Json數據的方式一般就是通過使用提供的函數,將Json解析成JsonObject或者是JsonArray..然後再將其轉化成JavaBean就可以了
說了這麼多,我們就進行下一個過程,Fast Json解析Json的原理..
3.Fast Json解析Json的原理
說到原理就不得不看源碼了,Fast Json的解析Json的方式源碼有很多種,我就針對將數據解析成Java Bean來說吧.也是非常常用的一個函數..我們來看這個函數.
package com.example.parser;
import org.json.JSONException;
import org.json.JSONObject;
import android.text.TextUtils;
import com.alibaba.fastjson.JSON;
import com.example.vo.Version;
/**
* @author 代碼如風
* 版本解析器
*
* */
public class VersionParser extends BaseParser<Version>{
//解析URL中的JSON數據,將JSON解析成Object
/**
* 1. parseObject 調用 --> public static final <T> T parseObject()
*
* @param String JSON數據
* @param Class class屬性
* @param ParserConfig 解析參數對象實例化
* @param int 參數值
* @param Feature ???
*
* */
@Override
public Version parseJSON(String paramString) throws JSONException {
// TODO Auto-generated method stub
if(!TextUtils.isEmpty(paramString)){
JSONObject j = new JSONObject(paramString);
String version = j.getString("version");
//調用函數,將現有的Json數據解析生成Java Bean
return JSON.parseObject(version, Version.class);
}
return null;
}
}
那麼我就針對JSON.parseObject(version, Version.class)這個函數做一下相關的解析,其他函數大家有興趣的可以去研究研究,原理基本上都是差不多的.
public abstract class JSON implements JSONStreamAware, JSONAware{
public static final int DEFAULT_PARSER_FEATURE;
public static final int DEFAULT_GENERATE_FEATURE;
public static CharsetDecoder UTF8_CharsetEncoder;
static {
//默認解析方式,將Feature的一些相關屬性進行疊加..
int features = 0;
features |= Feature.AutoCloseSource.getMask();
features |= Feature.InternFieldNames.getMask();
features |= Feature.UseBigDecimal.getMask();
features |= Feature.AllowUnQuotedFieldNames.getMask();
features |= Feature.AllowSingleQuotes.getMask();
features |= Feature.AllowArbitraryCommas.getMask();
features |= Feature.SortFeidFastMatch.getMask();
features |= Feature.IgnoreNotMatch.getMask();
DEFAULT_PARSER_FEATURE = features;
//默認生成的一些屬性.
int features = 0;
features |= SerializerFeature.QuoteFieldNames.getMask();
features |= SerializerFeature.SkipTransientField.getMask();
features |= SerializerFeature.SortField.getMask();
DEFAULT_GENERATE_FEATURE = features;
UTF8_CharsetEncoder = new UTF8Decoder();
}
/** 中間一堆 .....*/
//源碼中調用的方法...
public static final <T> T parseObject(String text, Class<T> clazz) {
//添加了一個Feature屬性
return parseObject(text, clazz, new Feature[0]);
}
//進一步的封裝
public static final <T> T parseObject(String text, Class<T> clazz, Feature[] features){
//添加解析的相關配置,解析的方式,以及Feature的額外屬性信息
return parseObject(text, clazz, ParserConfig.getGlobalInstance(), DEFAULT_PARSER_FEATURE, features);
}
public static final <T> T parseObject(String input, Type clazz, ParserConfig config, int featureValues, Feature[] features){
//如果解析的數據為空,那麼返回空.
if (input == null) {
return null;
}
//遍歷Feature數組,將這些值進行疊加..最後生成一個FeatureValue.
for (Feature featrue : features) {
featureValues = Feature.config(featureValues, featrue, true);
}
//設置Json的解析方式.實例化DefaultExtJSONParser
DefaultExtJSONParser parser = new DefaultExtJSONParser(input, config, featureValues);
//真正的解析過程.
Object value = parser.parseObject(clazz);
//如果clazz != JSONArray的字節碼文件..關閉解析
if (clazz != JSONArray.class) {
parser.close();
}
return value;
}
}
以上就是將Json數據轉化成Java Bean的源碼調用過程.我們再來具體的分析一下..因為裡面還是涉及到了很多的內容..我們可以看到在解析的時候並不是一步就直接完成的..中間過程需要封裝相關的數據才能夠對Json進行解析.首先就是Feature的封裝.
Feature是一個枚舉類型..它繼承了Enum類..也就意味著這個枚舉類型不能被繼承,同樣,枚舉變量也是有限且固定的.並且創建一個枚舉類型是線程安全的.更重要的一點就是枚舉在進行序列化操作的時候能夠保持單列模式..說白了就是在序列化和反序列化操作的時候保證操作的是同一個對象,也就不至於在序列化的時候針對的是當前這個對象,而在反序列化的時候需要重新new一個新的對象..
/* */ package com.alibaba.fastjson.parser;
/* */
/* */ public enum Feature
/* */ {
/* 22 */ AutoCloseSource,
/* */
/* 26 */ AllowComment,
/* */
/* 30 */ AllowUnQuotedFieldNames,
/* */
/* 34 */ AllowSingleQuotes,
/* */
/* 38 */ InternFieldNames,
/* */
/* 42 */ AllowISO8601DateFormat,
/* */
/* 47 */ AllowArbitraryCommas,
/* */
/* 52 */ UseBigDecimal,
/* */
/* 57 */ IgnoreNotMatch,
/* */
/* 62 */ SortFeidFastMatch,
/* */
/* 67 */ DisableASM;
/* */
/* */ private final int mask;
/* */
//將枚舉常量的序數左移一位.
/* */ private Feature()
/* */ {
/* 74 */ this.mask = (1 << ordinal());
/* */ }
/* */ //返回mask..
/* */ public final int getMask()
/* */ {
/* 80 */ return this.mask;
/* */ }
/* */
/* */ public static boolean isEnabled(int features, Feature feature) {
/* 84 */ return (features & feature.getMask()) != 0;
/* */ }
/* */
//JSON源代碼中調用的方法.將默認的屬性與Feature的額外屬性進行封裝.
/* */ public static int config(int features, Feature feature, boolean state) {
/* 88 */ if (state)
/* 89 */ features |= feature.getMask();
/* */ else {
/* 91 */ features &= (feature.getMask() ^ 0xFFFFFFFF);
/* */ }
/* */
/* 94 */ return features;
/* */ }
/* */ }
這就是Feature的源代碼..內部封裝了一些枚舉類型的變量..主要針對於Json的數據解析,Feature按照我自己的理解其實就是在解析Json或者是封裝成Json時的特配置,我們可以看到在Json類中添加了Feature屬性特征..最後將默認的一些特征與Feature的其他額外特征進行封裝..最後進行解析或者打包..還要說一點就是還有一個是SerializerFeature屬性..序列化屬性,也是一個枚舉類型..它其實也是針對Json的一些額外特征配置(比如說在Json中支持以雙引號的形式將數據括起來等等)..
解析就是通過實例化DefaultExtJSONParser對象開始,然後通過調用相關的方法對Json進行解析..通過使用parseObject方法來完成解析..解析的過程也是Fast Json優化的最大的地方..也就導致了他的解析速度要超過其他api接口對Json數據解析的速度.
public <T> T parseObject(Type type){
if (this.lexer.token() == 8) {
this.lexer.nextToken();
return null;
}
ObjectDeserializer derializer = this.config.getDeserializer(type);
try{
return derializer.deserialze(this, type);
}catch (JSONException e) {
throw e;
}catch (Throwable e) {
throw new JSONException(e.getMessage(), e);
}
}
這就是解析的源代碼..其實看似非常的簡單..實際上Fast Json在這個地方優化的地方非常的多,也就導致了其解析Json的速度是非常高效的.那麼我們就來看看Fast Json為何比較高效。。
4.Fast Json高效的原因,為什麼推薦使用Fast Json
Fast json高效自然而然是有它的原因的..我主要針對幾點來說說..因為我並沒有完全的看完Fast Json的源碼..只是自己的一些見解,說的也就不是非常的全面..
1. 使用SerializeWriter
將數據封裝成Json的時候使用SerializerWriter來完成,通過對字符串的追加將數據轉換成Json字串.並且其內部提供了一些優化針對減少數組越界的判斷.(減少了越界的判斷確實能夠提高一部分效率)
ThreadLocal來緩存buf,寫入數據必然需要使用緩存來存放字符串的內存地址,但是每次序列化的時候都需要重新分配buf的內存空間,為了避免多次申請內存空間以及gc的調用,因此將內存保存到了ThreadLocal中,當再次進行序列化的時候只需要從ThreadLocal中取出內存就可以了.
並且ThreadLocal不僅僅可以緩存內存地址,當我們對Json數據進行解析的時候也會使用到它提供的緩存..當我們在解析Json的時候,我們讀取到的key值可以被保存在一個叫sbuf的緩沖區中,只要這個緩沖區不被釋放掉,那麼再次讀取的時候只需要從緩沖中讀取到相關的字符串序列即可,沒必要去new一個新的字符串對象,從而導致內存空間的開辟以及不必要的gc調用..
2.使用asm來避免反射機制的使用
asm不是一個算法,它是字節碼框架技術,它可以避免使用Java中的反射機制從而獲取到一個類中的所有成員變量和方法,反射機制同樣也可以實現,但是反射機制的一大弊病就是耗費時間.使用反射中間會生成大量的臨時變量從而導致gc的頻繁調用.(避免了反射的使用,自然性能上也有了一定的優化) 至於asm技術我沒有進行徹底的研究..可能以後會寫..有興趣的大家可以自己去研究研究..
3.使用IdentityHashMap去優化性能.
因為Fast Json每種類型都對應一種解析方式,也就出現了<class,JavaBeanSerializer>的映射關系,那麼映射自然就需要使用有映射關系的集合,也就是HashMap<K,V>,但是HashMap並不是線程安全的,也就是在並發環境下會導致死循環的出現.因此在並發情況下我們就需要ConcurrentHashMap,但是比HashMap的性能要差,因為需要使用lock()等方法控制多線程的安全問題.安全就失去了效率,因此IndentityHashMap集合就在Fast Json中開發.他的內部去除了transfer方法,使得它能夠在並發的情況下也能保證安全性.同樣效率也就不會受到影響。
4.Deserializer的主要優化算法..
Deserializer也成為反序列化過程,也就是將Json數據轉化成Java Bean形式.也是優化精力最多的地方.
基於token的預測分析:
解析Json 需要使用到詞法處理,Fast Json使用了基於預測的詞法分析方式,比如說:比如key之後,最大的可能是冒號":",value之後,可能是有兩個,逗號","或者右括號"}" 這樣的預測分析。
public void nextToken(int expect) {
/* */ while (true) {
/* 297 */ switch (expect)
/* */ {
/* */ case 12:
/* 299 */ if (this.ch == '{') {
/* 300 */ this.token = 12;
/* 301 */ this.ch = this.buf[(++this.bp)];
/* 302 */ return;
/* */ }
/* 304 */ if (this.ch == '[') {
/* 305 */ this.token = 14;
/* 306 */ this.ch = this.buf[(++this.bp)];
/* 307 */ return;
/* */ }
/* */ case 16:
/* 311 */ if (this.ch == ',') {
/* 312 */ this.token = 16;
/* 313 */ this.ch = this.buf[(++this.bp)];
/* 314 */ return;
/* */ }
/** 中間一堆....*/
if ((this.ch != ' ') && (this.ch != '\n') && (this.ch != '\r') && (this.ch != '\t') && (this.ch != '\f') && (this.ch != '\b')) break;
/* 419 */ this.ch = this.buf[(++this.bp)];
/* */ }
/* */
/* 423 */ nextToken();
/* */ }
預測分析的源代碼就是上面粘貼的,只是粘貼了一部分,其實就是對下一個token的預測判斷,這樣可以幫助我們盡最快的速度拿到token..簡單的說一下token的概念..
//這是一個Json字串..其中token單引號引起的部分每一個單引號引起的部分就是一個token這裡一共有13個token..
{ "id" : 123, "name" : "aa", "salary" : 56789} //json字串
'{' ' "id" ' ':' '123' ',' ' "name" ' ':' ' "aa" ' ',' ' "salary" ' ':' '56789' '}'
這樣token的概念就沒那麼難理解了..
5.Sort field fast match算法
Fast Json在封裝和解析的時候都是默認使用這個算法的,就是以有序的方式將Json 字符串進行保存,如果數據保存的形式是有序的,那麼就使用優化算法,不用對每一個token進行處理..只需要處理一部分的token就可以了..也正是因為這個原因,使得Fast Json在解析Json的時候可以減少50%的token...這樣效率上就有了空前的變化...如果不是有序的我們就需要一個一個進行分析了,然後從中取出key對應的value值.
就那上面那條Json數據來說吧,如果key值是有序的,那麼只需要處理6個token就可以了,但是如果是無序的,就需要處理13個token..處理13個token不難理解..就是對掃描整個字符串,然後處理每一個token不就完事了..但是如果是有序的,那麼為什麼只需要處理6個token呢?我看了很多人的博客都沒有對這塊進行講解..也就使得我也非常的迷茫..
我自己的理解是這樣的:其實對不對我自己也不是非常的確定..(如果不對,大家請指出)
之所以只需要處理6個token就是只需要對key和value值進行處理,三對key,value對應的也是6個token,因為我們使用了預測分析,那麼自然而然就知道了Json的數據格式,有了這個數據格式,那麼那些符號類的token就可以直接跨越過去,我們已經匹配到了key那麼自然就預測到key後面有一個","那麼這個","我們就不需要處理了,只需要處理","後面的value了..因此符號類的token是沒必要處理的,但是為什麼要有序,因為我們是將每一條的Json數據轉化成字符數組的形式,在匹配key值的時候我們是按照字符數組進行匹配,如果每一條的順序都不一樣,那麼就不能使用一條規則去使者多條數據遵循這一個原則進行解析..因此才進行排序,可以減少對token的讀取和處理..(個人理解..不對的話,請指出..)
這也就是Fast Json迅速的原因..自然有很多地方的東西沒說到..Fast Json說是最快..是不是最快我們說了不算,但是Fast Json確實融入了很多的思想..還是很不錯的一個解析Json的api接口..
至於用不用取決於大家..也沒必要去爭執誰解析Json最快..沒什麼意義..
原本其實想深入的研究一下,總結一下所有的原因和思想..但是看到很多人寫的東西都是九牛一毛..抄來抄去的..沒寫出核心的東西..等自己真正有時間的時候再去解讀一下源碼再深入的寫吧..
PS:最後只是吐槽一下..如果有人看著不爽..請不要噴我..謝謝!
最後說一下自己學這塊的感悟:說實話之所以在Sort Field Fast match算法不是很明白的原因就是沒有看到關於這塊寫的非常優秀的文章,看了挺多人的文章,看著是很厲害,但是寫出來的東西大部分都是不清不楚,不明不白,我可以理解使用大量的專業術語(其實就是不說人話)..有的呢就是直接把人家寫的東西直接粘貼過去,估計自己都沒理解到底是怎麼一回事..搬別人的東西不是不可以,只是在搬的時候我們也去想一想,最後結合我們自己的思想寫到博客上,那才叫自己真正的學了,博文裡才有自己的思想..直接抄來抄去,連改都不改動一下...真的很沒意思..
感覺真的挺無力的,Sort這塊糾結了很長時間到底要不要寫出來,就怕誤人子弟...很多博文寫的東西只是寫一個開頭,就拿這個算法為什麼只處理了6個token,沒有什麼過多的解釋,什麼是asm也沒有什麼過多的解釋..(一開始還以為asm是算法,結果查了一下asm算法和圖像處理有關,很明顯就弄錯了,後來才明白asm是字節碼框架技術)..雖然我自己很菜..但是我能保證每一篇文章都是用很大的心思去寫,自己心安就行...
 Android應用的閃退(crash)分析
Android應用的閃退(crash)分析
阿裡客戶端工程師試題簡析——Android應用的閃退(crash)分析1. 問題描述 閃退(Crash)是客戶端程序在運行時遭遇無法處理的異常或
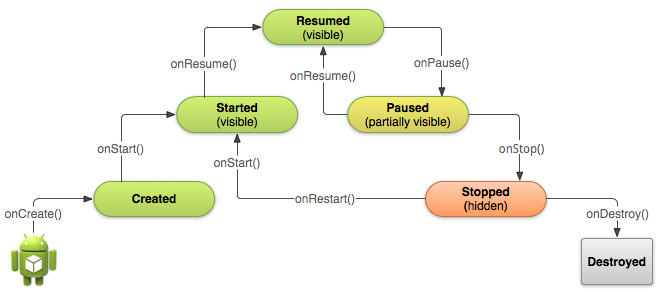 Android Activity的生命周期簡單總結
Android Activity的生命周期簡單總結
Android Activity的生命周期簡單總結這裡的內容參考官方的文檔,這篇文章的目的不是去總結Activity是如何啟動,如何創造,以及暫停和銷毀的,而是從實際開發
 如何開發Android Wear應用程序
如何開發Android Wear應用程序
Android Wear是連接安卓手機和可穿戴產品的一個平台。自從今年上半年發布以來,Android Wear獲得了大量關注,既有來自消費者的關注,也有來自開發商的關注,
 Android 5.0+刪除Sdcard文件
Android 5.0+刪除Sdcard文件
在Android5.0往後的平台上,你想通過單純的調用File.delete()或著ContentResolver.delete()來刪除Sdcard上的文件會刪除失敗。