編輯:Android資訊
為了進行代碼及產品保護,幾乎所有的非開源App都會進行代碼混淆。這樣,當收集到崩潰信息後,就需要進行符號化來還原代碼信息,以便開發者可以定 位Bug。基於使用SDK和NDK的不同,Android的崩潰分為兩類:Java崩潰和C/C++崩潰。Java崩潰通過mapping.txt文件進 行符號化,比較簡單直觀。而C/C++崩潰的符號化則需要使用Google自帶的一些NDK工具,比如ndk-stack、addr2line、 objdump等。本文不去討論如何使用這些工具,有興趣的朋友可以參考之前尹春鵬寫的另一篇文章《 如何定位Android NDK開發中遇到的錯誤》,裡面做了詳細的描述。
基於NDK的Android開發都會生成一個動態鏈接庫(so),它是基於C/C++編譯生成的。動態鏈接庫在Linux系統下廣泛使用,而Android系統底層是基於Linux的,所以NDK so庫的編譯生成遵循相同的規則,只不過Google NDK把相關的交叉編譯工具都封裝了。
Ndk-build編譯時會生成的兩個同名的so庫,位於不同的目錄/project path/libs/armeabi/xxx.so和/project path/obj/local/armeabi/xxx.so,比較兩個so文件會發現體積相差很大。前者會跟隨App一起發布,所以盡可能地小,而後者包含了很多調試信息,主要為了gdb調試的時候使用,當然,NDK的日志符號化信息也包含其中。

本文主要針對這個包含調試信息的so動態庫,深入分析它的組成結構。在開始之前,先來說說這樣做的目的或者好處。現在的App基本都會采集 上報崩潰時的日志信息,無論是采用第三方雲平台,還是自己搭建雲服務,都要將含調試信息的so動態庫上傳,實現雲端日志符號化以及雲端可視化管理。
移動App的快速迭代,使得我們必須存儲管理每一個版本的debug so庫,而其包含了很多與符號化無關的信息。如果我們只提取出符號化需要的信息,那麼符號化文件的體積將會呈現數量級的減少。同時可以在自定義的符號化文 件中添加App的版本號等定制化信息,實現符號化提取、上傳到雲端、雲端解析及可視化等自動化部署。另外,從技術角度講,開發者將不再害怕看到 “unresolved symbol” linking errors,可以更從容地debugging C/C++ crash或進行一些hacking操作。
首先通過readelf來看看兩個不同目錄下的so庫有什麼不同。
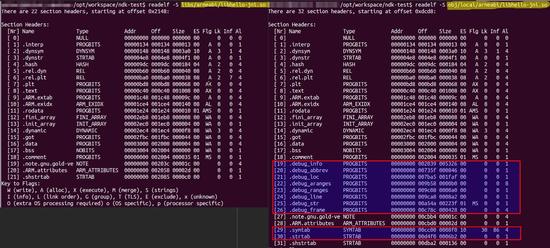
從中可以清楚看到,包含調試信息的so庫多了8個.debug_開頭的條目以及.symtab和.strtab條目。符號化的本質,是通過堆棧中的地址信息,還原代碼本來的語句以及相應的行號,所以這裡只需解析.debug_ line和.symtab,最終獲取到如下的信息就可以實現符號化了。
c85 c8b willCrash jni/hello-jni.c:27-29 c8b c8d willCrash jni/hello-jni.c:32 c8d c8f JNI_OnLoad jni/hello-jni.c:34 c8f c93 JNI_OnLoad jni/hello-jni.c:35 c93 c9d JNI_OnLoad jni/hello-jni.c:37
通常,目標文件分為三類:relocatable文件、executable文件和shared object文件,它們格式稱為ELF(Executable and Linking Format),so動態庫屬於第三類shared object,它的整體組織結構如下:

ELF Header文件頭的結構如下,記錄了文件其他內容在文件中的偏移以及大小信息。這裡以32bit為例:
typedef struct {
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type; // 目標文件類型,如relocatable、executable和shared object
Elf32_Half e_machine; // 指定需要的特定架構,如Intel 80386,Motorola 68000
Elf32_Word e_version; // 目標文件版本,通e_ident中的EI_VERSION
Elf32_Addr e_entry; // 指定入口點地址,如C可執行文件的入口是_start(),而不是main()
Elf32_Off e_phoff; // program header table 的偏移量
Elf32_Off e_shoff; // section header table的偏移量
Elf32_Word e_flags; // 處理器相關的標志
Elf32_Half e_ehsize; // 代表ELF Header部分的大小
Elf32_Half e_phentsize; // program header table中每一項的大小
Elf32_Half e_phnum; // program header table包含多少項
Elf32_Half e_shentsize; // section header table中每一項的大小
Elf32_Half e_shnum; // section header table包含多少項
Elf32_Half e_shstrndx; //section header table中某一子項的index,該子項包含了所有section的字符串名稱
} Elf32_Ehdr;
其中e_ident為固定16個字節大小的數組,稱為ELF Identification,包含了處理器類型、文件編碼格式、機器類型等,具體結構如下:

該部分包含了除ELF Header、program header table以及section header table之外的所有信息。通過section header table可以找到每一個section的基本信息,如名稱、類型、偏移量等。
先來看看Section Header的內容,仍以32-bit為例:
typedef struct {
Elf32_Word sh_name; // 指定section的名稱,該值為String Table字符串表中的索引
Elf32_Word sh_type; // 指定section的分類
Elf32_Word sh_flags; // 該字段的bit代表不同的section屬性
Elf32_Addr sh_addr; // 如果section出現在內存鏡像中,該字段表示section第一個字節的地址
Elf32_Off sh_offset; // 指定section在文件中的偏移量
Elf32_Word sh_size; // 指定section占用的字節大小
Elf32_Word sh_link; // 相關聯的section header table的index
Elf32_Word sh_info; // 附加信息,意義依賴於section的類型
Elf32_Word sh_addralign; // 指定地址對其約束
Elf32_Word sh_entsize; // 如果section包含一個table,該值指定table中每一個子項的大小
} Elf32_Shdr;
通過Section Header的sh_name可以找到指定的section,比如.debug_line、.symbol、.strtab。
String Table包含一系列以/0結束的字符序列,最後一個字節設置為/0,表明所有字符序列的結束,比如:

String Table也屬於section,只不過它的偏移量直接在ELF Header中的e_shstrndx字段指定。String Table的讀取方法是,從指定的index開始,直到遇到休止符。比如要section header中sh_name獲取section的名稱,假設sh_name = 7, 則從string table字節流的第7個index開始(注意這裡從0開始),一直讀到第一個休止符(index=18),讀取到的名稱為.debug_line。
該部分包含了程序符號化的定義相關信息,比如函數定義、變量定義等,每一項的定義如下:
# Symbol Table Entry
typedef struct {
Elf32_Word st_name; //symbol字符串表的索引
Elf32_Addr st_value; //symbol相關的值,依賴於symbol的類型
Elf32_Word st_size; //symbol內容的大小
unsigned char st_info; //symbol的類型及其屬性
unsigned char st_other; //symbol的可見性,比如類的public等屬性
Elf32_Half st_shndx; //與此symbol相關的section header的索引
} Elf32_Sym;
Symbol的類型包含以下幾種:
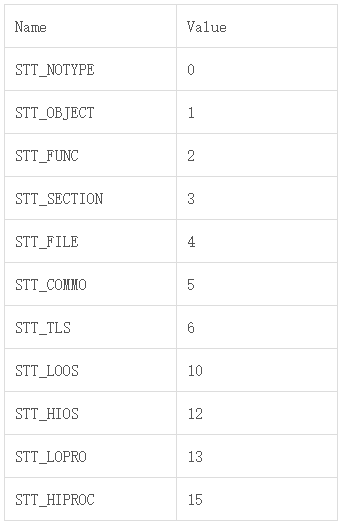
其中STT_FUNC就是我們要找的函數symbol。然後通過st_name從symbol字符串表中獲取到相應的函數名(如 JNI_OnLoad)。當symbol類型為STT_FUNC時,st_value代表該symbol的起始地址,而 (st_value+st_size)代表該symbol的結束地址。
回顧之前提到的.symtab和.strtab兩個部分,對應的便是Symbol Section和Symbol String Section。
DWARF是一種調試文件格式,很多編譯器和調試器都通過它進行源碼調試(gdb等)。盡管它是一種獨立的目標文件格式,但往往嵌入在ELF文件中。前面通過readelf看到的8個.debug_* Section全部都屬於DWARF格式。本文將只討論與符號化相關的.debug_line部分,更多的DWARF信息請查看參考文獻的內容。
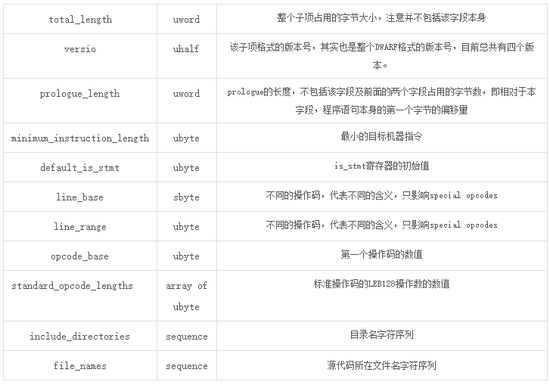
.debug_line部分包含了行號信息,通過它可以將代碼語句和機器指令地址對應,從而進行源碼調試。.debug_line由很多子項組成,每個子項都包含類似數據塊頭的描述,稱為Statement Program Prologue。Prologue提供了解碼程序指令和跳轉到其他語句的信息,它包含如下字段,這些字段是以二進制格式順序存在的:
這裡用到的機器指令可以分為三類:

這裡不做機器指令的解析說明,感興趣的,可以查看參考文獻的內容。
通過.debug_line,我們最終可以獲得如下信息:文件路徑、文件名、行號以及起始地址。
最後,我們匯總一下整個符號化提取的過程:
作者簡介:
賈志凱 Testin技術總監,主要負責崩潰分析項目Android平台架構設計、性能及穩定性優化。
 Android UI控件系列:Dialog(對話框)
Android UI控件系列:Dialog(對話框)
對話框是Android中不可或缺的,在使用對話框的時候,需要使用AlertDialog.Builder類。當然處理系統默認的對話框外,還可以自定義對話框,如果對話
 高質量 Android 開發框架 LoonAndroid 詳解
高質量 Android 開發框架 LoonAndroid 詳解
整個框架式不同於androidannotations,Roboguice等ioc框架,這是一個類似spring的實現方式。在整應用的生命周期中找到切入點,然後對a
 Android動態高斯模糊效果教程
Android動態高斯模糊效果教程
寫在前面 最近一直在做畢設項目的准備工作,考慮到可能要用到一個模糊的效果,所以就學習了一些高斯模糊效果的實現。比較有名的就是 FastBlur 以及它衍生的一些優
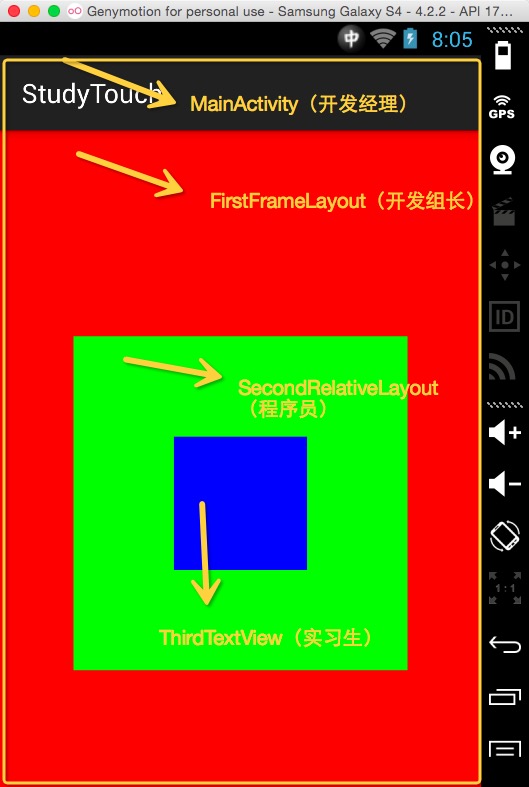 Android Touch事件傳遞機制通俗講解
Android Touch事件傳遞機制通俗講解
在講正題之前我們講一段有關任務傳遞的小故事,拋磚迎玉下: 話說一家軟件公司,來一個任務,分派給了開發經理去完成: 開發經理拿到,看了一下,感覺好簡單,於是 開發