編輯:Android資訊
Binder的實現是比較復雜的,想要完全弄明白是怎麼一回事,並不是一件容易的事情。
這裡面牽涉到好幾個層次,每一層都有一些模塊和機制需要理解。這部分內容預計會分為三篇文章來講解。本文是第一篇,首先會對整個Binder機制做一個架構性的講解,然後會將大部分精力用來講解Binder機制中最核心的部分:Binder驅動的實現。
Binder源自Be Inc公司開發的OpenBinder框架,後來該框架轉移的Palm Inc,由Dianne Hackborn主導開發。OpenBinder的內核部分已經合入Linux Kernel 3.19。
Android Binder是在OpneBinder上的定制實現。原先的OpenBinder框架現在已經不再繼續開發,可以說Android上的Binder讓原先的OpneBinder得到了重生。
Binder是Android系統中大量使用的IPC(Inter-process communication,進程間通訊)機制。無論是應用程序對系統服務的請求,還是應用程序自身提供對外服務,都需要使用到Binder。
因此,Binder機制在Android系統中的地位非常重要,可以說,理解Binder是理解Android系統的絕對必要前提。
在Unix/Linux環境下,傳統的IPC機制包括:
等。
由於篇幅所限,本文不會對這些IPC機制做講解,有興趣的讀者可以參閱《UNIX網絡編程 卷2:進程間通信》。
Android系統中對於傳統的IPC使用較少(但也有使用,例如:在請求Zygote fork進程的時候使用的是Socket IPC),大部分場景下使用的IPC都是Binder。
Binder相較於傳統IPC來說更適合於Android系統,具體原因的包括如下三點:
Binder整體架構如下所示:
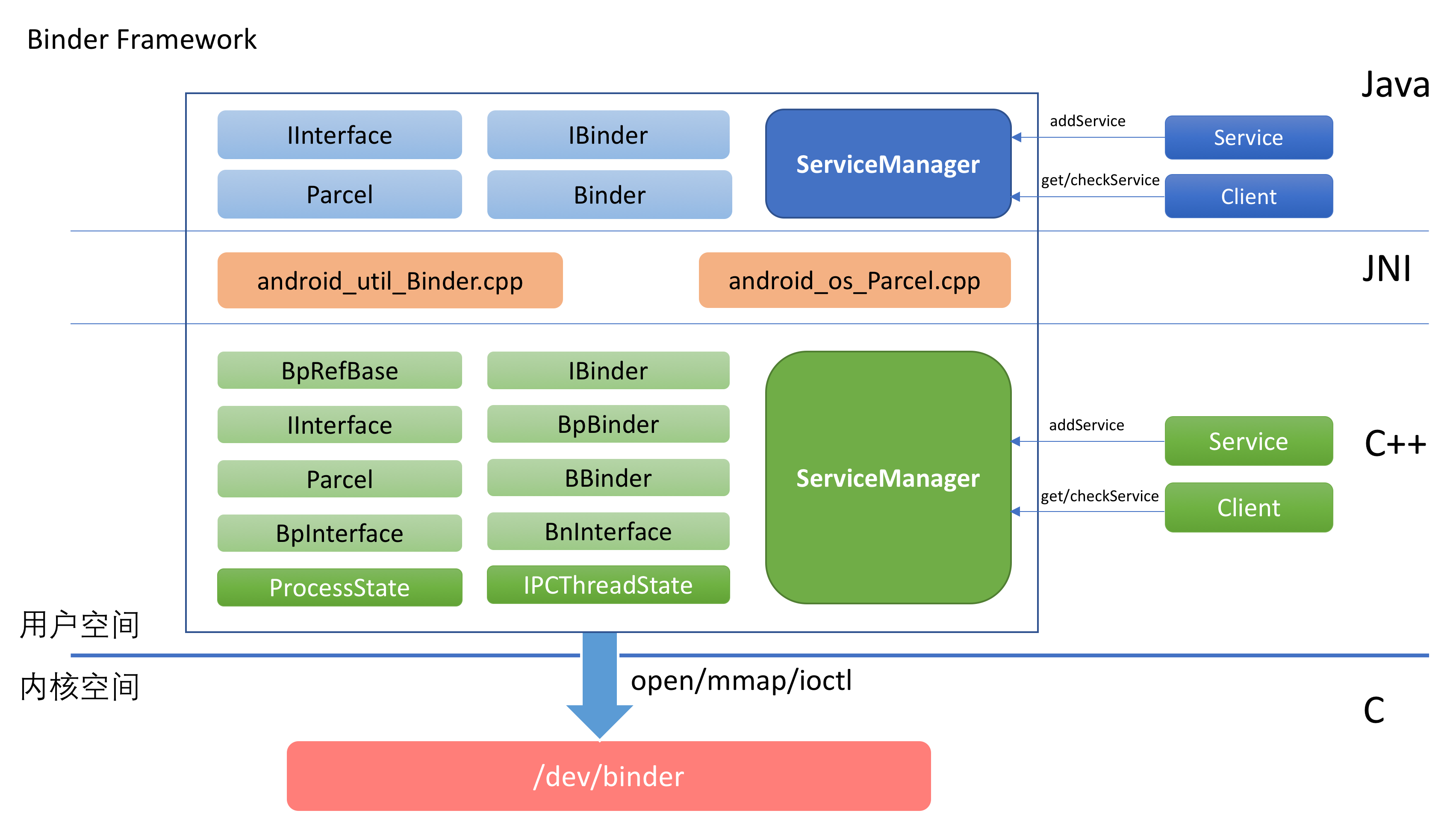
從圖中可以看出,Binder的實現分為這麼幾層:
驅動層位於Linux內核中,它提供了最底層的數據傳遞,對象標識,線程管理,調用過程控制等功能。驅動層是整個Binder機制的核心。
Framework層以驅動層為基礎,提供了應用開發的基礎設施。
Framework層既包含了C++部分的實現,也包含了Java部分的實現。為了能將C++的實現復用到Java端,中間通過JNI進行銜接。
開發者可以在Framework之上利用Binder提供的機制來進行具體的業務邏輯開發。其實不僅僅是第三方開發者,Android系統中本身也包含了很多系統服務都是基於Binder框架開發的。
既然是“進程間”通訊就至少牽涉到兩個進程,Binder框架是典型的C/S架構。在下文中,我們把服務的請求方稱之為Client,服務的實現方稱之為Server。
Client對於Server的請求會經由Binder框架由上至下傳遞到內核的Binder驅動中,請求中包含了Client將要調用的命令和參數。請求到了Binder驅動之後,在確定了服務的提供方之後,會再從下至上將請求傳遞給具體的服務。整個調用過程如下圖所示:
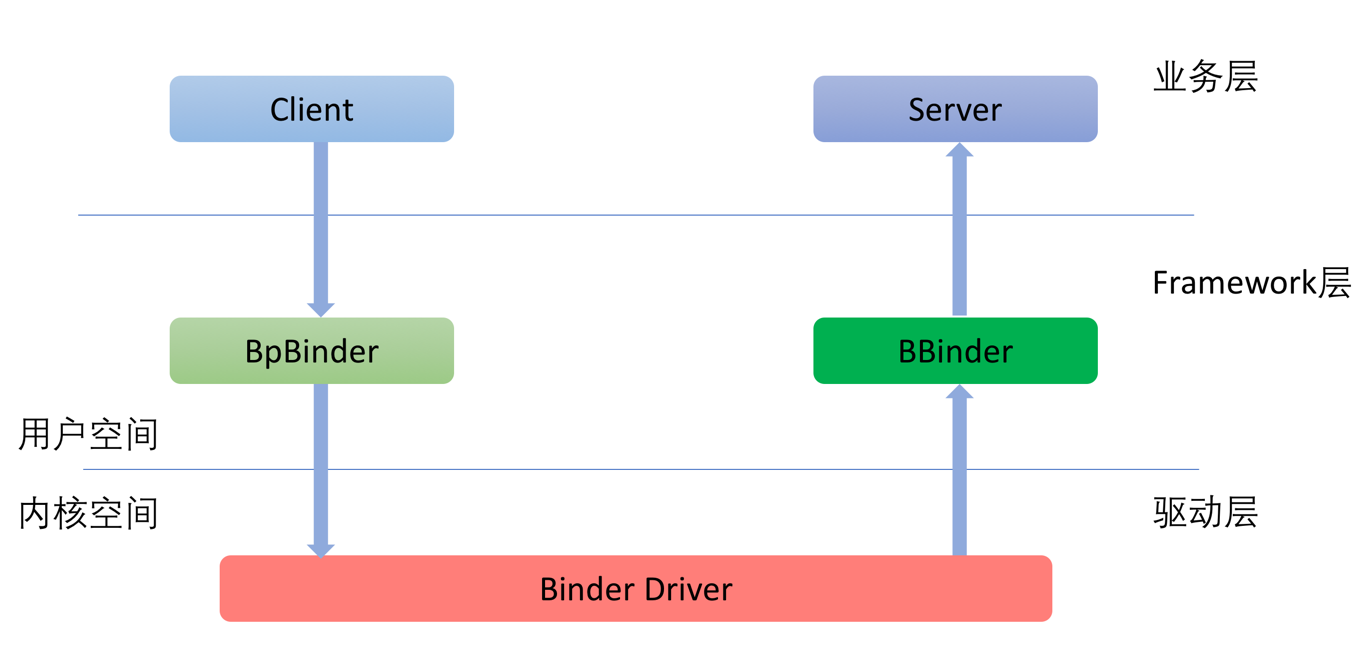
對網絡協議有所了解的讀者會發現,這個數據的傳遞過程和網絡協議是如此的相似。
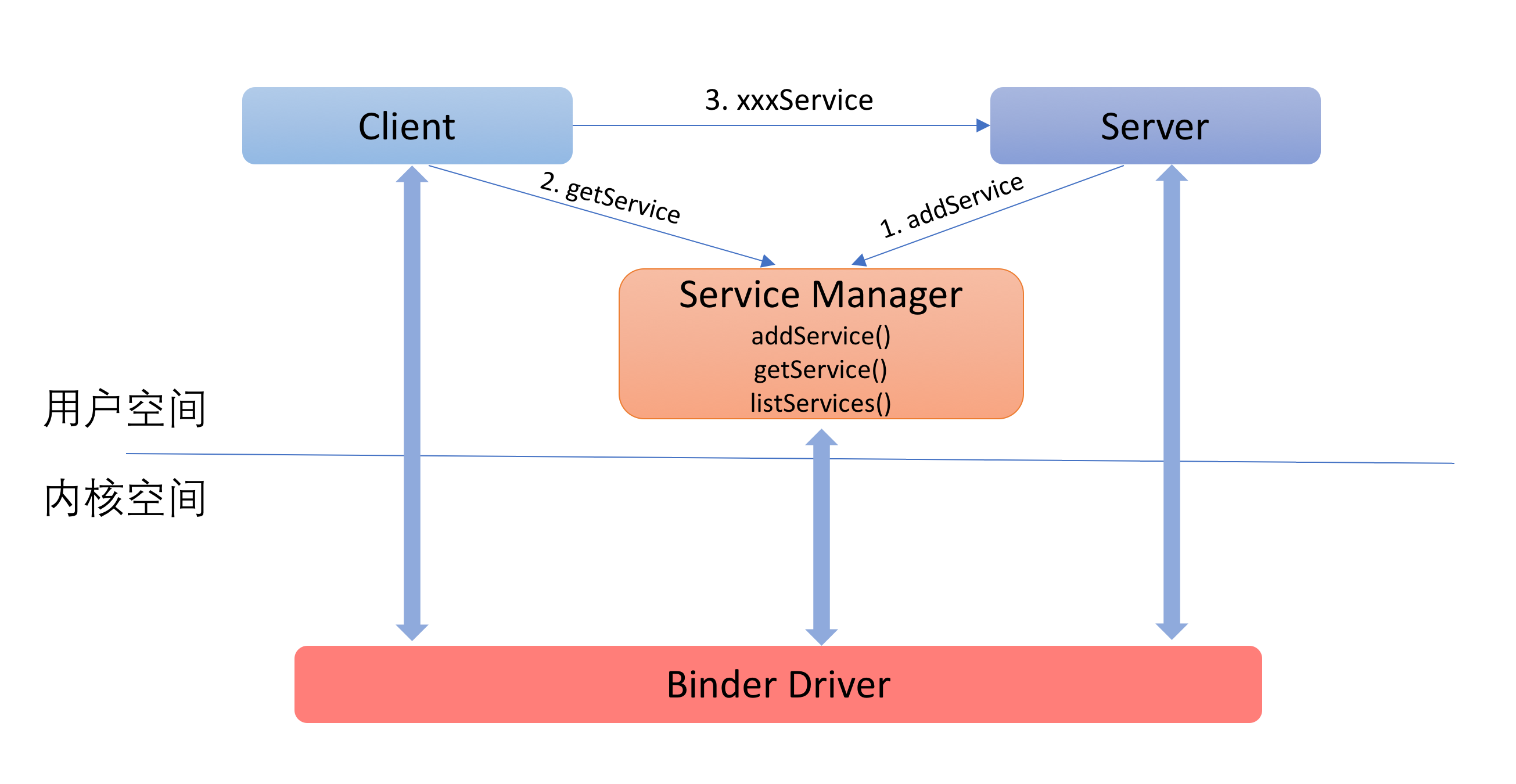
前面已經提到,使用Binder框架的既包括系統服務,也包括第三方應用。因此,在同一時刻,系統中會有大量的Server同時存在。那麼,Client在請求Server的時候,是如果確定請求發送給哪一個Server的呢?
這個問題,就和我們現實生活中如何找到一個公司/商場,如何確定一個人/一輛車一樣,解決的方法就是:每個目標對象都需要一個唯一的標識。並且,需要有一個組織來管理這個唯一的標識。
而Binder框架中負責管理這個標識的就是ServiceManager。ServiceManager對於Binder Server的管理就好比車管所對於車牌號碼的的管理,派出所對於身份證號碼的管理:每個公開對外提供服務的Server都需要注冊到ServiceManager中(通過addService),注冊的時候需要指定一個唯一的id(這個id其實就是一個字符串)。
Client要對Server發出請求,就必須知道服務端的id。Client需要先根據Server的id通過ServerManager拿到Server的標示(通過getService),然後通過這個標示與Server進行通信。
整個過程如下圖所示:
如果上面這些介紹已經讓你一頭霧水,請不要過分擔心,下面會詳細講解這其中的細節。
下文會以自下而上的方式來講解Binder框架。自下而上未必是最好的方法,每個人的思考方式不一樣,如果你更喜歡自上而下的理解,你也按這樣的順序來閱讀。
對於大部分人來說,我們可能需要反復的查閱才能完全理解。
源碼路徑(這部分代碼不在AOSP中,而是位於Linux內核代碼中):
/kernel/drivers/android/binder.c /kernel/include/uapi/linux/android/binder.h
或者
/kernel/drivers/staging/android/binder.c /kernel/drivers/staging/android/uapi/binder.h
Binder機制的實現中,最核心的就是Binder驅動。 Binder是一個miscellaneous類型的驅動,本身不對應任何硬件,所有的操作都在軟件層。 binder_init函數負責Binder驅動的初始化工作,該函數中大部分代碼是在通過debugfs_create_dir和debugfs_create_file函數創建debugfs對應的文件。 如果內核在編譯時打開了debugfs,則通過adb shell連上設備之後,可以在設備的這個路徑找到debugfs對應的文件:/sys/kernel/debug。Binder驅動中創建的debug文件如下所示:
# ls -l /sys/kernel/debug/binder/ total 0 -r--r--r-- 1 root root 0 1970-01-01 00:00 failed_transaction_log drwxr-xr-x 2 root root 0 1970-05-09 01:19 proc -r--r--r-- 1 root root 0 1970-01-01 00:00 state -r--r--r-- 1 root root 0 1970-01-01 00:00 stats -r--r--r-- 1 root root 0 1970-01-01 00:00 transaction_log -r--r--r-- 1 root root 0 1970-01-01 00:00 transactions
這些文件其實都在內存中的,實時的反應了當前Binder的使用情況,在實際的開發過程中,這些信息可以幫忙分析問題。例如,可以通過查看/sys/kernel/debug/binder/proc目錄來確定哪些進程正在使用Binder,通過查看transaction_log和transactions文件來確定Binder通信的數據。
binder_init函數中最主要的工作其實下面這行:
ret = misc_register(&binder_miscdev);
該行代碼真正向內核中注冊了Binder設備。binder_miscdev的定義如下:
static struct miscdevice binder_miscdev = {
.minor = MISC_DYNAMIC_MINOR,
.name = "binder",
.fops = &binder_fops
};
這裡指定了Binder設備的名稱是“binder”。這樣,在用戶空間便可以通過對/dev/binder文件進行操作來使用Binder。
binder_miscdev同時也指定了該設備的fops。fops是另外一個結構體,這個結構中包含了一系列的函數指針,其定義如下:
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
這裡除了owner之外,每一個字段都是一個函數指針,這些函數指針對應了用戶空間在使用Binder設備時的操作。例如:binder_poll對應了poll系統調用的處理,binder_mmap對應了mmap系統調用的處理,其他類同。
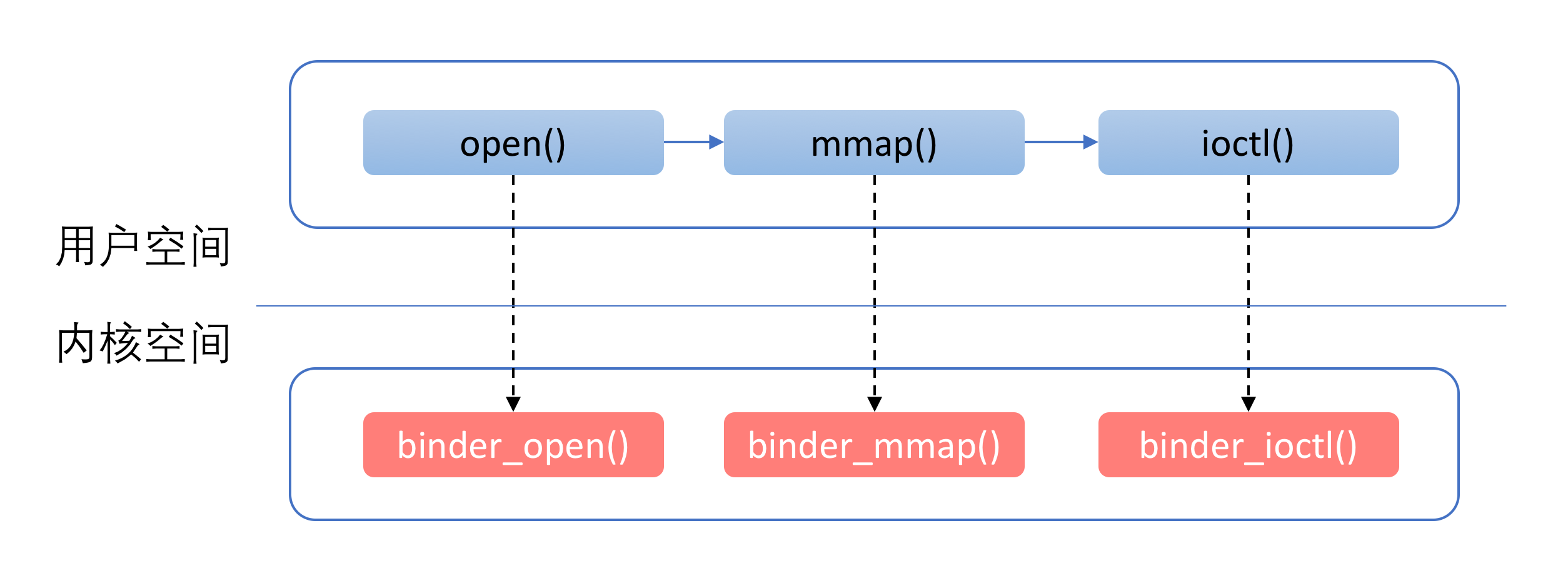
這其中,有三個函數尤為重要,它們是:binder_open,binder_mmap和binder_ioctl。 這是因為,需要使用Binder的進程,幾乎總是先通過binder_open打開Binder設備,然後通過binder_mmap進行內存映射。
在這之後,通過binder_ioctl來進行實際的操作。Client對於Server端的請求,以及Server對於Client請求結果的返回,都是通過ioctl完成的。
這裡提到的流程如下圖所示:
Binder驅動中包含了很多的結構體。為了便於下文講解,這裡我們先對這些結構體做一些介紹。
驅動中的結構體可以分為兩類:
一類是與用戶空間共用的,這些結構體在Binder通信協議過程中會用到。因此,這些結構體定義在binder.h中,包括:
這其中,binder_write_read和binder_transaction_data這兩個結構體最為重要,它們存儲了IPC調用過程中的數據。關於這一點,我們在下文中會講解。
Binder驅動中,還有一類結構體是僅僅Binder驅動內部實現過程中需要的,它們定義在binder.c中,包括:
這裡需要讀者關注的結構體已經用加粗做了標注。
Binder協議可以分為控制協議和驅動協議兩類。
控制協議是進程通過ioctl(“/dev/binder”) 與Binder設備進行通訊的協議,該協議包含以下幾種命令:
Binder的驅動協議描述了對於Binder驅動的具體使用過程。驅動協議又可以分為兩類:
binder_driver_command_protocol,描述了進程發送給Binder驅動的命令binder_driver_return_protocol,描述了Binder驅動發送給進程的命令binder_driver_command_protocol共包含17個命令,分別是:
binder_driver_return_protocol共包含18個命令,分別是:
單獨看上面的協議可能很難理解,這裡我們以一次Binder請求過程來詳細看一下Binder協議是如何通信的,就比較好理解了。
這幅圖的說明如下:
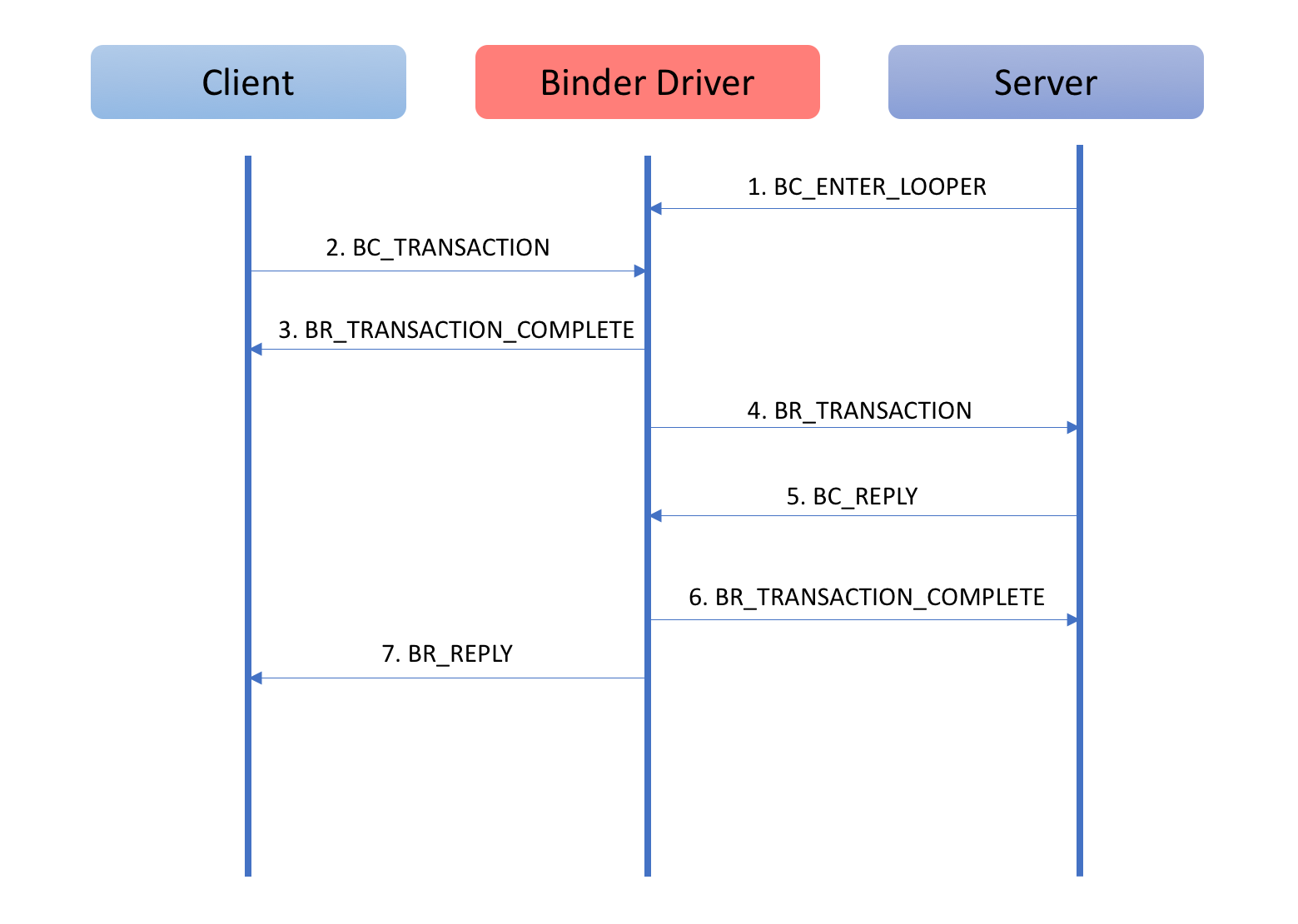
這裡再補充說明一下,通過上面的Binder協議的說明中我們看到,Binder協議的通信過程中,不僅僅是發送請求和接受數據這些命令。同時包括了對於引用計數的管理和對於死亡通知的管理(告知一方,通訊的另外一方已經死亡)等功能。
這些功能的通信過程和上面這幅圖是類似的:一方發送BC_XXX,然後由驅動控制通信過程,接著發送對應的BR_XXX命令給通信的另外一方。因為這種相似性,對於這些內容就不再贅述了。
在有了上面這些背景知識介紹之後,我們就可以進入到Binder驅動的內部實現中來一探究竟了。
PS:上面介紹的這些結構體和協議,因為內容較多,初次看完記不住是很正常的,在下文詳細講解的時候,回過頭來對照這些表格來理解是比較有幫助的。
任何進程在使用Binder之前,都需要先通過open("/dev/binder")打開Binder設備。上文已經提到,用戶空間的open系統調用對應了驅動中的binder_open函數。在這個函數,Binder驅動會為調用的進程做一些初始化工作。binder_open函數代碼如下所示:
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
// 創建進程對應的binder_proc對象
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
// 初始化binder_proc
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
proc->default_priority = task_nice(current);
// 鎖保護
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);
// 添加到全局列表binder_procs中
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
filp->private_data = proc;
binder_unlock(__func__);
return 0;
}
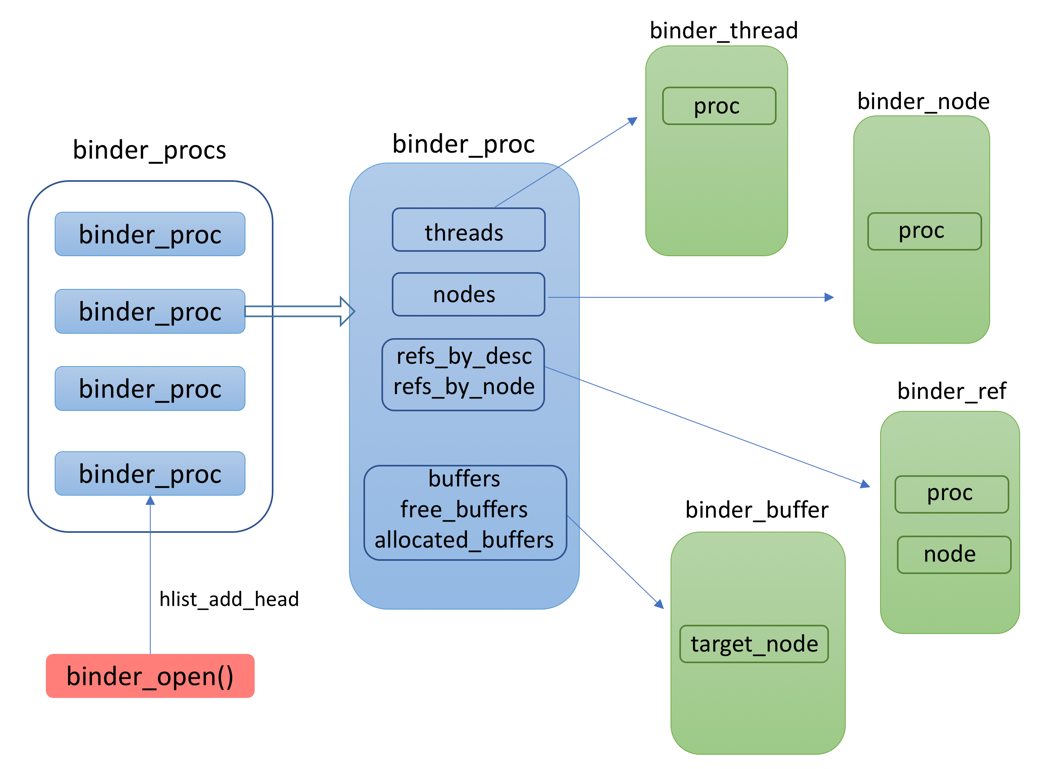
在Binder驅動中,通過binder_procs記錄了所有使用Binder的進程。每個初次打開Binder設備的進程都會被添加到這個列表中的。
另外,請讀者回顧一下上文介紹的Binder驅動中的幾個關鍵結構體:
在實現過程中,為了便於查找,這些結構體互相之間都留有字段存儲關聯的結構。
下面這幅圖描述了這裡說到的這些內容:
在打開Binder設備之後,進程還會通過mmap進行內存映射。mmap的作用有如下兩個:
binder_mmap函數對應了mmap系統調用的處理,這個函數也是Binder驅動的精華所在(這裡說的binder_mmap函數也包括其內部調用的binder_update_page_range函數,見下文)。
前文我們說到,使用Binder機制,數據只需要經歷一次拷貝就可以了,其原理就在這個函數中。
binder_mmap這個函數中,會申請一塊物理內存,然後在用戶空間和內核空間同時對應到這塊內存上。在這之後,當有Client要發送數據給Server的時候,只需一次,將Client發送過來的數據拷貝到Server端的內核空間指定的內存地址即可,由於這個內存地址在服務端已經同時映射到用戶空間,因此無需再做一次復制,Server即可直接訪問,整個過程如下圖所示:
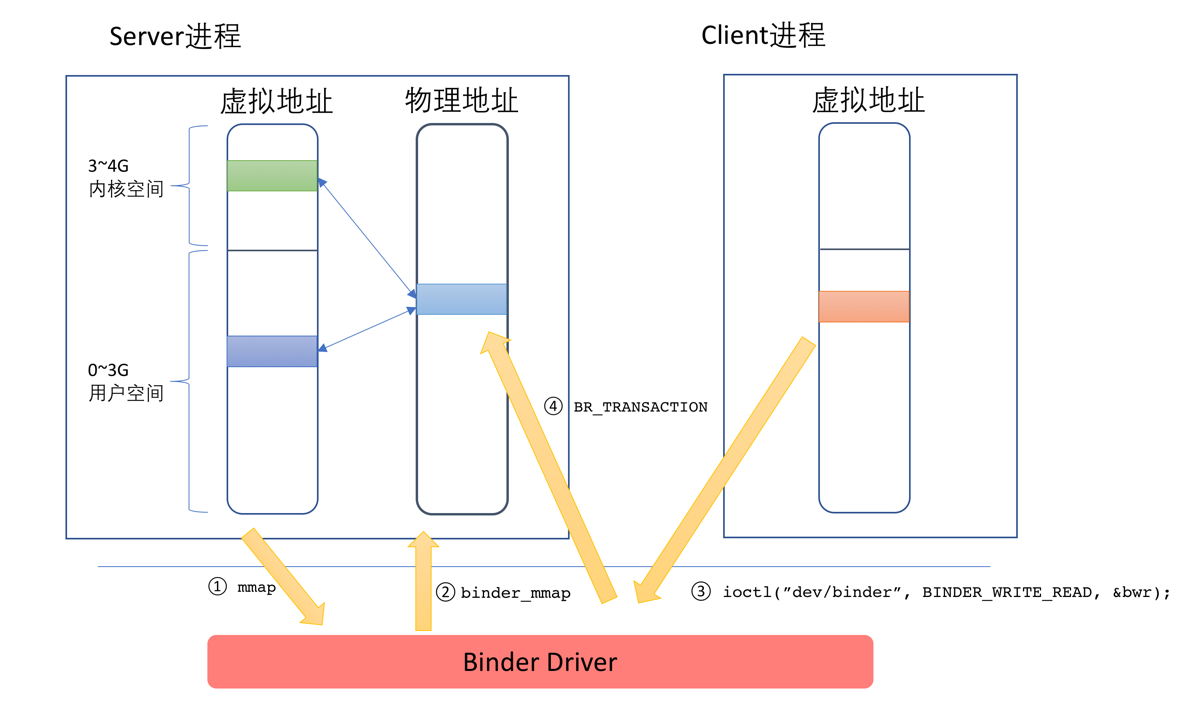
這幅圖的說明如下:
了解原理之後,我們再來看一下Binder驅動的相關源碼。這段代碼有兩個函數:
binder_mmap函數對應了mmap的系統調用的處理binder_update_page_range函數真正實現了內存分配和地址映射static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
...
// 在內核空間獲取一塊地址范圍
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
proc->buffer = area->addr;
// 記錄內核空間與用戶空間的地址偏移
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
...
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
/* binder_update_page_range assumes preemption is disabled */
preempt_disable();
// 通過下面這個函數真正完成內存的申請和地址的映射
// 初次使用,先申請一個PAGE_SIZE大小的內存
ret = binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma);
...
}
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct vm_struct tmp_area;
struct page **page;
struct mm_struct *mm;
...
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
struct page **page_array_ptr;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
// 真正進行內存的分配
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
if (*page == NULL) {
pr_err("%d: binder_alloc_buf failed for page at %p\n",
proc->pid, page_addr);
goto err_alloc_page_failed;
}
tmp_area.addr = page_addr;
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */;
page_array_ptr = page;
// 在內核空間進行內存映射
ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr);
if (ret) {
pr_err("%d: binder_alloc_buf failed to map page at %p in kernel\n",
proc->pid, page_addr);
goto err_map_kernel_failed;
}
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
// 在用戶空間進行內存映射
ret = vm_insert_page(vma, user_page_addr, page[0]);
if (ret) {
pr_err("%d: binder_alloc_buf failed to map page at %lx in userspace\n",
proc->pid, user_page_addr);
goto err_vm_insert_page_failed;
}
/* vm_insert_page does not seem to increment the refcount */
}
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
preempt_disable();
return 0;
...
在開發過程中,我們可以通過procfs看到進程映射的這塊內存空間:
adb shell進入到終端ps | grep system_server來確定進程號,例如是1889 cat /proc/[pid]/maps | grep "/dev/binder" 過濾出這塊內存的地址在我的Nexus 6P上,控制台輸出如下:
angler:/ # ps | grep system_server system 1889 526 2353404 140016 SyS_epoll_ 72972eeaf4 S system_server angler:/ # cat /proc/1889/maps | grep "/dev/binder" 7294761000-729485f000 r--p 00000000 00:0c 12593 /dev/binder
PS:grep是通過通配符進行匹配過濾的命令,“|”是Unix上的管道命令。即將前一個命令的輸出給下一個命令作為輸入。如果這裡我們不加“ | grep xxx”,那麼將看到前一個命令的完整輸出。
上文中,我們看到binder_mmap的時候,會申請一個PAGE_SIZE(通常是4K)的內存。而實際使用過程中,一個PAGE_SIZE的大小通常是不夠的。
在驅動中,會根據實際的使用情況進行內存的分配。有內存的分配,當然也需要內存的釋放。這裡我們就來看看Binder驅動中是如何進行內存的管理的。
首先,我們還是從一次IPC請求說起。
當一個Client想要對Server發出請求時,它首先將請求發送到Binder設備上,由Binder驅動根據請求的信息找到對應的目標節點,然後將請求數據傳遞過去。
進程通過ioctl系統調用來發出請求:ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr)
PS:這行代碼來自於Framework層的IPCThreadState類。在後文中,我們將看到,IPCThreadState類專門負責與驅動進行通信。
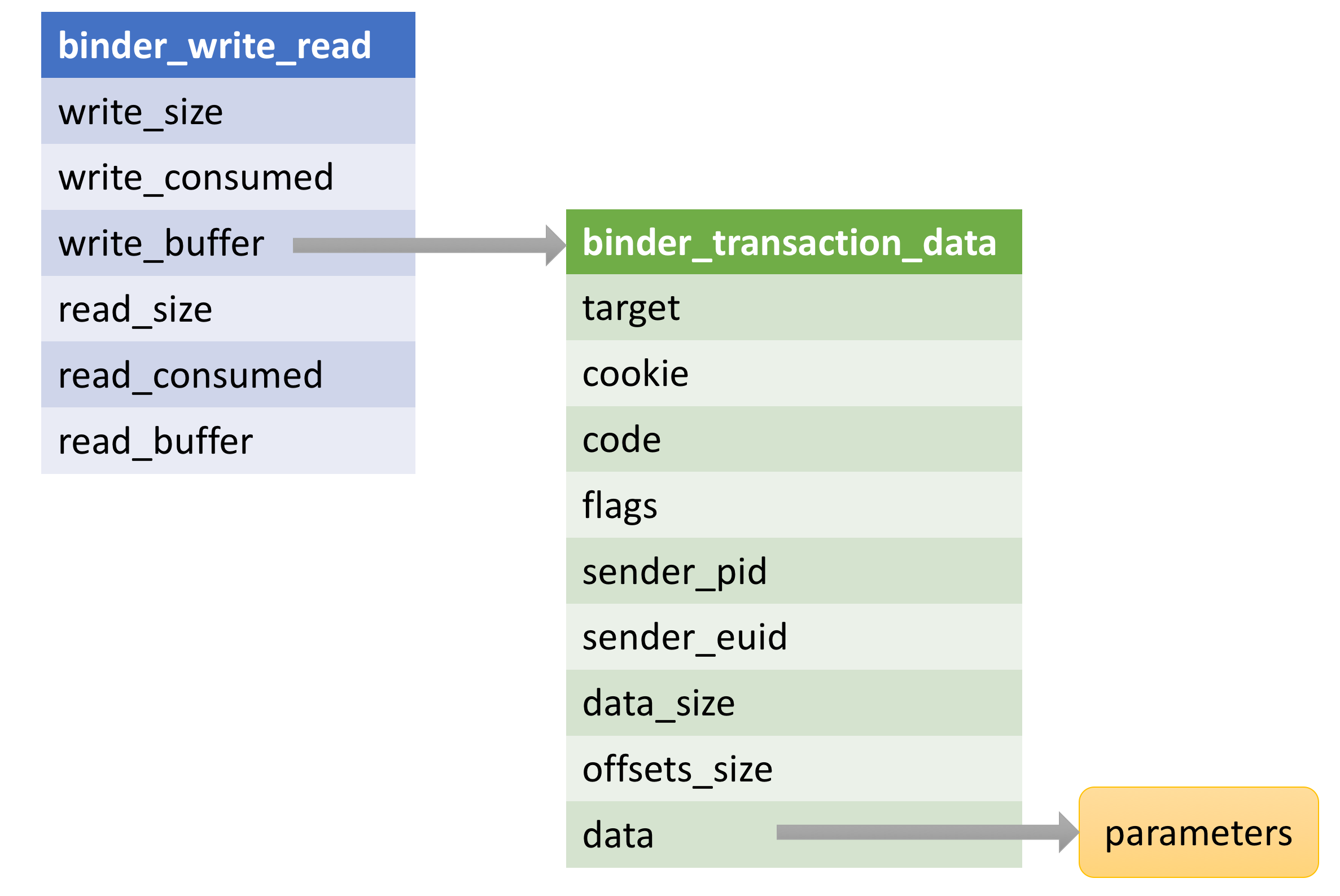
這裡的mProcess->mDriverFD對應了打開Binder設備時的fd。BINDER_WRITE_READ對應了具體要做的操作碼,這個操作碼將由Binder驅動解析。bwr存儲了請求數據,其類型是binder_write_read。
binder_write_read其實是一個相對外層的數據結構,其內部會包含一個binder_transaction_data結構的數據。binder_transaction_data包含了發出請求者的標識,請求的目標對象以及請求所需要的參數。它們的關系如下圖所示:
binder_ioctl函數對應了ioctl系統調用的處理。這個函數的邏輯比較簡單,就是根據ioctl的命令來確定進一步處理的邏輯,具體如下:
這其中,最關鍵的就是binder_thread_write方法。當Client請求Server的時候,便會發送一個BINDER_WRITE_READ命令,同時框架會將將實際的數據包裝好。此時,binder_transaction_data中的code將是BC_TRANSACTION,由此便會調用到binder_transaction方法,這個方法是對一次Binder事務的處理,這其中會調用binder_alloc_buf函數為此次事務申請一個緩存。這裡提到到調用關系如下:
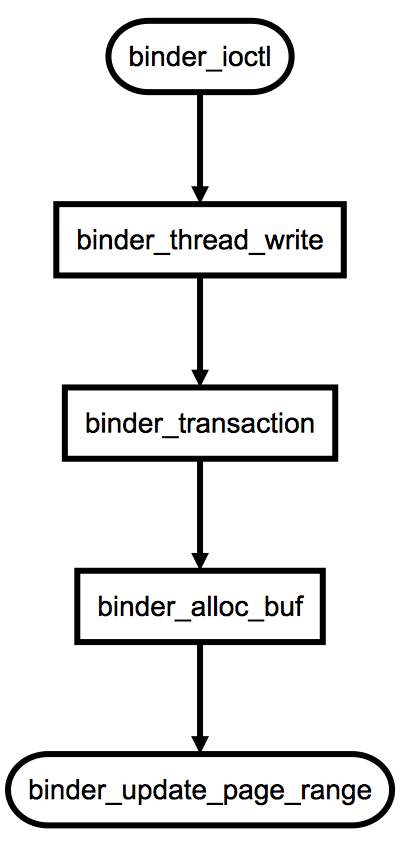
binder_update_page_range這個函數在上文中,我們已經看到過了。其作用就是:進行內存分配並且完成內存的映射。而binder_alloc_buf函數,正如其名稱那樣的:完成緩存的分配。
在驅動中,通過binder_buffer結構體描述緩存。一次Binder事務就會對應一個binder_buffer,其結構如下所示:
struct binder_buffer {
struct list_head entry;
struct rb_node rb_node;
unsigned free:1;
unsigned allow_user_free:1;
unsigned async_transaction:1;
unsigned debug_id:29;
struct binder_transaction *transaction;
struct binder_node *target_node;
size_t data_size;
size_t offsets_size;
uint8_t data[0];
};
而在binder_proc(描述了使用Binder的進程)中,包含了幾個字段用來管理進程在Binder IPC過程中緩存,如下:
struct binder_proc {
...
struct list_head buffers; // 進程擁有的buffer列表
struct rb_root free_buffers; // 空閒buffer列表
struct rb_root allocated_buffers; // 已使用的buffer列表
size_t free_async_space; // 剩余的異步調用的空間
size_t buffer_size; // 緩存的上限
...
};
進程在mmap時,會設定支持的總緩存大小的上限(下文會講到)。而進程每當收到BC_TRANSACTION,就會判斷已使用緩存加本次申請的和有沒有超過上限。如果沒有,就考慮進行內存的分配。
進程的空閒緩存記錄在binder_proc的free_buffers中,這是一個以紅黑樹形式存儲的結構。每次嘗試分配緩存的時候,會從這裡面按大小順序進行查找,找到最接近需要的一塊緩存。查找的邏輯如下:
while (n) {
buffer = rb_entry(n, struct binder_buffer, rb_node);
BUG_ON(!buffer->free);
buffer_size = binder_buffer_size(proc, buffer);
if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right;
else {
best_fit = n;
break;
}
}
找到之後,還需要對binder_proc中的字段進行相應的更新:
rb_erase(best_fit, &proc->free_buffers);
buffer->free = 0;
binder_insert_allocated_buffer(proc, buffer);
if (buffer_size != size) {
struct binder_buffer *new_buffer = (void *)buffer->data + size;
list_add(&new_buffer->entry, &buffer->entry);
new_buffer->free = 1;
binder_insert_free_buffer(proc, new_buffer);
}
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: binder_alloc_buf size %zd got %p\n",
proc->pid, size, buffer);
buffer->data_size = data_size;
buffer->offsets_size = offsets_size;
buffer->async_transaction = is_async;
if (is_async) {
proc->free_async_space -= size + sizeof(struct binder_buffer);
binder_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC,
"%d: binder_alloc_buf size %zd async free %zd\n",
proc->pid, size, proc->free_async_space);
}
下面我們再來看看內存的釋放。
BC_FREE_BUFFER命令是通知驅動進行內存的釋放,binder_free_buf函數是真正實現的邏輯,這個函數與binder_alloc_buf是剛好對應的。在這個函數中,所做的事情包括:
Binder機制淡化了進程的邊界,使得跨越進程也能夠調用到指定服務的方法,其原因是因為Binder機制在底層處理了在進程間的“對象”傳遞。
在Binder驅動中,並不是真的將對象在進程間來回序列化,而是通過特定的標識來進行對象的傳遞。Binder驅動中,通過flat_binder_object來描述需要跨越進程傳遞的對象。其定義如下:
struct flat_binder_object {
__u32 type;
__u32 flags;
union {
binder_uintptr_t binder; /* local object */
__u32 handle; /* remote object */
};
binder_uintptr_t cookie;
};
這其中,type有如下5種類型。
enum {
BINDER_TYPE_BINDER = B_PACK_CHARS('s', 'b', '*', B_TYPE_LARGE),
BINDER_TYPE_WEAK_BINDER = B_PACK_CHARS('w', 'b', '*', B_TYPE_LARGE),
BINDER_TYPE_HANDLE = B_PACK_CHARS('s', 'h', '*', B_TYPE_LARGE),
BINDER_TYPE_WEAK_HANDLE = B_PACK_CHARS('w', 'h', '*', B_TYPE_LARGE),
BINDER_TYPE_FD = B_PACK_CHARS('f', 'd', '*', B_TYPE_LARGE),
};
當對象傳遞到Binder驅動中的時候,由驅動來進行翻譯和解釋,然後傳遞到接收的進程。
例如當Server把Binder實體傳遞給Client時,在發送數據流中,flat_binder_object中的type是BINDER_TYPE_BINDER,同時binder字段指向Server進程用戶空間地址。但這個地址對於Client進程是沒有意義的(Linux中,每個進程的地址空間是互相隔離的),驅動必須對數據流中的flat_binder_object做相應的翻譯:將type該成BINDER_TYPE_HANDLE;為這個Binder在接收進程中創建位於內核中的引用並將引用號填入handle中。對於發生數據流中引用類型的Binder也要做同樣轉換。經過處理後接收進程從數據流中取得的Binder引用才是有效的,才可以將其填入數據包binder_transaction_data的target.handle域,向Binder實體發送請求。
由於每個請求和請求的返回都會經歷內核的翻譯,因此這個過程從進程的角度來看是完全透明的。進程完全不用感知這個過程,就好像對象真的在進程間來回傳遞一樣。
上文多次提到,Binder本身是C/S架構。由Server提供服務,被Client使用。既然是C/S架構,就可能存在多個Client會同時訪問Server的情況。 在這種情況下,如果Server只有一個線程處理響應,就會導致客戶端的請求可能需要排隊而導致響應過慢的現象發生。解決這個問題的方法就是引入多線程。
Binder機制的設計從最底層–驅動層,就考慮到了對於多線程的支持。具體內容如下:
上文已經說過,每一個Binder Server在驅動中會有一個binder_node進行對應。同時,Binder驅動會負責在進程間傳遞服務對象,並負責底層的轉換。另外,我們也提到,每一個Binder服務都需要有一個唯一的名稱。由ServiceManager來管理這些服務的注冊和查找。
而實際上,為了便於使用,ServiceManager本身也實現為一個Server對象。任何進程在使用ServiceManager的時候,都需要先拿到指向它的標識。然後通過這個標識來使用ServiceManager。
這似乎形成了一個互相矛盾的現象:
解決這個矛盾的辦法其實也很簡單:Binder機制為ServiceManager預留了一個特殊的位置。這個位置是預先定好的,任何想要使用ServiceManager的進程只要通過這個特定的位置就可以訪問到ServiceManager了(而不用再通過ServiceManager的接口)。
在Binder驅動中,有一個全局的變量:
static struct binder_node *binder_context_mgr_node;
這個變量指向的就是ServiceManager。
當有進程通過ioctl並指定命令為BINDER_SET_CONTEXT_MGR的時候,驅動被認定這個進程是ServiceManager,binder_ioctl函數中對應的處理如下:
case BINDER_SET_CONTEXT_MGR:
if (binder_context_mgr_node != NULL) {
pr_err("BINDER_SET_CONTEXT_MGR already set\n");
ret = -EBUSY;
goto err;
}
ret = security_binder_set_context_mgr(proc->tsk);
if (ret < 0)
goto err;
if (uid_valid(binder_context_mgr_uid)) {
if (!uid_eq(binder_context_mgr_uid, current->cred->euid)) {
pr_err("BINDER_SET_CONTEXT_MGR bad uid %d != %d\n",
from_kuid(&init_user_ns, current->cred->euid),
from_kuid(&init_user_ns, binder_context_mgr_uid));
ret = -EPERM;
goto err;
}
} else
binder_context_mgr_uid = current->cred->euid;
binder_context_mgr_node = binder_new_node(proc, 0, 0);
if (binder_context_mgr_node == NULL) {
ret = -ENOMEM;
goto err;
}
binder_context_mgr_node->local_weak_refs++;
binder_context_mgr_node->local_strong_refs++;
binder_context_mgr_node->has_strong_ref = 1;
binder_context_mgr_node->has_weak_ref = 1;
break;
ServiceManager應當要先於所有Binder Server之前啟動。在它啟動完成並告知Binder驅動之後,驅動便設定好了這個特定的節點。
在這之後,當有其他模塊想要使用ServerManager的時候,只要將請求指向ServiceManager所在的位置即可。
在Binder驅動中,通過handle = 0這個位置來訪問ServiceManager。例如,binder_transaction中,判斷如果target.handler為0,則認為這個請求是發送給ServiceManager的,相關代碼如下:
if (tr->target.handle) {
struct binder_ref *ref;
ref = binder_get_ref(proc, tr->target.handle, true);
if (ref == NULL) {
binder_user_error("%d:%d got transaction to invalid handle\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_invalid_target_handle;
}
target_node = ref->node;
} else {
target_node = binder_context_mgr_node;
if (target_node == NULL) {
return_error = BR_DEAD_REPLY;
goto err_no_context_mgr_node;
}
}
本篇文章中,我們對Binder機制做了整體架構和分層的介紹,也詳細講解了Binder機制中的驅動模塊。對於驅動之上的模塊,會在今後的文章中講解。
下一篇文章中,我們會詳細講解Android Binder機制的Framework層,敬請期待。
 Android引入即用的便捷開發框架WelikeAndroid
Android引入即用的便捷開發框架WelikeAndroid
WelikeAndroid 是什麼? WelikeAndroid 是一款引入即用的便捷開發框架,致力於為程序員打造最佳的編程體驗,使用WelikeAndroid,
 再次探究Android ListView緩存機制
再次探究Android ListView緩存機制
概述 雖然現在5.0後Google推出了RecycleView,但在5.0 Lollipop普及前Listview仍會被廣泛使用,所以打算再次探究一下Listvi
 Android的.so文件詳細解讀
Android的.so文件詳細解讀
早期的Android系統幾乎只支持ARMv5的CPU架構,你知道現在它支持多少種嗎?7種! Android系統目前支持以下七種不同的CPU架構:ARMv5,ARM
 Android UI 開發之實現底部切換標簽
Android UI 開發之實現底部切換標簽
前言 本篇博客要分享的一個UI效果——實現底部切換標簽,想必大家在一些應用上面遇到過這種效果了,最典型的就是微信了,可以左右滑動切換頁面,也可以點擊標簽頁滑動頁面




