編輯:關於Android編程
本篇文章包含以下內容:
XML數據的Dom解析
XML數據的Sax解析
XML數據的Pull解析
Activity中使用三種解析
Sax解析與Pull解析區別
三種解析方式的步驟:
1.在Assets文件夾中模擬創建XML數據
2.創建對應XML的Bean對象
3.開始解析
XML數據的Dom解析
DOM解析XML文件時,會將XML文件的所有內容讀取到內存中(內存的消耗比較大),然後允許您使用DOM API遍歷XML樹、檢索所需的數據
一、在Assets文件夾中模擬創建XML文件
<students> <student> <name sex="man">小明</name> <nickName>明明</nickName> </student> <student> <name sex="woman">小紅</name> <nickName>紅紅</nickName> </student> <student> <name sex="man">小亮</name> <nickName>亮亮</nickName> </student> </students>
二、創建對應XML的Bean對象
public class Student {
private String name;
private String sex;
private String nickName;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", nickName='" + nickName + '\'' +
'}';
}
}
三、Dom解析
public List<Student> dom2xml(InputStream is) throws Exception {
//一系列的初始化
List<Student> list = new ArrayList<>();
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
//獲得Document對象
Document document = builder.parse(is);
//獲得student的List
NodeList studentList = document.getElementsByTagName("student");
//遍歷student標簽
for (int i = 0; i < studentList.getLength(); i++) {
//獲得student標簽
Node node_student = studentList.item(i);
//獲得student標簽裡面的標簽
NodeList childNodes = node_student.getChildNodes();
//新建student對象
Student student = new Student();
//遍歷student標簽裡面的標簽
for (int j = 0; j < childNodes.getLength(); j++) {
//獲得name和nickName標簽
Node childNode = childNodes.item(j);
//判斷是name還是nickName
if ("name".equals(childNode.getNodeName())) {
String name = childNode.getTextContent();
student.setName(name);
//獲取name的屬性
NamedNodeMap nnm = childNode.getAttributes();
//獲取sex屬性,由於只有一個屬性,所以取0
Node n = nnm.item(0);
student.setSex(n.getTextContent());
} else if ("nickName".equals(childNode.getNodeName())) {
String nickName = childNode.getTextContent();
student.setNickName(nickName);
}
}
//加到List中
list.add(student);
}
return list;
}
XML數據的Sax解析
SAX是一個解析速度快並且占用內存少的xml解析器,SAX解析XML文件采用的是事件驅動,它並不需要解析完整個文檔,而是按內容順序解析文檔的過程
由於前面一和二的步驟是一樣的,這裡就省略了
三、Sax解析
public List<Student> sax2xml(InputStream is) throws Exception {
SAXParserFactory spf = SAXParserFactory.newInstance();
//初始化Sax解析器
SAXParser sp = spf.newSAXParser();
//新建解析處理器
MyHandler handler = new MyHandler();
//將解析交給處理器
sp.parse(is, handler);
//返回List
return handler.getList();
}
public class MyHandler extends DefaultHandler {
private List<Student> list;
private Student student;
//用於存儲讀取的臨時變量
private String tempString;
/**
* 解析到文檔開始調用,一般做初始化操作
*
* @throws SAXException
*/
@Override
public void startDocument() throws SAXException {
list = new ArrayList<>();
super.startDocument();
}
/**
* 解析到文檔末尾調用,一般做回收操作
*
* @throws SAXException
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
}
/**
* 每讀到一個元素就調用該方法
*
* @param uri
* @param localName
* @param qName
* @param attributes
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if ("student".equals(qName)) {
//讀到student標簽
student = new Student();
} else if ("name".equals(qName)) {
//獲取name裡面的屬性
String sex = attributes.getValue("sex");
student.setSex(sex);
}
super.startElement(uri, localName, qName, attributes);
}
/**
* 讀到元素的結尾調用
*
* @param uri
* @param localName
* @param qName
* @throws SAXException
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if ("student".equals(qName)) {
list.add(student);
}
if ("name".equals(qName)) {
student.setName(tempString);
} else if ("nickName".equals(qName)) {
student.setNickName(qName);
}
super.endElement(uri, localName, qName);
}
/**
* 讀到屬性內容調用
*
* @param ch
* @param start
* @param length
* @throws SAXException
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
tempString = new String(ch, start, length);
super.characters(ch, start, length);
}
/**
* 獲取該List
*
* @return
*/
public List<Student> getList() {
return list;
}
}
XML數據的Pull解析
Pull解析器的運行方式與 SAX 解析器相似。它提供了類似的事件,可以使用一個switch對感興趣的事件進行處理
三、Pull解析
public List<Student> pull2xml(InputStream is) throws Exception {
List<Student> list = null;
Student student = null;
//創建xmlPull解析器
XmlPullParser parser = Xml.newPullParser();
///初始化xmlPull解析器
parser.setInput(is, "utf-8");
//讀取文件的類型
int type = parser.getEventType();
//無限判斷文件類型進行讀取
while (type != XmlPullParser.END_DOCUMENT) {
switch (type) {
//開始標簽
case XmlPullParser.START_TAG:
if ("students".equals(parser.getName())) {
list = new ArrayList<>();
} else if ("student".equals(parser.getName())) {
student = new Student();
} else if ("name".equals(parser.getName())) {
//獲取sex屬性
String sex = parser.getAttributeValue(null,"sex");
student.setSex(sex);
//獲取name值
String name = parser.nextText();
student.setName(name);
} else if ("nickName".equals(parser.getName())) {
//獲取nickName值
String nickName = parser.nextText();
student.setNickName(nickName);
}
break;
//結束標簽
case XmlPullParser.END_TAG:
if ("student".equals(parser.getName())) {
list.add(student);
}
break;
}
//繼續往下讀取標簽類型
type = parser.next();
}
return list;
}
Activity中使用三種解析
public class XmlActivity extends AppCompatActivity implements View.OnClickListener {
private TextView tv;
private Button bt_dom, bt_sax, bt_pull;
private XmlUtils xmlUtils;
private List<Student> students;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_xml);
tv = (TextView) findViewById(R.id.tv);
bt_dom = (Button) findViewById(R.id.bt_dom);
bt_sax = (Button) findViewById(R.id.bt_sax);
bt_pull = (Button) findViewById(R.id.bt_pull);
bt_dom.setOnClickListener(this);
bt_sax.setOnClickListener(this);
bt_pull.setOnClickListener(this);
xmlUtils = new XmlUtils();
}
@Override
public void onClick(View v) {
switch (v.getId()) {
case R.id.bt_dom:
try {
students = xmlUtils.dom2xml(getResources().getAssets().open("student.xml"));
tv.setText(students.toString());
} catch (Exception e) {
e.printStackTrace();
}
break;
case R.id.bt_sax:
try {
students = xmlUtils.sax2xml(getResources().getAssets().open("student.xml"));
tv.setText(students.toString());
} catch (Exception e) {
e.printStackTrace();
}
break;
case R.id.bt_pull:
try {
students = xmlUtils.pull2xml(getResources().getAssets().open("student.xml"));
tv.setText(students.toString());
} catch (Exception e) {
e.printStackTrace();
}
break;
}
}
}
三種解析方式的效果圖是一樣的

Sax解析與Pull解析區別
SAX和Pull的區別:SAX解析器的工作方式是自動將事件推入事件處理器進行處理,因此你不能控制事件的處理主動結束;而Pull解析器的工作方式為允許你的應用程序代碼主動從解析器中獲取事件,正因為是主動獲取事件,因此可以在滿足了需要的條件後不再獲取事件,結束解析。
源碼:http://xiazai.jb51.net/201611/yuanma/AndroidXmljiexi(jb51.net).rar
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持本站。
 android launchmode 使用場景
android launchmode 使用場景
菜鳥起飛記android launchmode 使用場景Activity一共有以下四種launchMode:1.standard2.singleTop3.singleTa
 Android仿微信QQ設置圖形頭像裁剪功能
Android仿微信QQ設置圖形頭像裁剪功能
最近在做畢業設計,想有一個功能和QQ一樣可以裁剪頭像並設置圓形頭像,額,這是設計獅的一種潮流。而縱觀現在主流的APP,只要有用戶系統這個功能,這個需求一般都是在(bu)劫
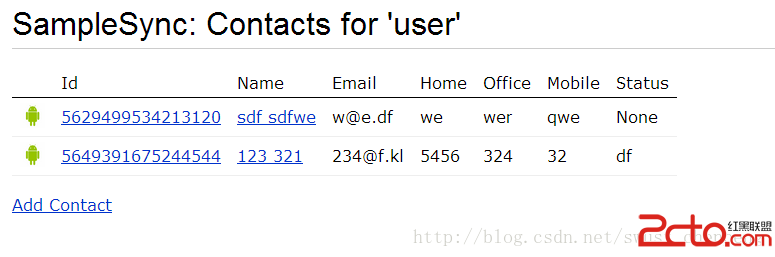 android 賬戶管理和同步機制
android 賬戶管理和同步機制
在用微信的時候,發現微信建立了自己的獨立賬戶管理,同時在聯系人中,可以直接點擊發送信息,查看朋友圈等功能,感覺挺方便了 然後就做了相關方面的調研,主要從兩個方面,進行了研
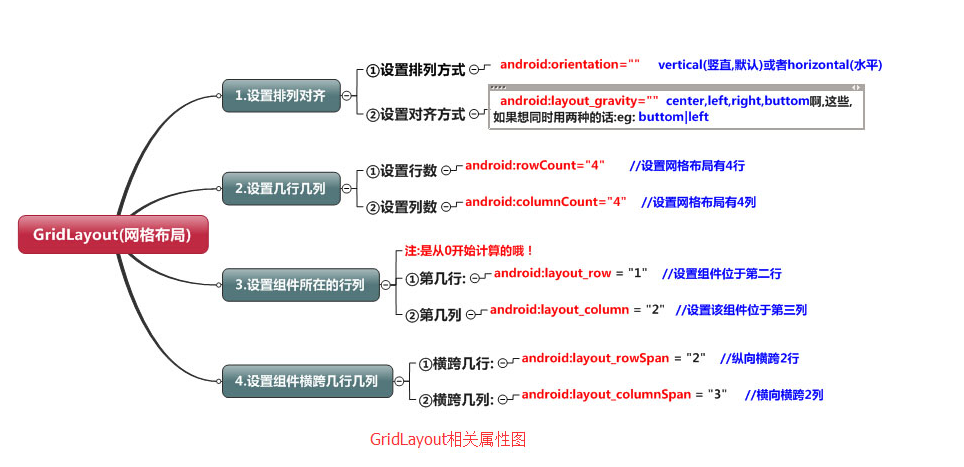 Android布局之GridLayout網格布局
Android布局之GridLayout網格布局
網格布局標簽是GridLayout。這個布局是android4.0新增的布局。這個布局只有4.0之後的版本才能使用。不過新增了一些東東①跟LinearLayout(線性布