編輯:關於Android編程
分析源碼之前先來介紹一下ArrayMap的存儲結構,ArrayMap數據的存儲不同於HashMap和SparseArray。
Java提供了HashMap,但是HashMap對於手機端而言,對空間的利用太大,所以Android提供了SparseArray和ArrayMap。二者都是基於二分查找,所以數據量大的時候,最壞效率會比HashMap慢很多。因此建議數量在千以內比較合適。
一、SparseArray
SparseArray對應的key只能是int類型,它不會對key進行裝箱操作。它使用了兩個數組,一個保存key,一個保存value。
SparseArray使用二分查找來找到key對應的插入位置。所以要保證mKeys數組有序。
remove的時候不會立刻重新清理刪除掉的數據,而是將對一個的數據標記為DELETE(一個Object對象)。在必要的環節調用gc清理標記為DELETE的空間。
二、ArrayMap
重點介紹一下ArrayMap。
首先從ArrayMap的四個數組說起。mHashes,用於保存key對應的hashCode;mArray,用於保存鍵值對(key,value),其結構為[key1,value1,key2,value2,key3,value3,......];mBaseCache,緩存,如果ArrayMap的數據量從4,增加到8,用該數組保存之前使用的mHashes和mArray,這樣如果數據量再變回4的時候,可以再次使用之前的數組,不需要再次申請空間,這樣節省了一定的時間;mTwiceBaseCache,與mBaseCache對應,不過觸發的條件是數據量從8增長到12。
上面提到的數據量有8增長到12,為什麼不是16?這也算是ArrayMap的一個優化的點,它不是每次增長1倍,而是使用了如下方法(mSize+(mSize>>1)),即每次增加1/2。
有了上面的說明,讀懂代碼就容易多了。
1、很多地方用到的indexOf
這裡使用了二分查找來查找對應的index
int indexOf(Object key, int hash) {
final int N = mSize;
// Important fast case: if nothing is in here, nothing to look for.
//數組為空,直接返回
if (N == 0) {
return ~0;
}
//二分查找,不細說了
int index = ContainerHelpers.binarySearch(mHashes, N, hash);
// If the hash code wasn't found, then we have no entry for this key.
//沒找到hashCode,返回index,一個負數
if (index < 0) {
return index;
}
// If the key at the returned index matches, that's what we want.
//對比key值,相同則返回index
if (key.equals(mArray[index<<1])) {
return index;
}
// Search for a matching key after the index.
//如果返回的index對應的key值,與傳入的key值不等,則可能對應的key在index後面
int end;
for (end = index + 1; end < N && mHashes[end] == hash; end++) {
if (key.equals(mArray[end << 1])) return end;
}
// Search for a matching key before the index.
//接上句,後面沒有,那一定在前面。
for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {
if (key.equals(mArray[i << 1])) return i;
}
// Key not found -- return negative value indicating where a
// new entry for this key should go. We use the end of the
// hash chain to reduce the number of array entries that will
// need to be copied when inserting.
//毛都沒找到,那肯定是沒有了,返回個負數
return ~end;
}
2、看一下put方法
public V put(K key, V value) {
final int hash;
int index;
//key是空,則通過indexOfNull查找對應的index;如果不為空,通過indexOf查找對應的index
if (key == null) {
hash = 0;
index = indexOfNull();
} else {
hash = key.hashCode();
index = indexOf(key, hash);
}
//index大於或等於0,一定是之前put過相同的key,直接替換對應的value。因為mArray中不只保存了value,還保存了key。
//其結構為[key1,value1,key2,value2,key3,value3,......]
//所以,需要將index乘2對應key,index乘2再加1對應value
if (index >= 0) {
index = (index<<1) + 1;
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
//取正數
index = ~index;
//mSize的大小,即已經保存的數據量與mHashes的長度相同了,需要擴容啦
if (mSize >= mHashes.length) {
//擴容後的大小,有以下幾個檔位,BASE_SIZE(4),BASE_SIZE的2倍(8),mSize+(mSize>>1)(比之前的數據量擴容1/2)
final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1))
: (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
//擴容方法的實現
allocArrays(n);
//擴容後,需要把原來的數據拷貝到新數組中
if (mHashes.length > 0) {
if (DEBUG) Log.d(TAG, "put: copy 0-" + mSize + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
//看看被廢棄的數組是否還有利用價值
//如果被廢棄的數組的數據量為4或8,說明可能利用價值,以後用到的時候可以直接用。
//如果被廢棄的數據量太大,扔了算了,要不太占內存。如果浪費內存了,還費這麼大勁,加了類干啥。
freeArrays(ohashes, oarray, mSize);
}
//這次put的key對應的hashcode排序沒有排在最後(index沒有指示到數組結尾),因此需要移動index後面的數據
if (index < mSize) {
if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (mSize-index)
+ " to " + (index+1));
System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
//把數據保存到數組中。看到了吧,key和value都在mArray中;hashCode放到mHashes
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
3、remove方法
remove方法在某種條件下,會重新分配內存,保證分配給ArrayMap的內存在合理區間,減少對內存的占用。但是從這裡也可以看出,Android使用的是用時間換空間的方式。無論從任何角度,頻繁的分配回收內存一定會耗費時間的。
remove最終使用的是removeAt方法,此處只說明removeAt
/**
* Remove the key/value mapping at the given index.
* @param index The desired index, must be between 0 and {@link #size()}-1.
* @return Returns the value that was stored at this index.
*/
public V removeAt(int index) {
final Object old = mArray[(index << 1) + 1];
//如果數據量小於等於1,說明刪除該元素後,沒有數組為空,清空兩個數組。
if (mSize <= 1) {
// Now empty.
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to 0");
//put中已有說明
freeArrays(mHashes, mArray, mSize);
mHashes = EmptyArray.INT;
mArray = EmptyArray.OBJECT;
mSize = 0;
} else {
//如果當初申請的數組最大容納數據個數大於BASE_SIZE的2倍(8),並且現在存儲的數據量只用了申請數量的1/3,
//則需要重新分配空間,已減少對內存的占用
if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {
// Shrunk enough to reduce size of arrays. We don't allow it to
// shrink smaller than (BASE_SIZE*2) to avoid flapping between
// that and BASE_SIZE.
//新數組的大小
final int n = mSize > (BASE_SIZE*2) ? (mSize + (mSize>>1)) : (BASE_SIZE*2);
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);
mSize--;
//index之前的數據拷貝到新數組中
if (index > 0) {
if (DEBUG) Log.d(TAG, "remove: copy from 0-" + index + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, index);
System.arraycopy(oarray, 0, mArray, 0, index << 1);
}
//將index之後的數據拷貝到新數組中,和(index>0)的分支結合,就將index位置的數據刪除了
if (index < mSize) {
if (DEBUG) Log.d(TAG, "remove: copy from " + (index+1) + "-" + mSize
+ " to " + index);
System.arraycopy(ohashes, index + 1, mHashes, index, mSize - index);
System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,
(mSize - index) << 1);
}
} else {
mSize--;
//將index後的數據向前移位
if (index < mSize) {
if (DEBUG) Log.d(TAG, "remove: move " + (index+1) + "-" + mSize
+ " to " + index);
System.arraycopy(mHashes, index + 1, mHashes, index, mSize - index);
System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,
(mSize - index) << 1);
}
//移位後最後一個數據清空
mArray[mSize << 1] = null;
mArray[(mSize << 1) + 1] = null;
}
}
return (V)old;
}
4、freeArrays
put中有說明,這裡就不進行概述了,直接上代碼,印證上面的說法。
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {
//已經廢棄的數組個數為BASE_SIZE的2倍(8),則用mTwiceBaseCache保存廢棄的數組;
//如果個數為BASE_SIZE(4),則用mBaseCache保存廢棄的數組
if (hashes.length == (BASE_SIZE*2)) {
synchronized (ArrayMap.class) {
if (mTwiceBaseCacheSize < CACHE_SIZE) {
//array為剛剛廢棄的數組,mTwiceBaseCache如果有內容,則放入array[0]位置,
//在allocArrays中會從array[0]取出,放回mTwiceBaseCache
array[0] = mTwiceBaseCache;
//array[1]存放hash數組。因為array中每個元素都是Object對象,所以每個元素都可以存放數組
array[1] = hashes;
//清除index為2和之後的數據
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
mTwiceBaseCache = array;
mTwiceBaseCacheSize++;
if (DEBUG) Log.d(TAG, "Storing 2x cache " + array
+ " now have " + mTwiceBaseCacheSize + " entries");
}
}
} else if (hashes.length == BASE_SIZE) {
synchronized (ArrayMap.class) {
if (mBaseCacheSize < CACHE_SIZE) {
//代碼的注釋可以參考上面,不重復說明了
array[0] = mBaseCache;
array[1] = hashes;
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
mBaseCache = array;
mBaseCacheSize++;
if (DEBUG) Log.d(TAG, "Storing 1x cache " + array
+ " now have " + mBaseCacheSize + " entries");
}
}
}
}
5、allocArrays
算了,感覺沒啥好說的,看懂了freeArrays,allocArrays自然就理解了。
總體來說,通過新數組的個數產生3個分支,個數為BASE_SIZE(4),從mBaseCache取之前廢棄的數組;BASE_SIZE的2倍(8),從mTwiceBaseCache取之前廢棄的數組;其他,之前廢棄的數組沒有存儲,因為太耗費內存,這種情況下,重新分配內存。
6、clear和erase
clear清空數組,如果再向數組中添加元素,需要重新申請空間;erase清除數組中的數組,空間還在。
7、get
主要的邏輯都在indexOf中了,剩下的代碼不需要分析了,看了的都說懂(竊笑)。
感謝閱讀,希望能幫助到大家,謝謝大家對本站的支持!
 Android 懸浮窗各機型各系統適配大全
Android 懸浮窗各機型各系統適配大全
這篇博客主要介紹的是 Android 主流各種機型和各種版本的懸浮窗權限適配,但是由於碎片化的問題,所以在適配方面也無法做到完全的主流機型適配懸浮窗適配懸浮窗適配有兩種方
 Android漫游記(6)---APP啟動之旅(I)
Android漫游記(6)---APP啟動之旅(I)
Android基於Linux2.6+內核,我們看一張圖,以對Android系統的架構有個感性的認識。 我們從Kernel層簡單說明: 1、
 安卓模擬器genymotion的安裝與使用圖文教程
安卓模擬器genymotion的安裝與使用圖文教程
一、簡介相信大家用eclipse上的模擬器會覺得很慢很卡,這裡給大家介紹個好東西安卓模擬器genymotion。了解更多,可到此網站https://www.genymot
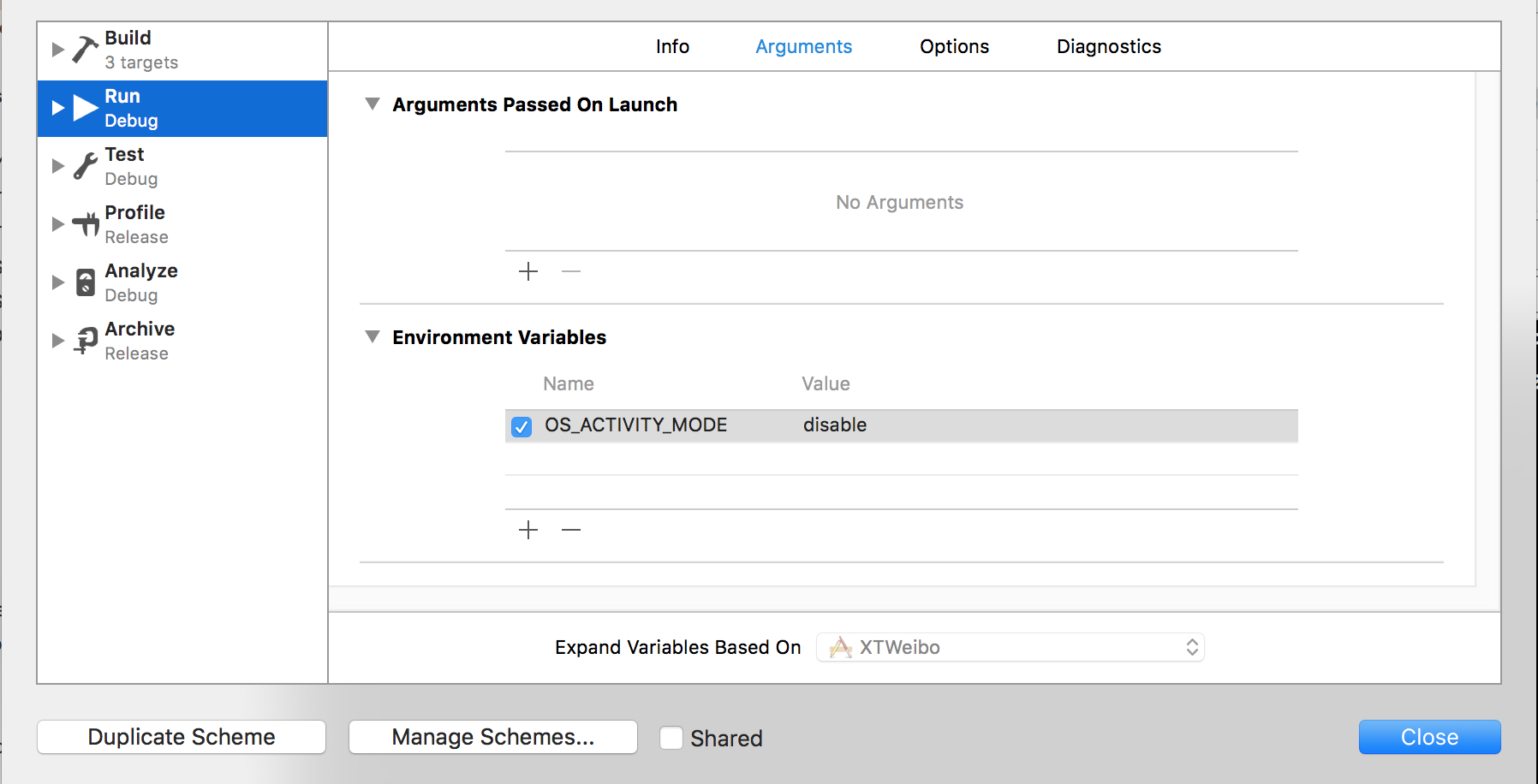 Xcode8 解決控制台輸出
Xcode8 解決控制台輸出
做一個記錄~