編輯:關於Android編程
一、網絡爬蟲的基本知識
網絡爬蟲通過遍歷互聯網絡,把網絡中的相關網頁全部抓取過來,這體現了爬的概念。爬蟲如何遍歷網絡呢,互聯網可以看做是一張大圖,每個頁面看做其中的一個節點,頁面的連接看做是有向邊。圖的遍歷方式分為寬度遍歷和深度遍歷,但是深度遍歷可能會在深度上過深的遍歷或者陷入黑洞。所以,大多數爬蟲不采用這種形式。另一方面,爬蟲在按照寬度優先遍歷的方式時候,會給待遍歷的網頁賦予一定優先級,這種叫做帶偏好的遍歷。
實際的爬蟲是從一系列的種子鏈接開始。種子鏈接是起始節點,種子頁面的超鏈接指向的頁面是子節點(中間節點),對於非html文檔,如excel等,不能從中提取超鏈接,看做圖的終端節點。整個遍歷過程中維護一張visited表,記錄哪些節點(鏈接)已經處理過了,跳過不作處理。
二、Android網絡爬蟲demo的簡單實現
看一下效果

抓的是這個網頁 然後寫了一個APP
是這樣的

把listview做成卡片式的了 然後配色弄的也很有紙質感啊啊啊
反正自己還挺喜歡的
然後就看看是怎麼弄的
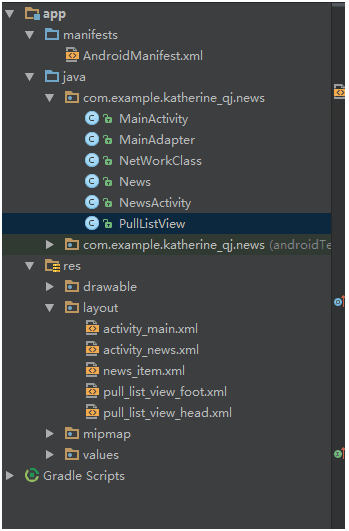
看一下每個類都是干啥的 :
MainActivity:主界面的Activity
MainAdapter:listview的適配器
NetWorkClass:鏈接網絡 使用HttpClient發送請求、接收響應得到content 大概就是拿到了這個網頁的什麼鬼東西
還有好多就是一個html的代碼 要解析這個
News:這個類裡有兩個屬性 一個標題 一個是這個標題新聞點進去那個url;
NewsActivity:詳細新聞界面
PullListView:重寫了listview 具有下拉刷新和上拉加載功能
然後從oncreat()開始看:
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
InitView();
MainThread mt = new MainThread(newsUrl);
final Thread t = new Thread(mt, "MainThread");
t.start();
pullListView.setOnRefreshListener(new PullListView.OnRefreshListener() {
@Override
public void onRefresh() {
isGetMore = false;
MainThread mt = new MainThread(newsUrl);
Thread t = new Thread(mt, "MainThread");
t.start();
}
});
pullListView.setOnGetMoreListener(new PullListView.OnGetMoreListener() {
@Override
public void onGetMore() {
isGetMore = true;
if (num > 1) {
MainThread mt = new MainThread(nextPage);
Thread t = new Thread(mt, "MainThread");
t.start();
}
}
});
pullListView.setOnItemClickListener(new AdapterView.OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
Intent intent = new Intent(MainActivity.this,NewsActivity.class);
intent.putExtra("url",list.get(position-1).getUrl());
startActivity(intent);
}
});
}
這個裡面主要就是先初始化了數據
然後new了一個線程 因為涉及到了網絡請求 所以我們要開線程去執行 然後有一些listview的下拉上拉點擊的綁定
所以主要內容是在線程裡面
再看線程之前 先看一下networkClass
package com.example.katherine_qj.news;
import android.net.http.HttpResponseCache;
import android.util.Log;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
/**
* Created by Katherine-qj on 2016/7/24.
*/
public class NetWorkClass {
public String getDataByGet(String url){
Log.e("qwe","content");
String content ="";
HttpClient httpClient = new DefaultHttpClient();
Log.e("qwe","content1");
/*使用HttpClient發送請求、接收響應很簡單,一般需要如下幾步即可。
1. 創建HttpClient對象。
2. 創建請求方法的實例,並指定請求URL。如果需要發送GET請求,創建HttpGet對象;如果需要發送POST請求,創建HttpPost對象。
3. 如果需要發送請求參數,可調用HttpGet、HttpPost共同的setParams(HetpParams params)方法來添加請求參數;對於HttpPost對象而言,也可調用setEntity(HttpEntity entity)方法來設置請求參數。
4. 調用HttpClient對象的execute(HttpUriRequest request)發送請求,該方法返回一個HttpResponse。
5. 調用HttpResponse的getAllHeaders()、getHeaders(String name)等方法可獲取服務器的響應頭;調用HttpResponse的getEntity()方法可獲取HttpEntity對象,該對象包裝了服務器的響應內容。程序可通過該對象獲取服務器的響應內容。
6. 釋放連接。無論執行方法是否成功,都必須釋放連接*/
HttpGet httpGet = new HttpGet(url);
try {
HttpResponse httpResponse = httpClient.execute(httpGet);
// HttpReponse是服務器接收到浏覽器的請求後,處理返回結果常用的一個類。
if(httpResponse.getStatusLine().getStatusCode() == 200) {
/*getStatusLine()
獲得此響應的狀態行。狀態欄可以設置使用setstatusline方法之一,也可以在構造函數初始化*/
InputStream is = httpResponse.getEntity().getContent();
/*getEntity()
獲取此響應的消息實體,如果有。實體是通過調用setentity提供。*/
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
String line;
while ((line = reader.readLine()) != null){
content += line;
}
}
}catch (IOException e)
{
Log.e("http",e.toString());
}
Log.e("sdf",content);
return content;
}
}
注釋的很詳細了
大概就是 有一個getDataByGet方法 然後接受一個url參數 經過一系列請求得到網頁內容 返回一個content
下來就是使用這個類的線程了
public class MainThread implements Runnable{
private String url;
public MainThread(String url){
this.url = url;
}
@Override
public void run() {
NetWorkClass netWorkClass =new NetWorkClass();//new 了一個network類
content = netWorkClass.getDataByGet(url);//接收這個類返回的那個字符串也就是需要解析的那一串
Log.e("qwe",content);
handler.sendEmptyMessage(111);
}
}
就是利用這個線程去得到content 然後通過handle傳遞到主線程去解析
private final android.os.Handler handler = new android.os.Handler(){
public void handleMessage(Message msg){
switch (msg.what){
case 111:
analyseHTML();
if(isGetMore){
mainAdapter.notifyDataSetChanged();
/*每一次notifyDataSetChange()都會引起界面的重繪。當需要修改界面上View的相關屬性的時候,
最後先設置完成再調用notifyDataSetChange()來重繪界面。*/
}else {
mainAdapter = new MainAdapter(MainActivity.this, list);
pullListView.setAdapter(mainAdapter);
}
pullListView.refreshComplete();
pullListView.getMoreComplete();
break;
}
}
};
analyseHTML();
發現其實解析的東西在這個方法裡面 所以 這裡才是解析網頁的東西啊:
public void analyseHTML(){
if(content!=null){
int x= 0;
Document document = Jsoup.parse(content);
//解析HTML字符串
if (!isGetMore) {
list.clear();
Element element = document.getElementById("fanye3942");//拿到fanye3942這個節點
String text = element.text();//得到這個節點的文本部分
System.out.print(text);
num = Integer.parseInt(text.substring(text.lastIndexOf('/') + 1, text.length() - 1));
System.out.print(num);
}
Elements elements = document.getElementsByClass("c3942");//得到c3942這個節點中的所有子節點
while(true){
if(x==elements.size()){
System.out.print(elements.size());
break;//遍歷到最後就退出
}
News news = new News();
news.setTitle(elements.get(x).attr("title"));//分別得到每一個子節點的需要的文本部分
news.setUrl(elements.get(x).attr("href"));
// list.add(news);
if (!isGetMore||x>10){
list.add(news);
if(x>=25){
break;
}//這個是因為我們學校的網頁有重復
}
x++;
}
if (num>1){
nextPage = url+"/"+ --num+".htm";//因為有翻頁這裡得到了下一頁的url在上拉的時候會開啟線程去請求數據
System.out.println("qqqqqqqqqqq"+nextPage);
}
}
}
Document 對象使我們可以從腳本中對 HTML 頁面中的所有元素進行訪問。
所以android基於Jsoup 把content搞成Document 對象
然後就可以慢慢分解去拿了 然後拿哪裡的數據就要看需要了
我開始一直不知道那些fanye3942 和c3942是啥 後來才知道是需要的數據的節點id或者class

就像這樣
然後把每一次遍歷的數據都加到集合裡面 給listview綁定集合就好了
大概主頁面就是這樣 然後跳轉頁面 就是因為news裡面還放入了每一個新聞點擊之後的url所以傳到NewsActivity中再利用相同的思路去解析顯示就好了
package com.example.katherine_qj.news;
import android.app.Activity;
import android.os.Bundle;
import android.os.Message;
import android.util.Log;
import android.widget.EditText;
import android.widget.TextView;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* Created by Katherine-qj on 2016/7/25.
*/
public class NewsActivity extends Activity {
private TextView textTitle;
private TextView textEdit;
private TextView textDetail;
private String title;
private String edit;
private String detail;
private StringBuilder text;
private String url;
private Document document;
private String content;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_news);
InitView();
url=getIntent().getStringExtra("url");
Log.e("qqq",url);
NewsThread newsThread = new NewsThread(url);
final Thread t = new Thread(newsThread,"NewsActivity");
t.start();
}
public void InitView(){
textTitle =(TextView)findViewById(R.id.textTitle);
textEdit =(TextView)findViewById(R.id.textEdit);
textDetail = (TextView)findViewById(R.id.textDetail);
}
private final android.os.Handler handler = new android.os.Handler(){
public void handleMessage(Message msg){
if(msg.what==1001){
document = Jsoup.parse(content);
analyseHTML(document);
textTitle.setText(title);
textEdit.setText(edit);
textDetail.setText(text);
}
}
};
public class NewsThread implements Runnable{
String url;
public NewsThread(String url){
this.url = url;
}
@Override
public void run() {
NetWorkClass netWorkClass = new NetWorkClass();
content = netWorkClass.getDataByGet(url);
System.out.print("qqq"+content);
handler.sendEmptyMessage(1001);
}
}
public void analyseHTML(Document document){
if (document!=null){
Element element = document.getElementById("nrys");
Elements elements = element.getAllElements();
title = elements.get(1).text();
edit = elements.get(4).text();
Element mElement = document.getElementById("vsb_content_1031");
if(mElement != null) {
Elements mElements = mElement.getAllElements();
text = new StringBuilder();
for (Element melement : mElements) {
if(melement.className().equals("nrzwys") || melement.tagName().equals("strong")){
continue;
}
if(!melement.text().equals(" ") && !melement.text().equals(""));{
text.append(" ").append(melement.text()).append("\n");
}
if (melement.className().equals("vsbcontent_end")) {
break;
}
}
}
}
}
}
以上就是基於Android編寫簡單的網絡爬蟲的全部內容,本文介紹的很詳細,希望給大家在Android開發的過程中有所幫助。
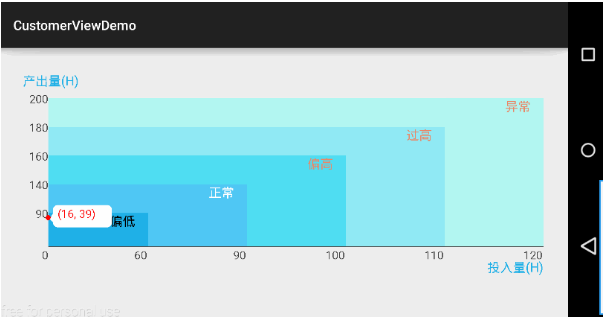 Android自定義控件(實現狀態提示圖表)
Android自定義控件(實現狀態提示圖表)
前面分析那麼多系統源碼了,也該暫停下來休息一下,趁昨晚閒著看見一個有意思的需求就操練一下分析源碼後的實例演練—-自定義控件。這個實例很適合新手入門自定義控件。先看下效果圖
 淺談RecyclerView(完美替代ListView,GridView)
淺談RecyclerView(完美替代ListView,GridView)
Android RecyclerView 是Android5.0推出來的,導入support-v7包即可使用。個人體驗來說,RecyclerView絕對是一款功能強大的控
 設計模式MVC for Android
設計模式MVC for Android
算來學習Android開發已有2年的歷史了,在這2年的學習當中,基本掌握了Android的基礎知識。越到後面的學習越感覺困難,一來是自認為android沒啥可學的了(自認
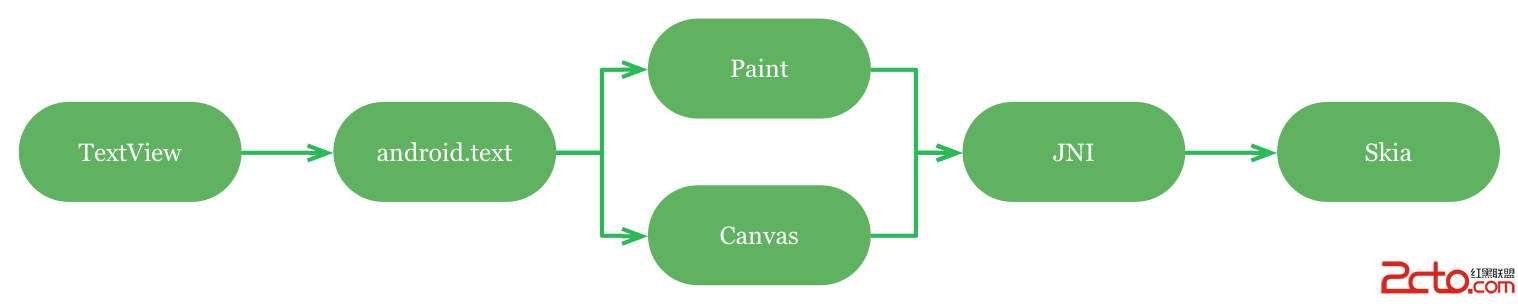 Android的文字渲染
Android的文字渲染
一種使用OpenGL渲染文字的常用方法,是計算出一個包含了顯示文字的紋理圖片,這通常是使用相當復雜的打包算法來最小化紋理中的冗余部分,在創建這樣的圖片之前必須清楚應用運行