編輯:關於Android編程
在網絡上傳輸數據時最常用的格式有兩種,XML和JSON,下面首先學一下如何解析XML格式的數據。解析XML 格式的數據其實也有挺多種方式的,本節中我們學習比較常用的兩種,Pull解析和SAX 解析。
一、我們常用的五個事件:
START DOCUMENT:文檔開始時,解析器還沒有讀取任何數據START_TAG:解析到標簽開頭TEXT:解析到元素的內容END_TAG:解析在標簽的末尾END_DOCUMENT:文檔結束,之後不會再解析了二、PULL解析的步驟:
創建一個XMLPULL工廠實例:XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
不指定命名空間的話,將使用默認的解析器。若要改變命名空間,用setNamespaceAware()這個方法:factory.setNamespaceAware(true);
創建一個解析的實例:XmlPullParser xpp = factory.newPullParser();
解析輸入的數據:xpp.setInput ( new FileReader (filename ) );
接下來就可以根據不同的事件,做不同的解析處理:一般用next()方法去得到下一個事件三、next()方法與nextToken()方法:
next()方法只能支持上述常用的5種事件:nextToken()方法不但支持next()方法的事件,還額外支持:COMMENT, CDSECT, DOCDECL, ENTITY_REF, PROCESSING_INSTRUCTION, or IGNORABLE_WHITESPACE
我們在assets中創建了一個文件: linux.xml
在MainActivity.xml中定義一個方法,得到linux.xml文件的內容蓋倫 德瑪西亞我將帶頭沖鋒 亞索 艾歐尼亞死亡如風,常伴吾身 瑞雯 諾克薩斯戰爭與謀殺之間,潛藏著我們的心魇
// 得到xml的數據
private String getXMLData(String fileName) {
StringBuffer stringBuffer = new StringBuffer();
InputStream inputStream = null;
BufferedReader bufferedReader = null;
try {
inputStream = getResources().getAssets().open(fileName);
bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String line = "";
while ((line = bufferedReader.readLine()) != null) {
stringBuffer.append(line + "\n");
}
bufferedReader.close();
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bufferedReader != null) {
bufferedReader.close();
}
if (inputStream != null) {
inputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
Log.i(TAG, stringBuffer.toString());
return stringBuffer.toString();
}
定義一個方法,用PULL解析得到的數據:
// pull解析xml數據
public void pullParse(View view) {
String xmlData = getXMLData(fileName);
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser xmlPullParser = factory.newPullParser();
xmlPullParser.setInput(new StringReader(xmlData));
int eventType = xmlPullParser.getEventType();
String name = "";
String address = "";
String say = "";
String sex = "";
while (eventType != XmlPullParser.END_DOCUMENT) {
String nodeName = xmlPullParser.getName();
switch (eventType) {
case XmlPullParser.START_TAG: {
if ("name".equals(nodeName)) {
// sex與name的位置不能互換
// sex = xmlPullParser.getAttributeValue(0);
sex = xmlPullParser.getAttributeValue(null, "sex");
name = xmlPullParser.nextText();
} else if ("address".equals(nodeName)) {
address = xmlPullParser.nextText();
} else if ("say".equals(nodeName)) {
say = xmlPullParser.nextText();
}
break;
}
// 完成解析某個結點
case XmlPullParser.END_TAG: {
if ("person".equals(nodeName)) {
Log.d(TAG, "name: " + name);
Log.d(TAG, "address: " + address);
Log.d(TAG, "say: " + say);
Log.d(TAG, "sex: " + sex);
}
break;
}
default:
break;
}
eventType = xmlPullParser.next();
}
} catch (Exception e) {
e.printStackTrace();
}
}
若要解析到裡面的注釋內容,需要做以下的修改:增加case,修改next()方法為nextToken()方法:
// 增加一個case,用於接收注釋的事件
case XmlPullParser.COMMENT: {
coment = xmlPullParser.getText();
break;
}
default:
break;
}
eventType = xmlPullParser.nextToken(); // 此處為修改部分
打印日志如下:(增加了注釋的功能)
03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: name: 蓋倫 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: address: 德瑪西亞 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: say: 我將帶頭沖鋒 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: sex: man 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: comment: 這裡是蓋倫的注釋 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: name: 亞索 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: address: 艾歐尼亞 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: say: 死亡如風,常伴吾身 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: sex: man 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: comment: 這裡是亞索的注釋 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: name: 瑞雯 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: address: 諾克薩斯 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: say: 戰爭與謀殺之間,潛藏著我們的心魇 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: sex: girl 03-16 18:09:59.662 24745-24745/com.example.linux.xmlparsetest D/MainActivity: comment: 這裡是瑞雯的注釋
一、 SAX解析的簡要:
SAX:事件驅動型的XML解析方式。順序讀取XML文件,不需要一次全部裝載整個文件。當遇到像文件開頭,文檔結束,或者標簽開頭與標簽結束時,會觸發一個事件,用戶通過在其回調事件中寫入處理代碼來處理XML文件,適合對XML的順序訪問,且是只讀的。由於移動設備的內存資源有限,SAX的順序讀取方式更適合移動開發。
二、 SAX解析XML步驟:
創建XML解析處理器。創建SAX解析器。將XML解析處理器分配給解析器。對文檔進行解析,將每個事件發送給處理器。三、SAX解析的過程:
解析開始之前,需要向XMLReader注冊一個ContentHandler,也就是相當於一個事件監聽器,在ContentHandler中定義了很多方法,比如startDocument(),它定制了當在解析過程中,遇到文檔開始時應該處理的事情。當 XMLReader讀到合適的內容,就會拋出相應的事件,並把這個事件的處理權代理給ContentHandler,調用其相應的方法進行響應。
package com.example.linux.xmlparsetest;
import android.util.Log;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
/**
* Created by Linux on 2016/3/16.
*/
public class ContentHandler extends DefaultHandler {
private final static String TAG = "MainActivity";
private String nodeName;
private StringBuilder name;
private StringBuilder address;
private StringBuilder say;private StringBuilder sex;
// 文檔開始時執行
@Override
public void startDocument() throws SAXException {
name = new StringBuilder();
address = new StringBuilder();
say = new StringBuilder();
sex = new StringBuilder();
coment = new StringBuilder();
}
// 元素開始時執行
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 記錄當前結點名
nodeName = localName;
if (nodeName.equals("name") && attributes != null) {
sex.append(attributes.getValue("sex"));
}
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// 根據當前的結點名判斷將內容添加到哪一個StringBuilder對象中
if ("name".equals(nodeName)) {
name.append(ch, start, length);
} else if ("address".equals(nodeName)) {
address.append(ch, start, length);
} else if ("say".equals(nodeName)) {
say.append(ch, start, length);
}
}
// 元素結束時執行
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if ("person".equals(localName)) {
Log.d(TAG, "name is " + name.toString().trim());
Log.d(TAG, "adress is " + address.toString().trim());
Log.d(TAG, "say is " + say.toString().trim());
Log.d(TAG, "sex is " + sex.toString().trim());
// 最後要將StringBuilder清空掉
name.setLength(0);
address.setLength(0);
say.setLength(0);
sex.setLength(0);
}
}
// 文檔結束時
@Override
public void endDocument() throws SAXException {
super.endDocument();
}
}
在MainActivity中定義方法,來進行SAX解析
// sax解析數據
public void saxParse(View view) {
String xmlData = getXMLData(fileName);
try {
SAXParserFactory factory = SAXParserFactory.newInstance();
XMLReader xmlReader = factory.newSAXParser().getXMLReader();
ContentHandler handler = new ContentHandler();
// 將ContentHandler的實例設置到XMLReader中
xmlReader.setContentHandler(handler);
// 開始執行解析
xmlReader.parse(new InputSource(new StringReader(xmlData)));
} catch (Exception e) {
e.printStackTrace();
}
}
打印日志如下:
03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: name is 蓋倫 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: adress is 德瑪西亞 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: say is 我將帶頭沖鋒 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: sex is man 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: name is 亞索 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: adress is 艾歐尼亞 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: say is 死亡如風,常伴吾身 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: sex is man 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: name is 瑞雯 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: adress is 諾克薩斯 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: say is 戰爭與謀殺之間,潛藏著我們的心魇 03-16 18:10:55.732 24745-24745/com.example.linux.xmlparsetest D/MainActivity: sex is girl
區別:
SAX解析器的工作方式是自動將事件推入注冊的事件處理器進行處理,因此你不能控制事件的處理主動結束PULL解析器的工作方式為允許你的應用程序代碼主動從解析器中獲取事件,正因為是主動獲取事件,因此可以在滿足了需要的條件後不再獲取事件,結束解析
相似性:
Pull解析器也提供了類似SAX的事件,開始文檔START_DOCUMENT和結束文檔END_DOCUMENT,開始元素START_TAG和結束元素END_TAG,遇到元素內容TEXT等,但需要調用next() 方法提取它們(主動提取事件)。
使用:
如果在一個XML文檔中我們只需要前面一部分數據,但是使用SAX方式或DOM方式會對整個文檔進行解析,盡管XML文檔中後面的大部分數據我們其實都不需要解析,因此這樣實際上就浪費了處理資源。使用PULL方式正合適。
 Android平台一款UI體驗好於NumberPicker的自定義控件NumberPickerView
Android平台一款UI體驗好於NumberPicker的自定義控件NumberPickerView
NumberPickerViewanother NumberPicker with more flexible attributes on Android platfor
 Android常用界面布局(二)
Android常用界面布局(二)
ImageView ScaleType屬性, 該屬性用以表示顯示圖片的方式 ①matrix 根據一個3x3的矩陣對其中圖片進行縮放 ②fitX
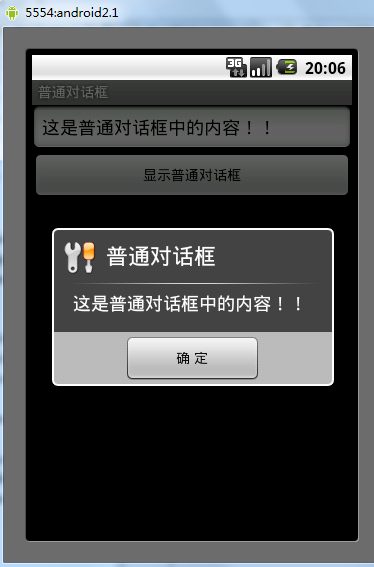 Android普通對話框用法實例分析
Android普通對話框用法實例分析
本文實例講述了Android普通對話框用法。分享給大家供大家參考。具體如下:main.xml布局文件:<?xml version=1.0 encoding=
 Android實現二維碼掃描並登陸網頁
Android實現二維碼掃描並登陸網頁
之前寫過一個二維碼掃描demo,用的Zxing的框架,點擊下載,後續掃描二維碼中出現一些問題,比如解決壓縮圖片,調整掃描窗口大小等等。後續單位要求做掃描登錄實現,發現難點