編輯:關於Android編程
之前在網上搜索了好多好多關於CNN,卷積神經網絡的文章,很多都講如何卷積、卷積層如何操作、具體如何進行卷積計算、卷積的好處。我也在此之前走了好多彎路,已經很了解如何卷積了,但是卻不知道物理意義上,卷積與神經網絡之間的聯系。
但是鑒於大量的文章在網絡上層出不窮地重復與累贅,更重要的是對於 卷積神經網絡 一詞當中,很多人都忽略了 神經網絡 而去強調如何 卷積,因此本文主要講述卷積神經網絡中最重要的部分, 神經網絡。希望看完這篇文章和相關卷積神經網絡ConvsNet的人能夠搞懂 NN 與 Conv 之間的聯系與物理意義。
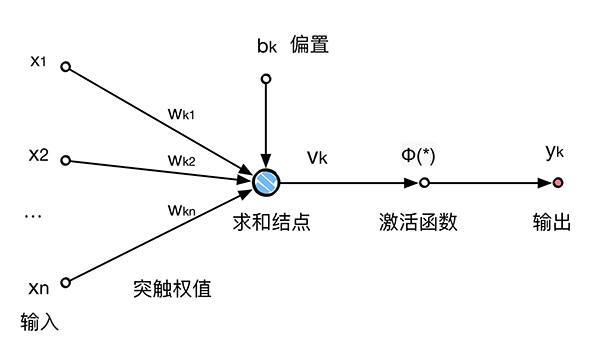
神經元是神經網絡操作的基本信息處理單位。下圖給出了神經元的模型model,這張圖是後續章節單重將要探討的設計(人工)神經網絡Big Family的基礎。我們在這裡給出了神經元模型的三種基本元素:
突觸 或者 鏈接鏈集, 每一個都由其 權值 或者 強度 作為特征。具體來說,在連接到神經元k的突觸 j 上的輸入信號 xj 被乘以 k 的突觸權值
加法器,用於求輸入信號干杯神經元的相應突觸加權的和。這個操作構成一個線性組合器。
激活函數,用來限制神經元輸出振幅。由於通過激活函數將輸出信號壓制(限制)到允許范圍之內的一定值,故而激活函數也被稱之為壓制函數。通常,一個神經元輸出的正常幅度范圍可寫成單位區間 [0, 1] 或者另一種區間 [-1, +1]。
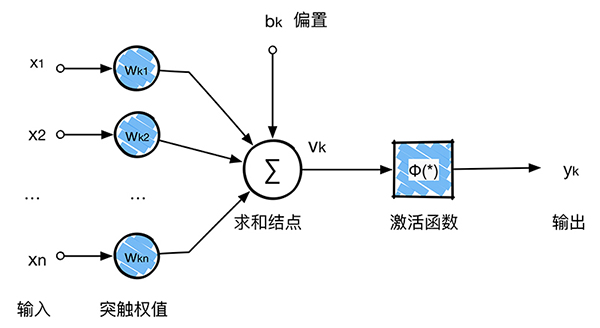
圖1的神經元也包括了一個外部偏置(bias),記為
用數學的公式來表示,我們可以用下面的方程描述上圖1的神經元
其中
激活函數
此函數的圖形是S形狀的,在構造人工神經網絡中是最常見的激活函數,注意了,這裡在 卷積神經網絡 當中並不是最常見的,而是第三種 ReLu函數,因為ReLu計算起來更加簡單,可以大大縮小計算時間。回到sigmoid函數,它是嚴格遞增函數,在線性和非線性行為之間顯現出較好的平衡。sigmoid函數的第一個例子就是logistic函數,定義如下:
其中
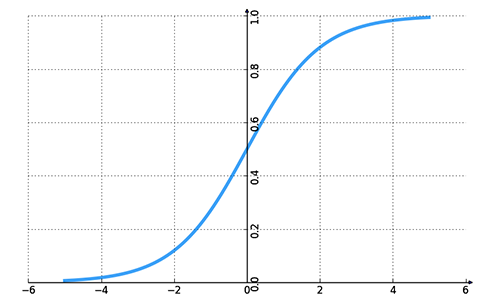
下面是更加科學的解釋為何激活函數使用sigmoid函數:
從數學意義來看,非線性的Sigmoid函數對中央區的信號增益較大,對兩側區的信號增益小,在信號的特征空間映射上,有很好的效果。
從神經科學上來看,中央區酷似神經元的興奮態,兩側區酷似神經元的抑制態,因而在神經網絡學習方面,可以將重點特征推向中央區,將非重點特征推向兩側區。
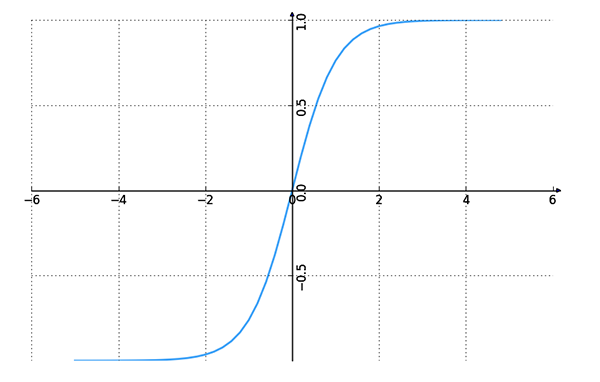
雙曲函數出現於某些重要的線性微分方程的解中,譬如說定義懸鏈線和拉普拉斯方程。
與 sigmoid 不同的是,tanh 是0均值的。因此,實際應用中,tanh 會比 sigmoid 更好。
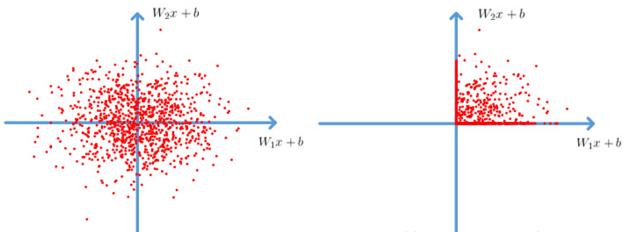
很顯然,從圖左可以看出,輸入信號<0時,輸出都是0,>0 的情況下,輸出等於輸入。w 是二維的情況下,使用ReLU之後的效果如下:
ReLU 的優點:
Krizhevsky et al. 發現使用 ReLU 得到的SGD的收斂速度會比 sigmoid/tanh 快很多。 相比於sigmoid/tanh,ReLU 只需要一個阈值就可以得到激活值,而不用去算一大堆復雜的運算。ReLU 的缺點:
當在神經網絡中學習速率很大的時候,很有可能網絡中大部分神經元都會變成0。
當然,如果設置一個合適而且較小的學習速率的話,此類問題發生的情況也不會太頻繁。同時,為了解決這個問題,後面出現了各種ReLU的變種:Leaky-ReLU、P-ReLU、R-ReLU。
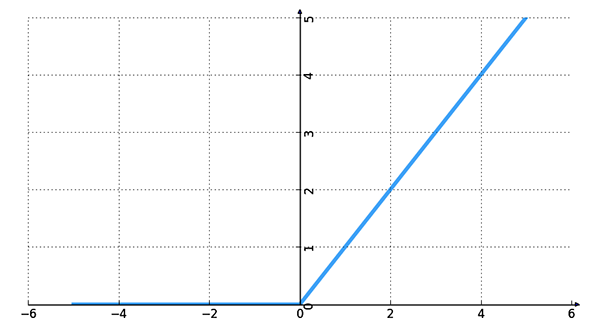
圖1中提供了構成人工神經元模型各個要素的功能描述。我們可以在補習生模型功能細節的條件下用信號流圖來簡化模型外觀。圖形中各部分的信號流動遵從三條基本規則。
信號僅僅沿定義好的箭頭方向在鏈接上流動。 節點信號等於經有連接進入的有關節點的所有信號的代數和。 節點信號沿著每個外向鏈接外向傳遞,此時傳遞的信號完全獨立於外向鏈接的傳遞函數。
上圖是一個單環反饋系統的信號流圖,在這裡只做簡單的介紹帶過。因為對CNN並沒有太大的關系,只是一個概念地存在著。輸入信號為
從上面兩個式子可以消去x_{j}^{‘}(n):
OK。公式推導到這裡為止啦,反饋網絡現在用的最多的是在工控領域、模式識別中。
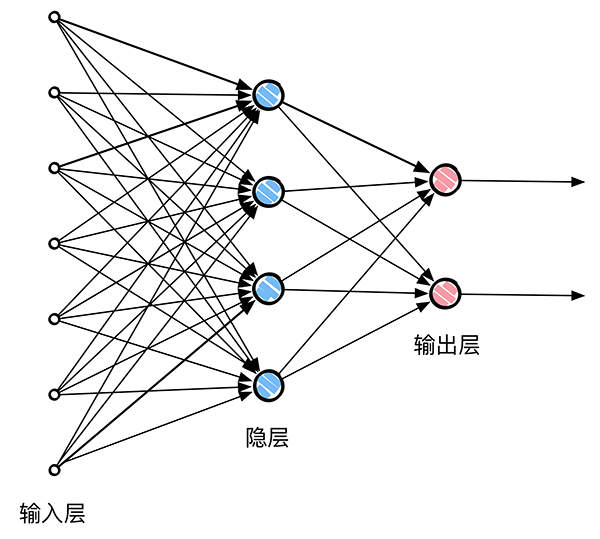
在分層網絡中,神經元以層的形式組織。相應的計算節點稱為隱藏神經元或隱藏單元。隱藏是指神經網絡的這一部分無論從網絡的輸入端或者輸出端都不能直接看到。隱藏神經元的功能是以某種有用的方式接入外部輸入和網絡輸出中的。
多層網絡可以根據其輸入引出高階統計特性, 即使網絡為局部連接,由於格外的突觸連接和額外的神經交互作用,也可以使網絡在不十分嚴格的意義下獲得一個全局關系。這也就是CNN使用局部連接之後還獲得很好的效果的原因。
在物理意義上,CNN其實也是上圖這樣的一個神經網絡,其卷積核就是權值的集合,例如一個卷積核是3*3大小,實際上是由9個權值組合而成的。通過大量的輸入進行訓練,為的就是得到這些權值,然後下一次有新的輸入的時候,直接由之前已經訓練好的權值和偏置對輸入進行計算,直接得到輸出。更加詳細的會在後續的面包中講解。
到這裡為止,很重要的一點是認識到單一個神經元的模型定義,從輸入到求和,加上偏置值對求和進行微調,輸出前經過一個激活函數。現在我們已經很詳細地講解了一下激活函數
 在 Android* 商務應用中實施地圖和地理圍欄特性
在 Android* 商務應用中實施地圖和地理圍欄特性
摘要 本案例研究討論了如何將地圖和地理定位特性構建到 Android* 商務應用中,包括在 Google Maps* 上覆蓋商店位置,以及在設備進入商店地理圍欄鄰近區
 Android 自定義UI圓角按鈕
Android 自定義UI圓角按鈕
Android實際開發中我們一般需要圓角的按鈕,一般情況下我們可以讓美工做出來相應的按鈕圖片,然後放上去即可,另外我們可以在布局文件中直接設置,也可以達到一樣的效果。下面
 android 沉浸式狀態欄(像ios那樣的狀態欄與應用統一顏色樣式)
android 沉浸式狀態欄(像ios那樣的狀態欄與應用統一顏色樣式)
這個特性是andorid4.4支持的,最少要api19才可以使用。下面介紹一下使用的方法,非常得簡單: public class MainActivity ex
 Android之在IntentService中執行後台程序
Android之在IntentService中執行後台程序
除非我們特別為某個操作指定特定的線程,否則大部分在前台UI界面上的操作任務都執行在一個叫做UI Thread的特殊線程中。這可能存在某些隱患,因為部分在UI界面上的耗時操