編輯:關於Android編程
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
看這個參數很容易讓人以為是線程池裡保持corePoolSize個線程,如果不夠用,就加線程入池直至maximumPoolSize大小,如果還不夠就往workQueue裡加,如果workQueue也不夠就用RejectedExecutionHandler來做拒絕處理。
但實際情況不是這樣,具體流程如下:
1)當池子大小小於corePoolSize就新建線程,並處理請求
2)當池子大小等於corePoolSize,把請求放入workQueue中,池子裡的空閒線程就去從workQueue中取任務並處理
3)當workQueue放不下新入的任務時,新建線程入池,並處理請求,如果池子大小撐到了maximumPoolSize就用RejectedExecutionHandler來做拒絕處理
4)另外,當池子的線程數大於corePoolSize的時候,多余的線程會等待keepAliveTime長的時間,如果無請求可處理就自行銷毀
內部結構如下所示:
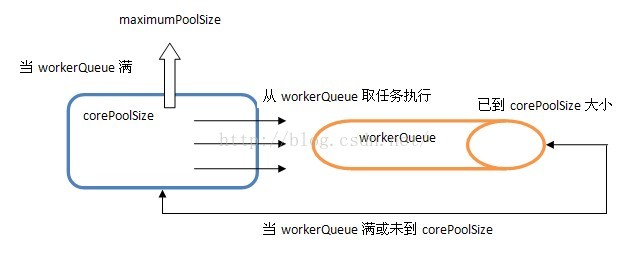
從中可以發現ThreadPoolExecutor就是依靠BlockingQueue的阻塞機制來維持線程池,當池子裡的線程無事可干的時候就通過workQueue.take()阻塞住。
其實可以通過Executes來學學幾種特殊的ThreadPoolExecutor是如何構建的。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
newFixedThreadPool就是一個固定大小的ThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
newCachedThreadPool比較適合沒有固定大小並且比較快速就能完成的小任務,沒必要維持一個Pool,這比直接new Thread來處理的好處是能在60秒內重用已創建的線程。
其他類型的ThreadPool看看構建參數再結合上面所說的特性就大致知道它的特性
線程池工具類: ThreadPoolFactory 線程池工廠類 ThreadPoolProxy 線程池代理類 ThreadPoolUtils 線程池工具類 ThreadPoolFactory :
public class ThreadPoolFactory {
public static ThreadPoolProxy normalThreadPool;
public static final int NORMAL_COREPOOLSIZE = 5;
public static final int NORMAL_MAXIMUMPOOLSIZE = 5;
public static final long NORMAL_KEEPALIVETIME = 60;
public static ThreadPoolProxy getNormalThreadPool() {
//雙重檢測機制
if (normalThreadPool == null) {
synchronized (ThreadPoolFactory.class) {
if (normalThreadPool == null) {
normalThreadPool = new ThreadPoolProxy(NORMAL_COREPOOLSIZE,NORMAL_MAXIMUMPOOLSIZE,NORMAL_KEEPALIVETIME);}
}
}
return normalThreadPool;
}
}
ThreadPoolProxy:
public class ThreadPoolProxy {
ThreadPoolExecutor executor;
int corePoolSize;
int maximumPoolSize;
long keepAliveTime;
public ThreadPoolProxy(int corePoolSize, int maximumPoolSize, long keepAliveTime) {
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.keepAliveTime = keepAliveTime;
}
public void initThreadPoolProxy() {
//雙重檢測機制
if (executor == null) {
synchronized (ThreadPoolExecutor.class) {
if (executor == null) {
BlockingQueue workQueue = new LinkedBlockingDeque<>();
ThreadFactory threadFactory = Executors.defaultThreadFactory();
RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy();
executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.SECONDS, workQueue, threadFactory, handler);
}
}
}
}
public void exector(Runnable runnable) {
initThreadPoolProxy();
executor.execute(runnable);
}
public void remove(Runnable runnable) {
initThreadPoolProxy();
executor.remove(runnable);
}
}
ThreadPoolUtils:
public class ThreadPoolUtils {
//在UI中執行
static Handler handler = new Handler();
public static void runTaskOnMainThread(Runnable runnable) {
handler.post(runnable);
}
//非UI執行
public static void runTaskOnThread(Runnable runnable) {
ThreadPoolFactory.getNormalThreadPool().exector(runnable);
}
}
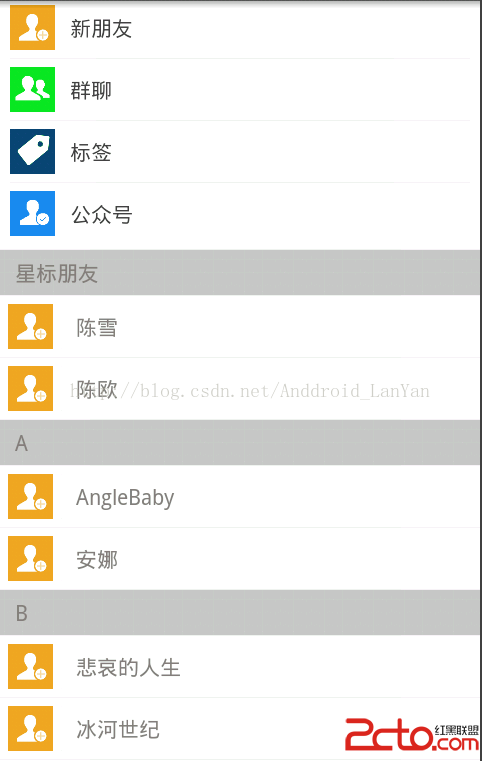 Android PinnedSectionListView 收縮
Android PinnedSectionListView 收縮
網上開源項目:https://github.com/beworker/pinned-section-listview,該項目用的是ArrayAdapter()..不太適合
 Android studio 出現 Unsupported major.minor version 52.0解決辦法
Android studio 出現 Unsupported major.minor version 52.0解決辦法
Android studio 出現 Unsupported major.minor version 52.0解決辦法 最近更新了Android studio
 高德地圖查看街景方法 手機高德地圖怎麼看街景
高德地圖查看街景方法 手機高德地圖怎麼看街景
手機高德地圖怎麼看街景呢?高德地圖查看街景方法是什麼呢?下面,小編來教教大家如何利用手機高德地圖來看街景。高德地圖app查看街景方法第一步、打開手機版【高德
 Android Service詳解及示例代碼
Android Service詳解及示例代碼
Android Service 詳細介紹:1、Service的概念 2、Service的生命周期 3、實例:控制音樂播放的Service一、Service的概念Servi