編輯:關於Android編程
現在越來越多的應用開始重視流暢度方面的測試,了解Android應用程序是如何在屏幕上顯示的則是基礎中的基礎,就讓我們一起看看小小屏幕中大大的學問。這也是我下篇文章——《Android應用流暢度測試分析》的基礎。
首先,用一句話來概括一下Android應用程序顯示的過程:Android應用程序調用SurfaceFlinger服務把經過測量、布局和繪制後的Surface渲染到顯示屏幕上。
名詞解釋
SurfaceFlinger:Android系統服務,負責管理Android系統的幀緩沖區,即顯示屏幕。
Surface:Android應用的每個窗口對應一個畫布(Canvas),即Surface,可以理解為Android應用程序的一個窗口。
Android應用程序的顯示過程包含了兩個部分(應用側繪制、系統側渲染)、兩個機制(進程間通訊機制、顯示刷新機制),接下來我們就來一一道來。
應用側
一個Android應用程序窗口裡面包含了很多UI元素,這些UI元素是以樹形結構來組織的,即它們存在著父子關系,其中,子UI元素位於父UI元素裡面,如下圖:

因此,在繪制一個Android應用程序窗口的UI之前,我們首先要確定它裡面的各個子UI元素在父UI元素裡面的大小以及位置。確定各個子UI元素在父UI元素裡面的大小以及位置的過程又稱為測量過程和布局過程。因此,Android應用程序窗口的UI渲染過程可以分為測量、布局和繪制三個階段。如下圖所示:
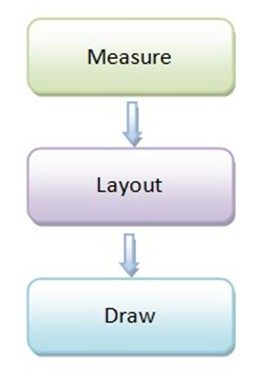
測量:遞歸(深度優先)確定所有視圖的大小(高、寬)
布局:遞歸(深度優先)確定所有視圖的位置(左上角坐標)
繪制:在畫布canvas上繪制應用程序窗口所有的視圖
測量、布局沒有太多要說的,這裡要著重說一下繪制。Android目前有兩種繪制模型:基於軟件的繪制模型和硬件加速的繪制模型(從Android 3.0開始全面支持)。
在基於軟件的繪制模型下,CPU主導繪圖,視圖按照兩個步驟繪制:
1.讓View層次結構失效
2.繪制View層次結構
當應用程序需要更新它的部分UI時,都會調用內容發生改變的View對象的invalidate()方法。無效(invalidation)消息請求會在View對象層次結構中傳遞,以便計算出需要重繪的屏幕區域(髒區)。然後,Android系統會在View層次結構中繪制所有的跟髒區相交的區域。不幸的是,這種方法有兩個缺點:
1.繪制了不需要重繪的視圖(與髒區域相交的區域)
2.掩蓋了一些應用的bug(由於會重繪與髒區域相交的區域)
注意:在View對象的屬性發生變化時,如背景色或TextView對象中的文本等,Android系統會自動的調用該View對象的invalidate()方法。
在基於硬件加速的繪制模式下,GPU主導繪圖,繪制按照三個步驟繪制:
1.讓View層次結構失效
2.記錄、更新顯示列表
3.繪制顯示列表
這種模式下,Android系統依然會使用invalidate()方法和draw()方法來請求屏幕更新和展現View對象。但Android系統並不是立即執行繪制命令,而是首先把這些View的繪制函數作為繪制指令記錄一個顯示列表中,然後再讀取顯示列表中的繪制指令調用OpenGL相關函數完成實際繪制。另一個優化是,Android系統只需要針對由invalidate()方法調用所標記的View對象的髒區進行記錄和更新顯示列表。沒有失效的View對象則能重放先前顯示列表記錄的繪制指令來進行簡單的重繪工作。
使用顯示列表的目的是,把視圖的各種繪制函數翻譯成繪制指令保存起來,對於沒有發生改變的視圖把原先保存的操作指令重新讀取出來重放一次就可以了,提高了視圖的顯示速度。而對於需要重繪的View,則更新顯示列表,以便下次重用,然後再調用OpenGL完成繪制。
硬件加速提高了Android系統顯示和刷新的速度,但它也不是萬能的,它有三個缺陷:
1.兼容性(部分繪制函數不支持或不完全硬件加速,參見文章尾)
2.內存消耗(OpenGL API調用就會占用8MB,而實際上會占用更多內存)
3.電量消耗(GPU耗電)
系統側
Android應用程序在圖形緩沖區中繪制好View層次結構後,這個圖形緩沖區會被交給SurfaceFlinger服務,而SurfaceFlinger服務再使用OpenGL圖形庫API來將這個圖形緩沖區渲染到硬件幀緩沖區中。
由於Android應用程序很少能涉及到Android系統底層,所以SurfaceFlinger服務的執行過程不做過多的介紹。
進程間通訊機制
Android應用程序為了能夠將自己的UI繪制在系統的幀緩沖區上,它們就必須要與SurfaceFlinger服務進行通信,如圖所示:
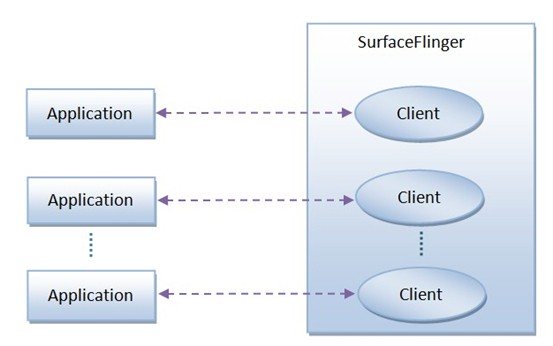
Android應用程序與SurfaceFlinger服務是運行在不同的進程中的,因此,它們采用某種進程間通信機制來進行通信。由於Android應用程序在通知SurfaceFlinger服務來繪制自己的UI的時候,需要將UI數據傳遞給SurfaceFlinger服務,例如,要繪制UI的區域、位置等信息。一個Android應用程序可能會有很多個窗口,而每一個窗口都有自己的UI數據,因此,Android系統的匿名共享內存機制就派上用場了。
每一個Android應用程序與SurfaceFlinger服務之間,都會通過一塊匿名共享內存來傳遞UI數據,如下所示:
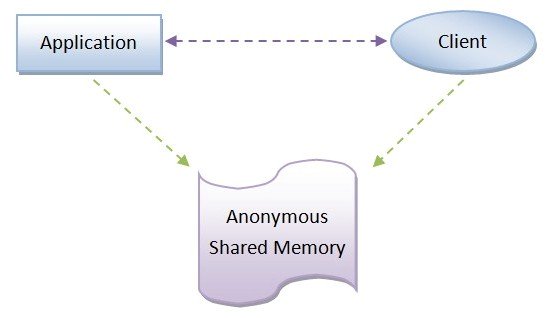
但是單純的匿名共享內存在傳遞多個窗口數據時缺乏有效的管理,所以匿名共享內存就被抽象為一個更上流的數據結構SharedClient,如下圖所示:
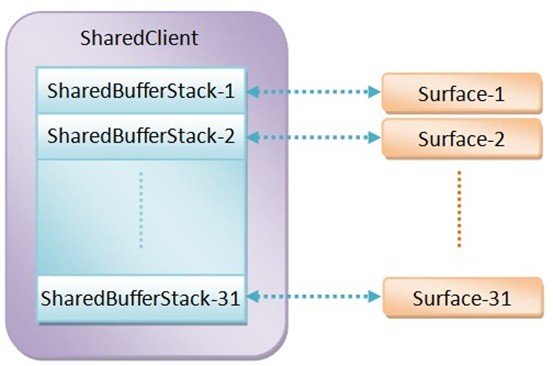
在每個SharedClient中,最多有31個SharedBufferStack,每個SharedBufferStack都對應一個Surface,即一個窗口。這樣,我們就可以知道為什麼每一個SharedClient裡面包含的是一系列SharedBufferStack而不是單個SharedBufferStack:一個SharedClient對應一個Android應用程序,而一個Android應用程序可能包含有多個窗口,即Surface。從這裡也可以看出,一個Android應用程序至多可以包含31個窗口。
每個SharedBufferStack中又包含了N個緩沖區(<4.1 N=2; >=4.1 N=3),即顯示刷新機制中即將提到的雙緩沖和三重緩沖技術。
顯示刷新機制
一般我們在繪制UI的時候,都會采用一種稱為“雙緩沖”的技術。雙緩沖意味著要使用兩個緩沖區(SharedBufferStack中),其中一個稱為Front Buffer,另外一個稱為Back Buffer。UI總是先在Back Buffer中繪制,然後再和Front Buffer交換,渲染到顯示設備中。理想情況下,這樣一個刷新會在16ms內完成(60FPS),下圖就是描述的這樣一個刷新過程(Display處理前Front Buffer,CPU、GPU處理Back Buffer。
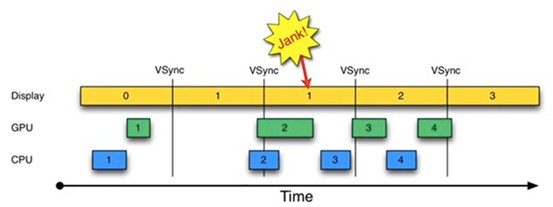
但現實情況並非這麼理想。
1.時間從0開始,進入第一個16ms:Display顯示第0幀,CPU處理完第一幀後,GPU緊接其後處理繼續第一幀。三者互不干擾,一切正常。
2.時間進入第二個16ms:因為早在上一個16ms時間內,第1幀已經由CPU,GPU處理完畢。故Display可以直接顯示第1幀。顯示沒有問題。但在本16ms期間,CPU和GPU卻並未及時去繪制第2幀數據(注意前面的空白區),而是在本周期快結束時,CPU/GPU才去處理第2幀數據。
3.時間進入第3個16ms,此時Display應該顯示第2幀數據,但由於CPU和GPU還沒有處理完第2幀數據,故Display只能繼續顯示第一幀的數據,結果使得第1幀多畫了一次(對應時間段上標注了一個Jank)。
通過上述分析可知,此處發生Jank的關鍵問題在於,為何第1個16ms段內,CPU/GPU沒有及時處理第2幀數據?原因很簡單,CPU可能是在忙別的事情,不知道該到處理UI繪制的時間了。可CPU一旦想起來要去處理第2幀數據,時間又錯過了!
為解決這個問題,Android 4.1中引入了VSYNC,這類似於時鐘中斷。結果如下圖所示:
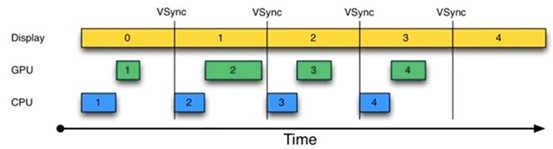
由上圖可知,每收到VSYNC中斷,CPU就開始處理各幀數據。整個過程非常完美。
不過,仔細琢磨後卻會發現一個新問題:上圖中,CPU和GPU處理數據的速度似乎都能在16ms內完成,而且還有時間空余,也就是說,CPU/GPU的FPS(幀率,Frames Per Second)要高於Display的FPS。確實如此。由於CPU/GPU只在收到VSYNC時才開始數據處理,故它們的FPS被拉低到與Display的FPS相同。但這種處理並沒有什麼問題,因為Android設備的Display FPS一般是60,其對應的顯示效果非常平滑。
如果CPU/GPU的FPS小於Display的FPS,會是什麼情況呢?請看下圖:
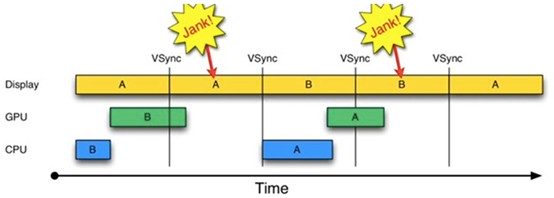
由上圖可知:
1.在第二個16ms時間段,Display本應顯示B幀,但卻因為GPU還在處理B幀,導致A幀被重復顯示。
2.同理,在第二個16ms時間段內,CPU無所事事,因為A Buffer被Display在使用。B Buffer被GPU在使用。注意,一旦過了VSYNC時間點,CPU就不能被觸發以處理繪制工作了。
為什麼CPU不能在第二個16ms處開始繪制工作呢?原因就是只有兩個Buffer(Android 4.1之前)。如果有第三個Buffer的存在,CPU就能直接使用它,而不至於空閒。出於這一思路就引出了三重緩沖區(Android 4.1)。結果如下圖所示:
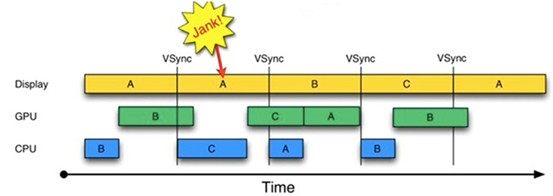
由上圖可知:
第二個16ms時間段,CPU使用C Buffer繪圖。雖然還是會多顯示A幀一次,但後續顯示就比較順暢了。
是不是Buffer越多越好呢?回答是否定的。由上圖可知,在第二個時間段內,CPU繪制的第C幀數據要到第四個16ms才能顯示,這比雙Buffer情況多了16ms延遲。所以,Buffer最好還是兩個,三個足矣。
到這裡,Android系統的顯示原理就介紹完了。那麼在了解這些原理後對我們的流暢度測試有哪些幫助呢,請看我的下篇文章《Android應用流暢度測試分析》。
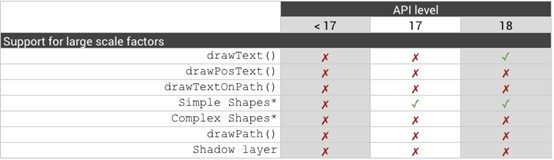
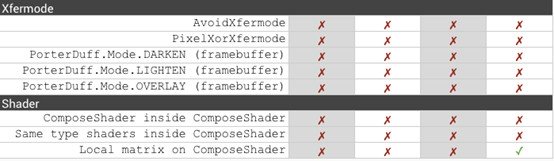
附:不同的API Level下,繪制函數對硬件加速模式的支持情況
 Android4.4 ContentResolver查詢圖片無效 及 圖庫刪除 增加圖片後,ContentResolver不更新的問題解決
Android4.4 ContentResolver查詢圖片無效 及 圖庫刪除 增加圖片後,ContentResolver不更新的問題解決
問題背景: 參考鏈接 做了一個圖片浏覽,用ContentResolver掃描圖庫照片,且嚴格按照時間拍攝順序排好序顯示在listview裡。如下圖所示:遇到的問題是在4.
 listview的上拉加載,下拉刷新
listview的上拉加載,下拉刷新
感覺用到的次數無比多,要是要把它記下來,免得要用的時候又要重來一遍(個人記性太差)先看效果圖接下來,說說要怎麼寫1.首先在.gradle中添加一個jar包gradle-w
 Android drawPath實現QQ拖拽泡泡
Android drawPath實現QQ拖拽泡泡
這兩天學習了使用Path繪制貝塞爾曲線相關,然後自己動手做了一個類似QQ未讀消息可拖拽的小氣泡,效果圖如下:接下來一步一步的實現整個過程。基本原理其實就是使用Path繪制
 Android中visibility屬性VISIBLE、INVISIBLE、GONE的區別
Android中visibility屬性VISIBLE、INVISIBLE、GONE的區別
在Android開發中,大部分控件都有visibility這個屬性,其屬性有3個分別為“visible ”、“invisible&rd