編輯:關於Android編程
今天我們來學習另一種非常重要的數據交換格式-XML。XML(Extensible Markup Language的縮寫,意為可擴展的標記語言),它是一種元標記語言,即定義了用於定義其他特定領域有關語義的、結構化的標記語言,這些標記語言將文檔分成許多部件並對這些部件加以標識。XML 文檔定義方式有:文檔類型定義(DTD)和XML Schema。DTD定義了文檔的整體結構以及文檔的語法,應用廣泛並有豐富工具支持。XML Schema用於定義管理信息等更強大、更豐富的特征。XML能夠更精確地聲明內容,方便跨越多種平台的更有意義的搜索結果。它提供了一種描述結構數據的格式,簡化了網絡中數據交換和表示,使得代碼、數據和表示分離,並作為數據交換的標准格式,因此它常被稱為智能數據文檔。
由於XML具有很強的擴展性,致使它需要很強的基礎規則來支持擴展,所以在編寫XML文件時,我們應該嚴格遵守XML的語法規則,一般XML語法有如下規則:(1)起始和結束的標簽相匹配;(2)嵌套標簽不能相互嵌套;(3)區分大小寫。下面是給出了一個編寫錯誤的XML文件以及對其的錯誤說明,如下:
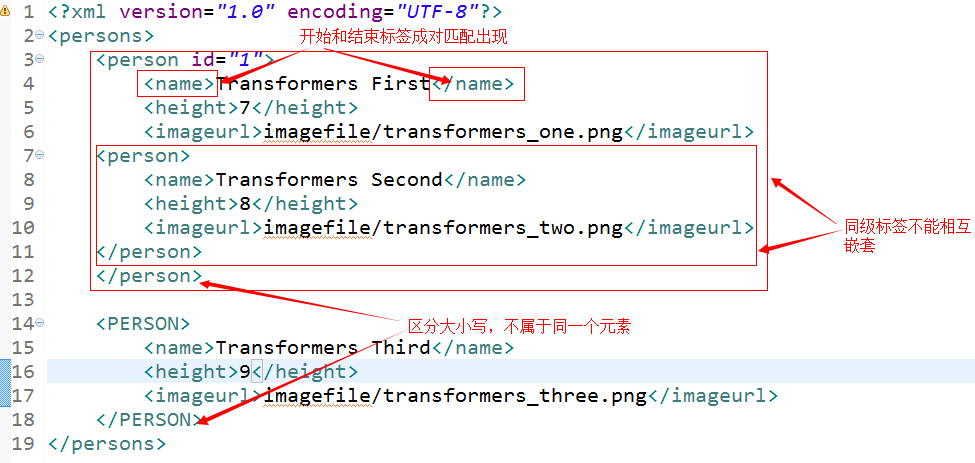
本文只是對XML做了個簡單的介紹,要想學習更多有關XML知識,可以訪問如下網站:http://bbs.xml.org.cn/index.asp。
XML在實際應用中比較廣泛,Android也不例外,作為承載數據的重要角色,如何讀寫XML稱為Android開發中一項重要的技能。
在Android開發中,較為常用的XML解析器有SAX解析器、DOM解析器和PULL解析器,下面我們將會一一學習如何使用這些XML解析器。那在介紹這幾種XML解析器過程中,我們依然是要通過一個實例來學習它們的實際開發方法,下面是我們Demo實例的程序列表清單,如下:
圖1-1 客戶端 圖1-2 服務器端
來整理下我們實現的Demo實例思路:客戶端通過網絡請求讀取服務器端的person.xml,person.xml文件中的內容如下:
[html] view plain copy
TransformersFirst
7imagefile/transformers_one.png
Transformerssecond4
imagefile/transformers_two.png
Transformersthird
8.5imagefile/transformers_three.png
Transformersfourth14.5
imagefile/transformers_four.png
Transformersfifth
27.5imagefile/transformers_five.png
TransformersSixth8.5
imagefile/transformers_six.png
TransformersSeventh
5imagefile/transformers_seven.png
TransformersEighth12.5
imagefile/transformers_eight.png
接著將獲取到的person.xml的文件流信息分別使用SAX、DOM和PULL解析方式解析成Java對象,然後將解析後獲取到的Java對象信息以列表的形式展現在客戶端,思路很簡單吧。
Demo實例工程的下載地址:
好了,基本了解了Demo實例的整體思路後,接下來我們將學習如何具體實現它們。
SAX(Simple For XML)是一種基於事件的解析器,它的核心是事件處理模式,它主要是圍繞事件源和事件處理器來工作的。當事件源產生事件後,會調用事件處理器中相應的方法來處理一個事件,那在事件源調用對應的方法時也會向對應的事件傳遞一些狀態信息,以便我們根據其狀態信息來決定自己的行為。
接下來我們將具體地學習一下SAX解析工作的主要原理:在讀取XML文檔內容時,事件源順序地對文檔進行掃描,當掃描到文檔的開始與結束(Document)標簽、節點元素的開始與結束(Element)標簽時,直接調用對應的方法,並將狀態信息以參數的形式傳遞到方法中,然後我們可以依據狀態信息來執行相關的自定義操作。為了更好的理解SAX解析的工作原理,我們結合具體的代碼來更深入的理解下,代碼如下:
[java] view plain copy
/***SAX解析類
*@authorAndroidLeaf*/
publicclassMyHandlerextendsDefaultHandler{
//當開始讀取文檔標簽時調用該方法@Override
publicvoidstartDocument()throwsSAXException{//TODOAuto-generatedmethodstub
super.startDocument();}
//當開始讀取節點元素標簽時調用該方法
@OverridepublicvoidstartElement(Stringuri,StringlocalName,StringqName,
Attributesattributes)throwsSAXException{//TODOAuto-generatedmethodstub
super.startElement(uri,localName,qName,attributes);//dosomething
}
//當讀取節點元素的子類信息時調用該方法@Override
publicvoidcharacters(char[]ch,intstart,intlength)throwsSAXException{
//TODOAuto-generatedmethodstubsuper.characters(ch,start,length);
//dosomething}
//當結束讀取節點元素標簽時調用該方法
@OverridepublicvoidendElement(Stringuri,StringlocalName,StringqName)
throwsSAXException{//TODOAuto-generatedmethodstub
super.endElement(uri,localName,qName);//dosomething
}
//當結束讀取文檔標簽時調用該方法@Override
publicvoidendDocument()throwsSAXException{//TODOAuto-generatedmethodstub
super.endDocument();//dosomething
}
}
首先我們先認識一個重要的類--DefaultHandler,該類是XML解析接口(EntityResolver, DTDHandler, ContentHandler, ErrorHandler)的缺省實現,在通常情況下,為應用程序擴展DefaultHandler並覆蓋相關的方法要比直接實現這些接口更容易。接著重寫startDocument(),startElement(),characters(),endElement和endDocument()五個方法,這些方法會在事件源(在org.xml.sax包中的XMLReader,通過parser()產生事件)讀取到不同的XML標簽所產生事件時調用。那我們開發時只要在這些方法中實現我們的自定義操作即可。下面總結羅列了一些使用SAX解析時常用的接口、類和方法:
事件處理器名稱事件處理器處理的事件
ContentHandlerXML文檔的開始與結束;
XML文檔節點元素的開始與結束,接收字符數據,跳過實體,接收元素內容中可忽略的空白等。
DTDHandler處理DTD解析時產生的相應事件
ErrorHandler處理XML文檔時產生的錯誤
EntityResolver處理外部實體
方法名稱方法說明
startDocument()用於處理文檔解析開始時間
startElement(String uri,String localName,String qName
Attributes attributes)處理元素開始時間,從參數中可以獲取元素所在空間的URL,元素名稱,屬性列表等信息。
characters(char[] ch,int start,int length)處理元素的字符內容,從參數中可以獲得內容
endElement(String uri,String localName,String qName)處理元素結束時間,從參數中可以獲取元素所在空間的URL,元素名稱等信息。
endDocument()用於處理文檔解析的結束事件
基本了解完SAX解析工作原理及開發時用到的常用接口和類後,接下來我們來學習一下使用SAX解析XML的編程步驟,一般分為5個步驟,如下:
1、獲取創建一個SAX解析工廠實例;
2、調用工廠實例中的newSAXParser()方法創建SAXParser解析對象;
3、實例化CustomHandler(DefaultHandler的子類);
4、連接事件源對象XMLReader到事件處理類DefaultHandler中;
5、通過DefaultHandler返回我們需要的數據集合。
接著,我們按照這5個步驟來完成Demo實例解析person.xml的工作(person.xml的內容上面已經列出),解析的關鍵代碼是在Demo實例工程中的XmlTools類中,具體代碼如下:
[java] view plain copy
/**--------------SAX解析XML-------------------*//**
*@parammInputStream需要解析的person.xml的文件流對象*@paramnodeName節點名稱
*@returnmListPerson對象集合*/
publicstaticArrayListsaxAnalysis(InputStreammInputStream,StringnodeName){//1、獲取創建一個SAX解析工廠實例
SAXParserFactorymSaxParserFactory=SAXParserFactory.newInstance();try{
//2、調用工廠實例中的newSAXParser()方法創建SAXParser解析對象SAXParsermSaxParser=mSaxParserFactory.newSAXParser();
//3、實例化CustomHandler(DefaultHandler的子類)CustomHandlermHandler=newCustomHandler(nodeName);
/***4、連接事件源對象XMLReader到事件處理類DefaultHandler中
*查看parse(InputStreamis,DefaultHandlerdh)方法源碼如下:*publicvoidparse(InputSourceis,DefaultHandlerdh)
*throwsSAXException,IOException{*if(is==null){
*thrownewIllegalArgumentException("InputSourcecannotbenull");*}
*//獲取事件源XMLReader,並通過相應事件處理器注冊方法setXXXX()來完成的與ContentHander、DTDHander、ErrorHandler,*//以及EntityResolver這4個接口的連接。
*XMLReaderreader=this.getXMLReader();*if(dh!=null){
*reader.setContentHandler(dh);*reader.setEntityResolver(dh);
*reader.setErrorHandler(dh);*reader.setDTDHandler(dh);
*}*reader.parse(is);
*}*/
mSaxParser.parse(mInputStream,mHandler);//5、通過DefaultHandler返回我們需要的數據集合
returnmHandler.getList();}catch(ParserConfigurationExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}catch(SAXExceptione){//TODOAuto-generatedcatchblock
e.printStackTrace();}catch(IOExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}returnnull;
} 事件處理器類CustomerHandler中的具體代碼如下:
[java] view plain copy
/***SAX解析類
*@authorAndroidLeaf*/
publicclassCustomHandlerextendsDefaultHandler{
//裝載所有解析完成的內容List>mListMaps=null;
//裝載解析單個person節點的內容HashMapmap=null;
//節點名稱privateStringnodeName;
//當前解析的節點標記privateStringcurrentTag;
//當前解析的節點值privateStringcurrentValue;
publicArrayListgetList(){
ArrayListmList=newArrayList();if(mListMaps!=null&&mListMaps.size()>0){
for(inti=0;iHashMapmHashMap=mListMaps.get(i);mPerson.setId(Integer.parseInt(mHashMap.get("id")));
mPerson.setUserName(mHashMap.get("name"));mPerson.setHeight(Float.parseFloat(mHashMap.get("height")));
mPerson.setImageUrl(mHashMap.get("imageurl"));mList.add(mPerson);
}}
returnmList;}
publicCustomHandler(StringnodeName){
this.nodeName=nodeName;}
@OverridepublicvoidstartDocument()throwsSAXException{
//TODOAuto-generatedmethodstubsuper.startDocument();
mListMaps=newArrayList>();}
@Override
publicvoidstartElement(Stringuri,StringlocalName,StringqName,Attributesattributes)throwsSAXException{
//TODOAuto-generatedmethodstubif(qName.equals(nodeName)){
map=newHashMap();}
if(map!=null&&attributes!=null){for(inti=0;imap.put(attributes.getQName(i),attributes.getValue(i));}
}//當前的解析的節點名稱
currentTag=qName;}
@Override
publicvoidcharacters(char[]ch,intstart,intlength)throwsSAXException{
//TODOAuto-generatedmethodstubif(map!=null&¤tTag!=null){
currentValue=newString(ch,start,length);if(currentValue!=null&&!currentValue.equals("")
&&!currentValue.equals("\n")){map.put(currentTag,currentValue);
}}
currentTag=null;currentValue=null;
super.characters(ch,start,length);}
@Override
publicvoidendElement(Stringuri,StringlocalName,StringqName)throwsSAXException{
//TODOAuto-generatedmethodstubif(qName.equals(nodeName)){
mListMaps.add(map);map=null;
}super.endElement(uri,localName,qName);
}
@OverridepublicvoidendDocument()throwsSAXException{
//TODOAuto-generatedmethodstubsuper.endDocument();
}
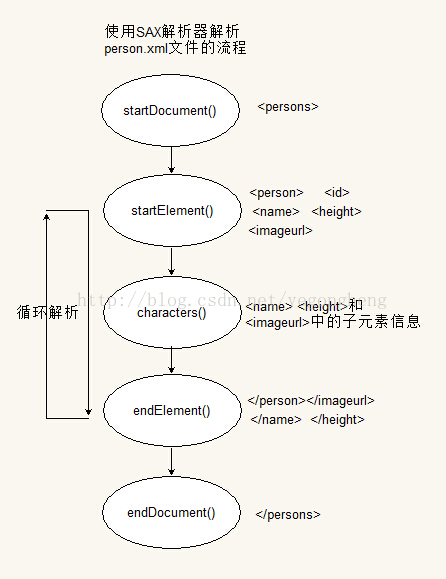
} CustomerHandler通過不斷接收事件源傳遞過來的事件,進而執行相關解析工作並調用對應的方法,然後以參數的形式接收解析結果。為了更好的讓讀者理解CustomerHandler的解析過程,下面有一張展示解析person.xml文件的流程圖,如下:
DOM是基於樹形結構的的節點或信息片段的集合,允許開發人員使用DOM API遍歷XML樹、檢索所需數據。分析該結構通常需要加載整個文檔和構造樹形結構,然後才可以檢索和更新節點信息。Android完全支持DOM 解析。利用DOM中的對象,可以對XML文檔進行讀取、搜索、修改、添加和刪除等操作。
DOM的工作原理:使用DOM對XML文件進行操作時,首先要解析文件,將文件分為獨立的元素、屬性和注釋等,然後以節點樹的形式在內存中對XML文件進行表示,就可以通過節點樹訪問文檔的內容,並根據需要修改文檔——這就是DOM的工作原理。DOM實現時首先為XML文檔的解析定義一組接口,解析器讀入整個文檔,然後構造一個駐留內存的樹結構,這樣代碼就可以使用DOM接口來操作整個樹結構。由於DOM在內存中以樹形結構存放,因此檢索和更新效率會更高。但是對於特別大的文檔,解析和加載整個文檔將會很耗資源。 當然,如果XML文件的內容比較小,采用DOM是可行的。下面羅列了一些使用DOM解析時常用的接口和類,如下:
接口或類名稱接口或類說明
Document該接口定義分析並創建DOM文檔的一系列方法,它是文檔樹的根,是操作DOM的基礎。
Element該接口繼承Node接口,提供了獲取、修改XML元素名字和屬性的方法
Node該接口提供處理並獲取節點和子節點值的方法
NodeList提供獲得子節點個數和當前節點的方法。這樣就可以迭代地訪問各個節點
DOMParser該類是Apache的Xerces中的DOM解析器類,可直接解析XML。
接下來我們學習一下使用DOM解析XML的編程步驟,一般分為6個步驟,如下:
1、創建文檔對象工廠實例;
2、調用DocumentBuilderFactory中的newDocumentBuilder()方法創建文檔對象構造器;
3、將文件流解析成XML文檔對象;
4、使用mDocument文檔對象得到文檔根節點;
5、根據名稱獲取根節點中的子節點列表;
6 、獲取子節點列表中需要讀取的節點信息。
然後,我們按照這6個步驟來完成Demo實例解析person.xml的工作(person.xml的內容上面已經列出),解析的關鍵代碼是在Demo實例工程中的XmlTools類中,具體代碼如下:
[java] view plain copy
/**--------------DOM解析XML-------------------*//**
*@parammInputStream需要解析的person.xml的文件流對象*@returnmListPerson對象集合
*/publicstaticArrayListdomAnalysis(InputStreammInputStream){
ArrayListmList=newArrayList();
//1、創建文檔對象工廠實例DocumentBuilderFactorymDocumentBuilderFactory=DocumentBuilderFactory.newInstance();
try{//2、調用DocumentBuilderFactory中的newDocumentBuilder()方法創建文檔對象構造器
DocumentBuildermDocumentBuilder=mDocumentBuilderFactory.newDocumentBuilder();//3、將文件流解析成XML文檔對象
DocumentmDocument=mDocumentBuilder.parse(mInputStream);//4、使用mDocument文檔對象得到文檔根節點
ElementmElement=mDocument.getDocumentElement();//5、根據名稱獲取根節點中的子節點列表
NodeListmNodeList=mElement.getElementsByTagName("person");//6、獲取子節點列表中需要讀取的節點信息
for(inti=0;iElementpersonElement=(Element)mNodeList.item(i);//獲取person節點中的屬性
if(personElement.hasAttributes()){mPerson.setId(Integer.parseInt(personElement.getAttribute("id")));
}if(personElement.hasChildNodes()){
//獲取person節點的子節點列表NodeListmNodeList2=personElement.getChildNodes();
//遍歷子節點列表並賦值for(intj=0;jNodemNodeChild=mNodeList2.item(j);if(mNodeChild.getNodeType()==Node.ELEMENT_NODE){
if("name".equals(mNodeChild.getNodeName())){mPerson.setUserName(mNodeChild.getFirstChild().getNodeValue());
}elseif("height".equals(mNodeChild.getNodeName())){mPerson.setHeight(Float.parseFloat(mNodeChild.getFirstChild().getNodeValue()));
}elseif("imageurl".equals(mNodeChild.getNodeName())){mPerson.setImageUrl(mNodeChild.getFirstChild().getNodeValue());
}}
}}
mList.add(mPerson);}
}catch(ParserConfigurationExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}catch(SAXExceptione){//TODOAuto-generatedcatchblock
e.printStackTrace();}catch(IOExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}returnmList;
}
PULL的解析方式與SAX解析類似,都是基於事件的模式。不同的是,在PULL解析過程中返回的是數字,且我們需要自己獲取產生的事件然後做相應的操作,而不像SAX那樣由處理器觸發一種事件的方法,執行我們的代碼。PULL 的工作原理:XML pull提供了開始元素和結束元素。當某個元素開始時,我們可以調用parser.nextText從XML文檔中提取所有字符數據。當解釋到一個文檔結束時,自動生成EndDocument事件。下面羅列了一些使用PULL解析時常用的接口、類和方法:
接口和類名稱接口和類說明
XmlPullParserXML Pull解析接口,該接口定義了解析功能
XmlSerializer它是一個接口,定義了XML信息集的序列
XmlPullParserFactoryXML PULL解析工廠類,用於創建XML Pull解析器
XmlPullParserException拋出單一的XML pull解析器相關的錯誤
方法名方法說明
getEventType()該方法用於獲取當前解析到的事件類型
nextText()提取當前節點元素的字符數據
next()獲取下一個節點元素的類型
getName()獲取當前節點元素的名稱
getAttributeCount()獲取當前節點屬性的數量
XmlPullParser.START_DOCUMENT文檔開始解析類型
XmlPullParser.END_DOCUMENT文檔結束解析類型
XmlPullParser.START_TAG節點開始解析類型
XmlPullParser.END_TAG節點結束解析類型
XmlPullParser.TEXT文本解析類型
接下來我們將學習使用PULL解析XML的編程步驟,一般分為5個步驟,如下:
1、獲取PULL解析工廠實例對象;
2、使用XmlPullParserFactory的newPullParser()方法實例化PULL解析實例對象;
3、設置需解析的XML文件流和字符編碼;
4、獲取事件解析類型;
5、循環遍歷解析,當文檔解析結束時結束循環;
然後,我們按照這5個步驟來完成Demo實例解析person.xml的工作(person.xml的內容上面已經列出),解析的關鍵代碼是在Demo實例工程中的XmlTools類中,具體代碼如下:
[java] view plain copy
/**--------------PULL解析XML-------------------*//**
*@parammInputStream需要解析的person.xml的文件流對象*@paramencode設置字符編碼
*@returnmListPerson對象集合*/
publicstaticArrayListPullAnalysis(InputStreammInputStream,Stringencode){ArrayListmList=null;
PersonmPerson=null;try{
//1、獲取PULL解析工廠實例對象XmlPullParserFactorymXmlPullParserFactory=XmlPullParserFactory.newInstance();
//2、使用XmlPullParserFactory的newPullParser()方法實例化PULL解析實例對象XmlPullParsermXmlPullParser=mXmlPullParserFactory.newPullParser();
//3、設置需解析的XML文件流和字符編碼mXmlPullParser.setInput(mInputStream,encode);
//4、獲取事件解析類型inteventType=mXmlPullParser.getEventType();
//5、循環遍歷解析,當文檔解析結束時結束循環while(eventType!=XmlPullParser.END_DOCUMENT){
switch(eventType){//開始解析文檔
caseXmlPullParser.START_DOCUMENT:mList=newArrayList();
break;//開始解析節點
caseXmlPullParser.START_TAG:if("person".equals(mXmlPullParser.getName())){
mPerson=newPerson();//獲取該節點中的屬性的數量
intattributeNumber=mXmlPullParser.getAttributeCount();if(attributeNumber>0){
//獲取屬性值mPerson.setId(Integer.parseInt(mXmlPullParser.getAttributeValue(0)));
}}elseif("name".equals(mXmlPullParser.getName())){
//獲取該節點的內容mPerson.setUserName(mXmlPullParser.nextText());
}elseif("height".equals(mXmlPullParser.getName())){mPerson.setHeight(Float.parseFloat(mXmlPullParser.nextText()));
}elseif("imageurl".equals(mXmlPullParser.getName())){mPerson.setImageUrl(mXmlPullParser.nextText());
}break;
//解析節點結束caseXmlPullParser.END_TAG:
if("person".equals(mXmlPullParser.getName())){mList.add(mPerson);
mPerson=null;}
break;default:
break;}
eventType=mXmlPullParser.next();}
}catch(XmlPullParserExceptione){//TODOAuto-generatedcatchblock
e.printStackTrace();}catch(IOExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}returnmList;
}
現在我麼已經分別使用SAX、DOM和PULL解析器解析person.xml的文件流後,結果返回Person對象的集合,我們的解析工作便完成了,接下來需要做的就是將解析結果以列表的方式展現在客戶端界面上。那首先我們先來實現一下從網絡服務端獲取數據的網絡訪問代碼,在工程中主要包含HttpRequest和MyAsynctask兩個類,前者主要功能是執行網絡請求,後者是進行異步請求的幫助類。首先看HttpRequest類的代碼,如下:
[java] view plain copy
/***網絡訪問類
*@authorAndroidLeaf*/
publicclassHttpRequest{/**
*@paramurlStr請求的Url*@returnInputStream返回請求的流數據
*/publicstaticInputStreamgetInputStreamFromNetWork(StringurlStr)
{URLmUrl=null;
HttpURLConnectionmConnection=null;InputStreammInputStream=null;
try{mUrl=newURL(urlStr);
mConnection=(HttpURLConnection)mUrl.openConnection();mConnection.setDoOutput(true);
mConnection.setDoInput(true);mConnection.setReadTimeout(15*1000);
mConnection.setConnectTimeout(15*1000);mConnection.setRequestMethod("GET");
intresponseCode=mConnection.getResponseCode();if(responseCode==HttpURLConnection.HTTP_OK){
//獲取下載資源的大小//contentLength=mConnection.getContentLength();
mInputStream=mConnection.getInputStream();returnmInputStream;
}}catch(IOExceptione){
//TODO:handleexception}
returnnull;}
/**
*得到圖片字節流數組大小**/
publicstaticbyte[]readStream(InputStreammInputStream){ByteArrayOutputStreamoutStream=newByteArrayOutputStream();
byte[]buffer=newbyte[2048];intlen=0;
try{while((len=mInputStream.read(buffer))!=-1){
outStream.write(buffer,0,len);}
}catch(IOExceptione){//TODOAuto-generatedcatchblock
e.printStackTrace();}finally{
try{if(outStream!=null){
outStream.close();}
if(mInputStream!=null){mInputStream.close();
}}catch(IOExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}}
returnoutStream.toByteArray();} 接著實現MyAsynctask類的代碼,如下:
[java] view plain copy
/***異步請求工具類
*@authorAndroidLeaf*/
publicclassMyAsynctaskextendsAsyncTask{
privateImageViewmImageView;privateImageCallBackmImageCallBack;
//請求類型,分為XML文件請求和圖片下載請求privateinttypeId;
//使用的XML解析類型IDprivateintrequestId;
/**
*定義一個回調,用於監聽網絡請求,當請求結束,返回訪問結果*/
publicHttpDownloadedListenermHttpDownloadedListener;
publicinterfaceHttpDownloadedListener{publicvoidonDownloaded(Stringresult,intrequestId);
}
publicvoidsetOnHttpDownloadedListener(HttpDownloadedListenermHttpDownloadedListener){this.mHttpDownloadedListener=mHttpDownloadedListener;
}
publicMyAsynctask(ImageViewmImageView,ImageCallBackmImageCallBack,intrequestId){this.mImageView=mImageView;
this.mImageCallBack=mImageCallBack;this.requestId=requestId;
}
@OverrideprotectedvoidonPreExecute(){
//TODOAuto-generatedmethodstubsuper.onPreExecute();
}
@OverrideprotectedObjectdoInBackground(Object...params){
//TODOAuto-generatedmethodstubInputStreammInputStream=HttpRequest.getInputStreamFromNetWork((String)params[0]);
if(mInputStream!=null){switch((int)params[1]){
caseConstants.TYPE_STR:typeId=Constants.TYPE_STR;
returnWriteIntoFile(mInputStream);caseConstants.TYPE_STREAM:
typeId=Constants.TYPE_STREAM;returngetBitmap(HttpRequest.readStream(mInputStream),
200,200);default:
break;}
}returnnull;
}
@OverrideprotectedvoidonPostExecute(Objectresult){
//TODOAuto-generatedmethodstubif(result!=null){
switch(typeId){caseConstants.TYPE_STR:
mHttpDownloadedListener.onDownloaded((String)result,requestId);break;
caseConstants.TYPE_STREAM:mImageCallBack.resultImage(mImageView,(Bitmap)result);
break;default:
break;}
typeId=-1;}
super.onPostExecute(result);}
publicBitmapgetBitmap(byte[]bytes,intwidth,intheight){
//獲取屏幕的寬和高/**
*為了計算縮放的比例,我們需要獲取整個圖片的尺寸,而不是圖片*BitmapFactory.Options類中有一個布爾型變量inJustDecodeBounds,將其設置為true
*這樣,我們獲取到的就是圖片的尺寸,而不用加載圖片了。*當我們設置這個值的時候,我們接著就可以從BitmapFactory.Options的outWidth和outHeight中獲取到值
*/BitmapFactory.Optionsop=newBitmapFactory.Options();
op.inJustDecodeBounds=true;Bitmappic=BitmapFactory.decodeByteArray(bytes,0,bytes.length);
intwRatio=(int)Math.ceil(op.outWidth/(float)width);//計算寬度比例
inthRatio=(int)Math.ceil(op.outHeight/(float)height);//計算高度比例
/***接下來,我們就需要判斷是否需要縮放以及到底對寬還是高進行縮放。
*如果高和寬不是全都超出了屏幕,那麼無需縮放。*如果高和寬都超出了屏幕大小,則如何選擇縮放呢》
*這需要判斷wRatio和hRatio的大小*大的一個將被縮放,因為縮放大的時,小的應該自動進行同比率縮放。
*縮放使用的還是inSampleSize變量*/
if(wRatio>1&&hRatio>1){if(wRatio>hRatio){
op.inSampleSize=wRatio;}else{
op.inSampleSize=hRatio;}
}op.inJustDecodeBounds=false;//注意這裡,一定要設置為false,因為上面我們將其設置為true來獲取圖片尺寸了
pic=BitmapFactory.decodeByteArray(bytes,0,bytes.length);returnpic;
}
/***將下載的XML文件流存儲到手機指定的SDcard目錄下
*@parammInputStream需要讀入的流*@returnString返回存儲的XML文件的路徑
*/publicStringWriteIntoFile(InputStreammInputStream){
if(isSDcard()){try{
FileOutputStreammOutputStream=newFileOutputStream(newFile(getFileName()));intlen=-1;
byte[]bytes=newbyte[2048];try{
while((len=mInputStream.read(bytes))!=-1){mOutputStream.write(bytes,0,len);
}}catch(IOExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}finally{try{
if(mOutputStream!=null){mOutputStream.close();
}if(mInputStream!=null){
mInputStream.close();}
}catch(IOExceptione){//TODOAuto-generatedcatchblock
e.printStackTrace();}
}}catch(FileNotFoundExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}returngetFileName();
}returnnull;
}
/***檢測SDcard是否可用
*@return*/
publicbooleanisSDcard(){if(Environment.getExternalStorageState().equals(Environment.MEDIA_MOUNTED)){
returntrue;}else{
returnfalse;}
}
/***獲取需要存儲的XML文件的路徑
*@returnString路徑*/
publicStringgetFileName(){Stringpath=Environment.getExternalStorageDirectory().getPath()+"/XMLFiles";
FilemFile=newFile(path);if(!mFile.exists()){
mFile.mkdirs();}
returnmFile.getPath()+"/xmlfile.xml";} 實現完網絡請求的功能後,我們就可以從服務端獲取到person.xml的文件流,然後再分別用SAX、DOM和PULL解析器將文件流解析(在上面介紹這幾種解析器時已經實現了解析的代碼,在工程中的XmlTools類中)成對應的Java對象集合,最後將Java對象集合以列表的形式展現在客戶端界面上,那接下來我們將實現該功能。在工程中主要包含MainActivity、MyAdapter和ImageCallBack類,首先實現MainActivity的代碼,如下:
[java]view plaincopy
publicclassMainActivityextendsListActivityimplementsHttpDownloadedListener{
privateProgressDialogmProgressDialog;//需要解析的節點名稱
privateStringnodeName="person";
@OverrideprotectedvoidonCreate(BundlesavedInstanceState){
super.onCreate(savedInstanceState);setContentView(R.layout.activity_list);
//初始化數據initData();
}
publicvoidinitData(){mProgressDialog=newProgressDialog(this);
mProgressDialog.setProgressStyle(ProgressDialog.STYLE_SPINNER);mProgressDialog.setTitle("正在加載中.....");
mProgressDialog.show();
//首次進入界面是,默認使用SAX解析數據downloadData(this,Constants.XML_PATH,Constants.REQUEST_PULL_TYPE,null,null,Constants.TYPE_STR);
}
@OverridepublicbooleanonCreateOptionsMenu(Menumenu){
//TOdOAuto-generatedmethodstubgetMenuInflater().inflate(R.menu.main,menu);
returntrue;}
@Override
publicbooleanonOptionsItemSelected(MenuItemitem){//TOdOAuto-generatedmethodstub
intrequestId=-1;switch(item.getItemId()){
caseR.id.sax:requestId=Constants.REQUEST_SAX_TYPE;
break;caseR.id.dom:
requestId=Constants.REQUEST_DOM_TYPE;break;
caseR.id.pull:requestId=Constants.REQUEST_PULL_TYPE;
break;default:
break;}
downloadData(this,Constants.XML_PATH,requestId,null,null,Constants.TYPE_STR);mProgressDialog.show();
returnsuper.onOptionsItemSelected(item);}
@Override
publicvoidonDownloaded(Stringresult,intrequestId){//TODOAuto-generatedmethodstub
FileInputStreammFileInputStream=null;try{
mFileInputStream=newFileInputStream(newFile(result));}catch(FileNotFoundExceptione){
//TODOAuto-generatedcatchblocke.printStackTrace();
}ArrayListmList=null;
switch(requestId){caseConstants.REQUEST_SAX_TYPE:
mList=XmlTools.saxAnalysis(mFileInputStream,nodeName);break;
caseConstants.REQUEST_DOM_TYPE:mList=XmlTools.domAnalysis(mFileInputStream);
break;caseConstants.REQUEST_PULL_TYPE:
mList=XmlTools.PullAnalysis(mFileInputStream,"UTF-8");break;
default:break;
}
MyAdaptermyAdapter=newMyAdapter(this,mList);setListAdapter(myAdapter);
if(mProgressDialog.isShowing()){
mProgressDialog.dismiss();}
}
//執行網絡下載代碼publicstaticvoiddownloadData(HttpDownloadedListenermDownloadedListener,Stringurl,intrequestId,ImageViewmImageView,ImageCallBackmImageCallBack,inttypeId){
MyAsynctaskmAsynctask=newMyAsynctask(mImageView,mImageCallBack,requestId);mAsynctask.setOnHttpDownloadedListener(mDownloadedListener);
mAsynctask.execute(url,typeId);}
} 然後再實現界面的適配器類--MyAdapter,具體代碼如下:
[java]view plaincopy
/***數據界面展示的適配器類
*@authorAndroidLeaf*/
publicclassMyAdapterextendsBaseAdapter{
privateContextmContext;privateArrayListmList;
privateBitmap[]mBitmaps;
publicMyAdapter(ContextmContext,ArrayListmList){this.mContext=mContext;
this.mList=mList;mBitmaps=newBitmap[mList.size()];
}@Override
publicintgetCount(){//TODOAuto-generatedmethodstub
returnmList.size();}
@Override
publicObjectgetItem(intposition){//TODOAuto-generatedmethodstub
returnmList.get(position);}
@Override
publiclonggetItemId(intposition){//TODOAuto-generatedmethodstub
returnposition;}
@Override
publicViewgetView(intposition,ViewconvertView,ViewGroupparent){//TODOAuto-generatedmethodstub
ViewHoldermHolder;PersonmPerson=mList.get(position);
if(convertView==null){convertView=LayoutInflater.from(mContext).inflate(R.layout.item_list,null);
mHolder=newViewHolder();mHolder.mTextView_id=(TextView)convertView.findViewById(R.id.item_id);
mHolder.mTextView_name=(TextView)convertView.findViewById(R.id.item_name);mHolder.mTextView_height=(TextView)convertView.findViewById(R.id.item_height);
mHolder.mImageView_image=(ImageView)convertView.findViewById(R.id.item_image);//為Imageview設置TAG,作為每一個ImageView的唯一標識
mHolder.mImageView_image.setTag(mPerson.getImageUrl());convertView.setTag(mHolder);
}else{mHolder=(ViewHolder)convertView.getTag();
}mHolder.mTextView_id.setText(String.valueOf(mPerson.getId()));
mHolder.mTextView_name.setText(mPerson.getUserName());mHolder.mTextView_height.setText(String.valueOf(mPerson.getHeight()));
/***解決異步加載過程中Listview列表中圖片顯示錯位問題
*///判斷當前位置的ImageView和是否為上次執行加載操作的ImageView,若false則重置上次加載的那個Imageview中的圖片資源
if(!mPerson.getImageUrl().equals(String.valueOf(mHolder.mImageView_image.getTag()))){mHolder.mImageView_image.setImageResource(R.drawable.ic_launcher);
}//重新為ImageView實例設置TAG
mHolder.mImageView_image.setTag(mPerson.getImageUrl());if(mBitmaps[position]==null){
//執行異步加載圖片操作MainActivity.downloadData((HttpDownloadedListener)mContext,Constants.BASE_PATH+mPerson.getImageUrl(),-1,
mHolder.mImageView_image,newMyImageCallBack(position,mPerson.getImageUrl()),Constants.TYPE_STREAM);}else{
mHolder.mImageView_image.setImageBitmap(mBitmaps[position]);}
returnconvertView;
}
classViewHolder{TextViewmTextView_id;
TextViewmTextView_name;TextViewmTextView_height;
ImageViewmImageView_image;}
classMyImageCallBackimplementsImageCallBack{
intindex=-1;StringimageUrl=null;
publicMyImageCallBack(intindex,StringimageUrl){this.index=index;
this.imageUrl=imageUrl;}
@Override
publicvoidresultImage(ImageViewmImageView,BitmapmBitmap){//TODOAuto-generatedmethodstub
//判斷當前顯示的ImageView的URL是否與需要下載的圖片ImageView的URL相同if(imageUrl.equals(String.valueOf(mImageView.getTag()))){
mBitmaps[index]=mBitmap;mImageView.setImageBitmap(mBitmap);
}}
}} 觀察上面的代碼,在實現適配器類時,由於我們需要異步下載圖片,因此在圖片綁定和顯示時由於列表項焦點的不斷變換和圖片數據加載的延遲會導致ListView中的圖片顯示錯位的問題,為了解決該問題,我們采取對ImageView設置TAG來解決了圖片錯位問題,那要明白其中的原理,就必須對Listview加載item view列表項的實現機制比較清楚,由於該問題不是本文的重點,因此在此不便細講,有興趣的讀者可以學習本博客的另一篇文章《Android異步加載數據時ListView中圖片錯位問題解析》,希望對你有所幫助。在實現圖片異步加載時,程序中還使用到了一個非常有用的接口--ImageCallBack,該接口主要作用是將異步下載的圖片設置到對應的Imageview控件中,該接口的具體代碼如下:
[java]view plaincopy
publicinterfaceImageCallBack{publicvoidresultImage(ImageViewmImageView,BitmapmBitmap);
} 當然,還有常量Constants類和Entity對象Person類。Constants類的具體的代碼:
[java]view plaincopy
/***網絡請求的Url地址及一些常量
*@authorAndroidLeaf*/
publicclassConstants{
//基路徑publicstaticfinalStringBASE_PATH="http://10.0.2.2:8080/09_Android_XMLServer_Blog/";
//person.xml網絡請求路徑publicstaticfinalStringXML_PATH=BASE_PATH+"xmlfile/person.xml";
//使用SAX解析的標簽類型
publicstaticfinalintREQUEST_SAX_TYPE=0;//使用DOM解析的標簽類型
publicstaticfinalintREQUEST_DOM_TYPE=1;//使用PULL解析的標簽類型
publicstaticfinalintREQUEST_PULL_TYPE=2;
//請求person.xml文件標簽publicstaticfinalintTYPE_STR=1;
//請求圖片文件標簽publicstaticfinalintTYPE_STREAM=2;
} Person類的代碼如下:
[java]view plaincopy
publicclassPerson{
privateintid;privateStringuserName;
privatefloatheight;privateStringimageUrl;
publicintgetId(){
returnid;}
publicvoidsetId(intid){this.id=id;
}publicStringgetUserName(){
returnuserName;}
publicvoidsetUserName(StringuserName){this.userName=userName;
}publicfloatgetHeight(){
returnheight;}
publicvoidsetHeight(floatheight){this.height=height;
}publicStringgetImageUrl(){
returnimageUrl;}
publicvoidsetImageUrl(StringimageUrl){this.imageUrl=imageUrl;
}
@OverridepublicStringtoString(){
return"Person[id="+id+",userName="+userName+",height="+height+",imageUrl="+imageUrl+"]";
}} 全部的編碼都已經完成,最後我們再Android模擬器上運行我們的Demo實例工程,運行及操作的效果圖如下:
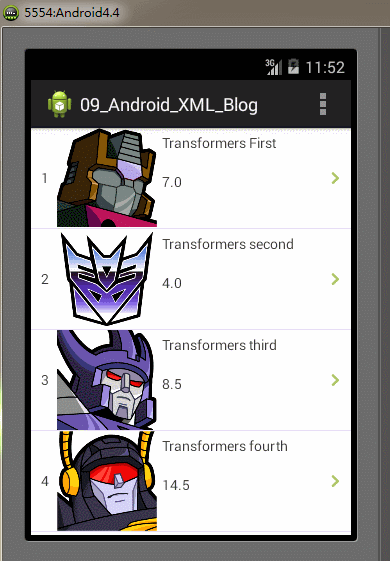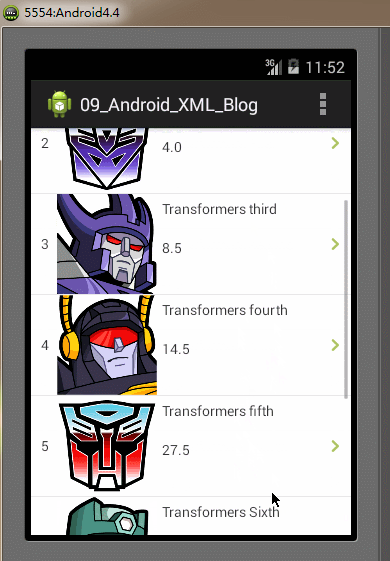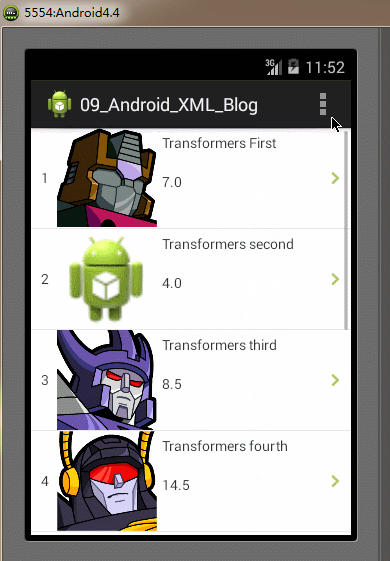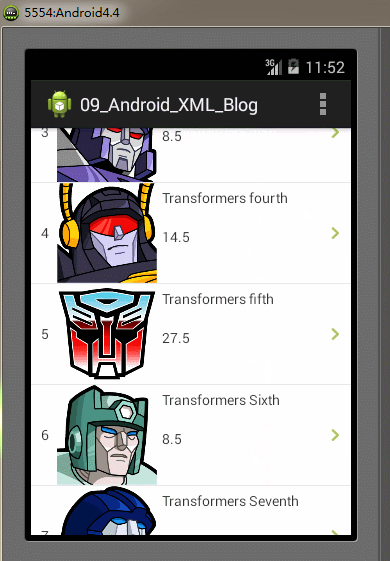
SAX解析器的特點:SAX解析器解析速度快、高效,占用內存少。但它的缺點是編碼實現比其它解析方式更復雜,對於只需解析較少數量的XML文件時,使用SAX解析顯得實現代碼比較臃腫。
DOM解析器的特點:由於DOM在內存中是以樹形結構存放的,那雖然檢索和更新效率比較高,但對於使用DOM來解析較大數據的XML文件,將會消耗很大內存資源,這對於內存資源比較有限的手機設備來講,是不太適合的。
PULL解析器的特點:PULL解析器小巧輕便,解析速度快,簡單易用,非常適合在Android移動設備中使用,Android系統內部在解析各種XML時也是用PULL解析器,Android官方推薦開發者們使用Pull解析技術。Pull解析技術是第三方開發的開源技術,它同樣可以應用於JavaSE開發。
根據上面介紹的這些解析器的特點我們可在不同的開發情況下選擇不同的解析方式,比如說,當XML文件數據較小時,可以選擇DOM解析,因為它將XML數據以樹形結構存放在內存中,在占用不多的內存資源情況下檢索和更新效率比較高,當XML文件數據較大時,可以選擇SAX和PULL解析,因為它們不需要將所有的XML文件都加載到內存中,這樣對有限的Android內存更有效。SAX和PULL解析的不同之處是,PULL解析並不像SAX解析那樣監聽元素的結束,而是在開始處完成了大部分處理。這有利於提早讀取XML文件,可以極大的減少解析時間,這種優化對於連接速度較漫的移動設備而言尤為重要。對於XML文檔數據較大但只需要文檔的一部分時,XML PULL解析器則是更為有效的方法。
總結:本文學習了在Android開發中解析XML文件的幾種常用解析方式,這幾種解析方式各有優缺點,我們應根據不同的開發需求選擇合適的解析方式。最後總結一下在Android解析XML所需掌握的主要知識點:(1)XML的特點以及結構組成形式,掌握如何編寫XML文件;(2)了解SAX、PULL和DOM解析器的特點,並掌握在Android中使用這三種解析方式的使用;(3)比較三種解析器的特點,學會在不同情況下選擇合適的解析方式。
 11 OptionsMenu 菜單
11 OptionsMenu 菜單
OptionsMenu 選項菜單(系統菜單 )OptionsMenu:系統級別菜單菜單的使用步驟:1. res裡的menu裡添加布局 在布局裡寫菜單項2. 在邏輯代碼中使
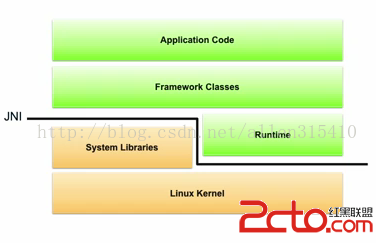 Android NDK開發(一)——環境搭建
Android NDK開發(一)——環境搭建
Android下的NDK開發是Android開發中不可或缺的一部分,通過Google提供的NDK套件,我們可以使用JNI這座橋梁在Java和C/C++之間建
 Android客戶端實現注冊、登錄詳解(1)
Android客戶端實現注冊、登錄詳解(1)
我們在開發安卓App時難免要與服務器打交道,尤其是對於用戶賬號信息的注冊與登錄更是每個Android開發人員必須掌握的技能,本文將對客戶端的注冊/登錄功能的實現進行分析,
 Android Studio多渠道打包
Android Studio多渠道打包
我們開發一個APP在上傳應用市場之前,有時候會遇到要根據不同平台打多個apk包的問題。由於Android的應用市場比較多,主流的應用市場就有應用寶,百度手機助手,豌豆莢等