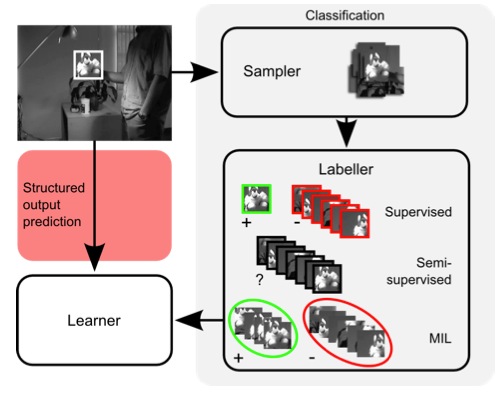
《Struck:Structured Output Tracking with Kernels》是Sam Hare, Amir Saffari, Philip H. S. Torr等人於2011年發表在Computer Vision (ICCV)上的一篇文章。Struck與傳統跟蹤算法的不同之處在於:傳統跟蹤算法(下圖右手邊)將跟蹤問題轉化為一個分類問題,並通過在線學習技術更新目標模型。然而,為了達到更新的目的,通常需要將一些預估計的目標位置作為已知類別的訓練樣本,這些分類樣本並不一定與實際目標一致,因此難以實現最佳的分類效果。而Struck算法(下圖左手邊)主要提出一種基於結構輸出預測的自適應視覺目標跟蹤的框架,通過明確引入輸出空間滿足跟蹤功能,能夠避免中間分類環節,直接輸出跟蹤結果。同時,為了保證實時性,該算法還引入了阈值機制,防止跟蹤過程中支持向量的過增長。
最後,大牛作者們也提供了c++版源代碼,有興趣的朋友可以下載下來,體驗下該算法的強大。代碼下載地址:https://github.com/gnebehay/STRUCK,代碼調試需要Opencv2.1以上版本以及Eigen v2.0.15。
實際上,作者提出的主要觀點在於構建特征與類別的SVM,說穿了還是SVM的多標簽回歸,只是計算過程做了優化而已,利用SMO迭代出alpha,在此過程中,隨機選取支持向量,不斷優化正負類別樣本,不斷更新alpha,同時,始終把支持向量數目控制在一定阈值內。
另外一點,就是多類標簽中,約束條件的計算優化。不斷確保F(目標)》F(非目標)
目前在目標檢測任務中,由於svm自身具有較好的推廣能力以及對分類的魯棒性,得到了越來越多的應用。 Struck算法便使用了在線結構輸出svm學習方法去解決跟蹤問題。不同於常規算法訓練一個分類器,Struck算法直接通過預測函數:
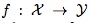
,來預測每幀之間目標位置發生的變化,其中
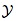
表示搜尋空間,例如,
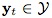
,上一幀中目標的新位置為Pt-1,則在當前幀中,目標位置就為
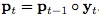
(可見
其實就是表示幀間目標位置變化關系的集合)。因此,在Struck算法中,已知類型的樣本用(x,y)表示,而不再是(x,+1)或者(x,-1)了。
那麼y預測函數
怎麼獲得呢?這就需要用到結構輸出svm方法了(svm基本概念學習可參考我上篇文章中給出的svm三重境界的鏈接),它在該算法中引入了一個判別函數
![\]()
![\]()
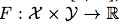
,通過公式
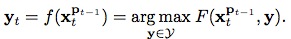
找到概率最大的
對目標位置進行預測,也就是說,因為我們還不知道當前幀的目標位置,那麼我們首先想到在上一幀中的目標能夠通過一些位置變化關系,出現在當前幀中的各處,但是呢,實際的目標只有一個,所以這些變換關系中也必然只有一個是最佳的,因此,我們需要找到這個最佳的,並通過
,就可以成功找到目標啦~,至於搜尋空間
如何取,在程序解讀時大家就會看到了。
那麼如何找到
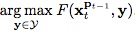
呢?我個人理解是:將判別函數形式轉換為:
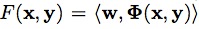
,其中,
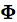
表示映射函數,是從輸入空間到某個特征空間的映射,進而實現對樣本線性可分。因為當分類平面(輸入空間中的超平面)離數據點的“間隔”越大,分類的確信度越大,所以需讓所選擇的分類平面最大化這個“間隔”值,這裡我們通過最小化凸目標函數
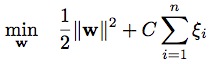
來實現,該函數應滿足條件:
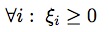
和
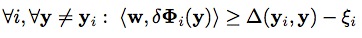
,其中,
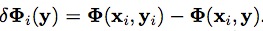
,
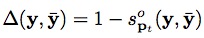
(
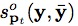
表示兩個框之間的覆蓋率)。優化的目的是確保F(目標)>>F(非目標)。
接下來問題又來了,如何獲得最小的w??文中采取的求解方式是利用拉格朗日對偶性,通過求解與原問題等價的對偶問題(dual problem),得到原始問題的最優解。通過給每一個約束條件加上一個拉格朗日乘子alpha,定義拉格朗日函數L(w,b,alpha)。一般對偶問題的求解過程如下:1)固定alpha,求L關於w,b的最小化。2)求L對alpha的極大。3)利用SMO算法求得拉格朗日乘子alpha。為了簡化對偶問題求解,這裡定義了參數beta,可見論文中的Eq.(8)。
算法主要流程:
1. 首先讀入config.txt,初始化程序參數,這一過程主要由Config類實現;
2. 判斷是否使用攝像頭進行跟蹤,如使用攝像頭進行跟蹤,則initBB=(120,80,80,80);
若使用視頻序列進行跟蹤,initBB由相應txt文件給出;
3. 將讀入的每幀圖像統一為320*240。
4. 由當前第一幀以及框initBB,實現對跟蹤算法的初始化。
4.1 Initialise(frame,bb)
由於我們之前獲取的initBB的坐標定義為float型,在這裡首先將其轉換為int型。
程序中選取haar特征,gaussian核函數,初始化參數m_needsIntegralImage=true,m_needsIntegralHist=false。因此在這裡,ImageRep image()主要實現了積分圖的計算(如果特征為histogram,則可實現積分直方圖的計算)。ImageRep類中的類成員包括frame,積分圖,積分直方圖。
4.2 UpdateLearner(image)
該函數主要實現對預測函數的更新,首先通過RadialSamples()獲得5*16=80個樣本,再加上原始目標,總共含有81個樣本。之後判斷這81個樣本是否有超出圖像邊界的,超出的捨棄。將剩余的樣本存入keptRects,其中,原始目標樣本存入keptRects[0]。定義一個多樣本類MultiSample,該類中的類成員主要包括樣本框以及ImageRep image。並通過Update(sample,0)來實現預測函數的更新。
4.3 Update(sample,0)
該函數定義在LaRank類下,文章中參考文獻《Solving multiclass support vector machines with LaRank》提到了這種算法。當我們分析LaRank頭文件時,可看到struck算法重要步驟全部聚集在這個類中。該類中的類成員包括支持模式SupportPattern,支持向量SupportVector,Config類對象m_config,Features類對象m_features,Kernel類對象m_kernel,存放SupportPattern的m_sps,存放SupportVector的m_svs,用於顯示的m_debugImage,目標函數中的系數m_C,矩陣m_K。
查看SupportPattern的定義,我們知道該結構主要包括x(存放特征值),yv(
,存放目標變化關系),images(存放圖片樣本),y(索引值,表明指定樣本存放位置),refCount(統計sv的個數??)。同樣,查看SupportVector的定義可知,該結構包括一個SupportPattern,y(索引值,表明指定樣本存放位置),b(beta),g(gradient),image(存放圖片樣本)。
在函數Update(sample,0)中,定義了一個SupportPattern* sp。首先對於每個樣本框,其x,y坐標分別減去原始目標框的x,y坐標,將結果存入sp->yv。然後對於每個樣本框內的圖片統一尺寸為30*30,並存入sp->images。對於每個樣本框,計算其haar特征值,並存入sp->x。令sp->y=y=0,sp->refCount=0,最後將當前sp存入m_sps。
4.3.1 ProcessNew(int ind)
之後執行ProcessNew(int ind),其中ind=m_sps.size()-1。由於每處理一幀圖像,m_sps的數量都增加1,這樣定義ind能夠保證ProcessNew所處理的樣本都是最新的樣本。在ProcessNew處理之前,首先看函數AddSupportVector(SupportPattern* x,int y,double g)的定義:
SupportVector* sv=new SupportVector;定義了一個支持向量。
為支持向量賦初值:sv->b=0.0,sv->x=x,sv->y=y,sv->g=g,並將該向量存入m_svs。接下來通過調用Kernel類中的Eval()函數更新核矩陣,即m_K,以後用於Algorithm 1計算。
現在再回到ProcessNew函數:
第一個AddSupportVector(),將目標框作為參數,增加一個支持向量存入m_svs,此時,m_svs.size()=1,m_K(0,0)=1.0,函數返回ip=0。
之後執行MinGradiernt(int ind),求得公式10中的g最小值。返回最小梯度的數值以及對應的樣本框存放位置。
第二個AddSupportVector(),將具有最小梯度的樣本框作為參數,增加一個特征向量存入m_svs,此時,m_svs.size()=2,並求得m_K(0,1),m_K(1,0),m_K(1,1)。函數返回in=1。
之後進行SMO算法進行計算,若某向量的beta值為0,則捨棄該支持向量。
4.3.2 BudgetMaintenance()
再之後執行函數BudgetMaintenance(),保證支持向量個數沒有超過100。
4.3.3 Reprocess()
進行Reprocess()步驟,一個Reprocess()包括1個ProcessOld()和10個Optimize();
ProcessOld()主要對已經存在的SupportPattern進行隨機選取並處理。和ProcessNew不同的地方是,這裡將滿足梯度最大以及滿足
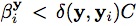
的支持向量作為正支持向量。負支持向量依然根據梯度最小進行選取。之後再次執行SMO算法,判斷這些支持向量是否有效。
Optimize()也是對已經存在的SupportPattern進行隨機選取並處理,但僅僅是對現有的支持向量的beta值進行調整,並不加入新的支持向量。正負支持向量的選取方式和ProcessOld()一樣。
4.3.4 BudgetMaintenance()
執行函數BudgetMaintenance(),保證支持向量個數沒有超過100。
5.跟蹤模塊(Algorithm 2)
首先通過ImageRep image()實現積分圖的計算,然後進行抽樣(這裡抽樣的結果和初始化時的抽樣結果不一樣,大概抽取幾千個樣本)。將超出圖像范圍的框捨棄,剩余的保留在keptRects中。對keptRects中的每一個框,計算F函數,即
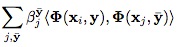
,將結果保存在scores裡,並記錄值最大的那一個,將其作為跟蹤結果。 UpdateDebugImage()函數主要實現程序運行時顯示的界面。UpdateLearner(image)同步驟4一致。
6.Debug() 顯示樣本圖像,綠色邊框的是正樣本,紅色邊框的負樣本。
 搭建基於Windows的React Native 開發環境(For Android)
搭建基於Windows的React Native 開發環境(For Android)
 Android-studio+Genymotion模擬器的聯合使用
Android-studio+Genymotion模擬器的聯合使用
 小豬的Android入門之路 Day 7 part 4
小豬的Android入門之路 Day 7 part 4
 Android NDK環境搭建與簡單實例
Android NDK環境搭建與簡單實例