編輯:關於Android編程
因為近期項目中開始使用Redis,為了更好的理解Redis並應用在適合的業務場景,需要對Redis設計與實現深入的理解。
我分析流程是按照從main進入,逐步深入分析Redis的啟動流程。同時根據Redis初始化的流程,理解Redis各個模塊的功能及原理。1.初始化server變量,設置redis相關的默認值
2.讀入配置文件,同時接收命令行中傳入的參數,替換服務器設置的默認值
3.初始化服務器功能模塊。在這一步初始化了包括進程信號處理、客戶端鏈表、共享對象、初始化數據、初始化網絡連接等
4.從RDB或AOF重載數據
5.網絡監聽服務啟動前的准備工作
6.開啟事件監聽,開始接受客戶端的請求
啟動的部分過程通過查看下圖,會更直觀。
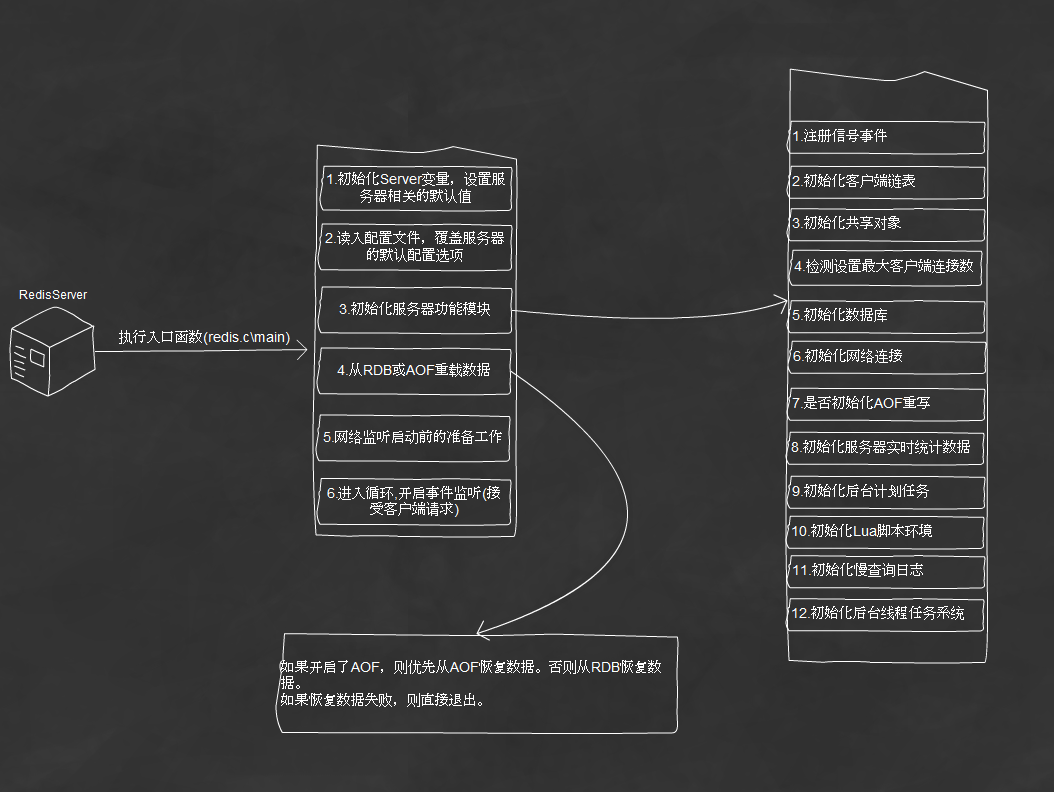
下面是針對啟動過程中,對各個模塊的詳細理解。(目前只分析了後台線程系統與慢查詢日志系統)

在使用redis時不少人都說一個問題,就是說redis宕機了怎麼辦?會不會數據丟失等等的問題。
現在來看看Redis提供的數據持久化解決方案,並通過原理分析優缺點。最終能得出Redis適合使用的應用場景。
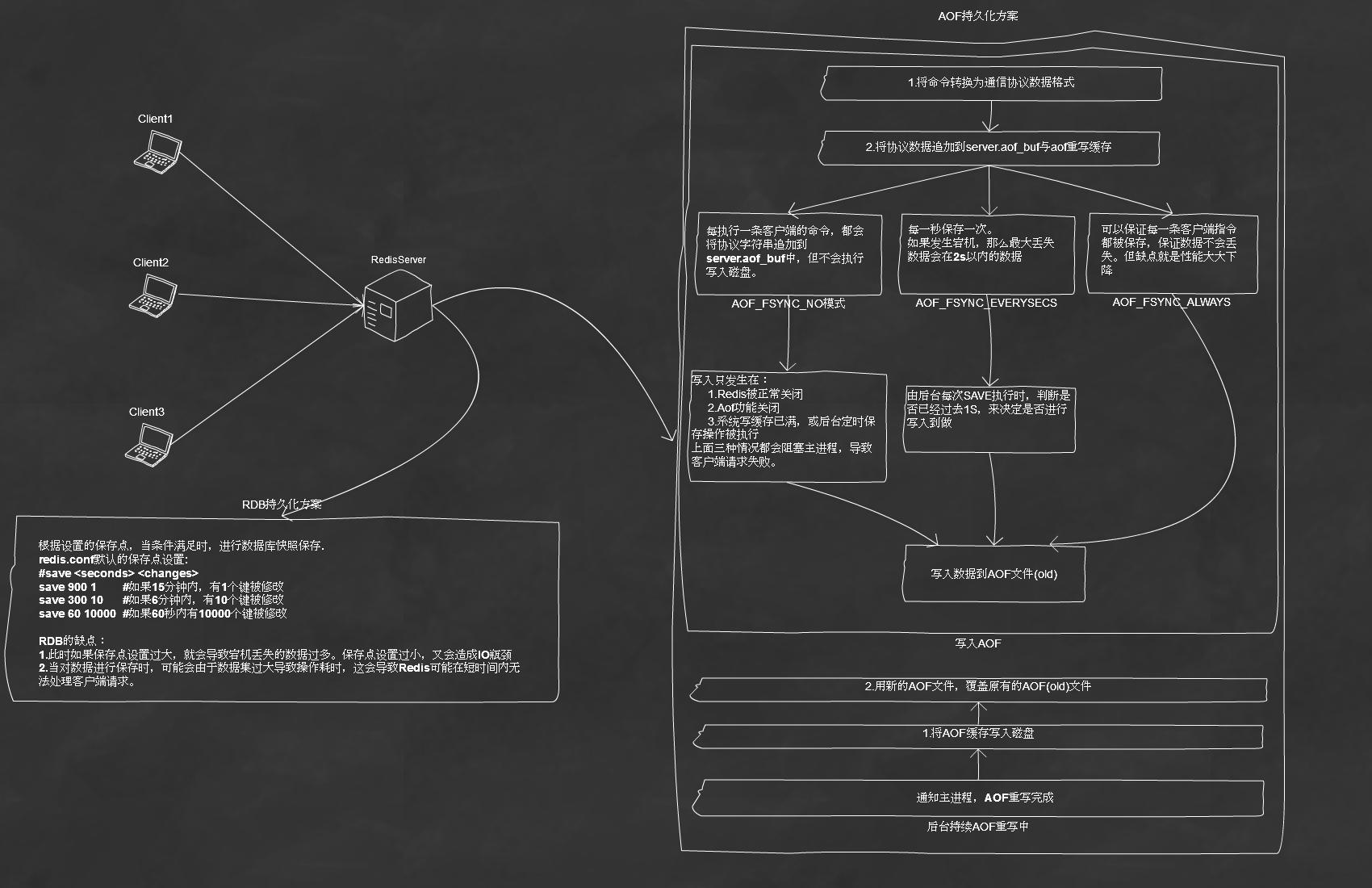
在Redis運行時,RDB程序將當前內存中的數據庫快照保存到磁盤中,當Redis需要重啟時,RDB程序會通過重載RDB文件來還原數據庫。
從上述描述可以看出,RDB主要包括兩個功能:
關於rdb的實現可以見src/rdb.c
a)保存(rdbSave)
rdbSave負責將內存中的數據庫數據以RDB格式保存到磁盤中,如果RDB文件已經存在將會替換已有的RDB文件。保存RDB文件期間會阻塞主進程,這段時間期間將不能處理新的客戶端請求,直到保存完成為止。
為避免主進程阻塞,Redis提供了rdbSaveBackground函數。在新建的子進程中調用rdbSave,保存完成後會向主進程發送信號,同時主進程可以繼續處理新的客戶端請求。
b)讀取(rdbLoad)
當Redis啟動時,會根據配置的持久化模式,決定是否讀取RDB文件,並將其中的對象保存到內存中。
載入RDB過程中,每載入1000個鍵就處理一次已經等待處理的客戶端請求,但是目前僅處理訂閱功能的命令(PUBLISH 、 SUBSCRIBE 、 PSUBSCRIBE 、 UNSUBSCRIBE 、 PUNSUBSCRIBE),其他一律返回錯誤信息。因為發布訂閱功能是不寫入數據庫的,也就是不保存在Redis數據庫的。
RDB的缺點:
再說RDB缺點時,需要提到的是RDB有保存點的概念。在默認的redis.conf中可以看到這樣的默認配置:
[plain]view plaincopy
- #save
[plain]view plaincopy
[plain]view plaincopy
[plain]view plaincopy
意思是當滿足上面任意一個條件時,將會進行快照保存。為了保證IO讀寫性能不會成為Redis的瓶頸,一般都會創建一個比較大的值來作為保存點。
1.此時如果保存點設置過大,就會導致宕機丟失的數據過多。保存點設置過小,又會造成IO瓶頸
2.當對數據進行保存時,可能會由於數據集過大導致操作耗時,這會導致Redis可能在短時間內無法處理客戶端請求。
以協議文本的方式,將所有對數據庫進行的寫入命令記錄到AOF文件,達到記錄數據庫狀態的目的。
a)保存
1.將客戶端請求的命令轉換為網絡協議格式
2.將協議內容字符串追加到變量server.aof_buf中
3.當AOF系統達到設定的條件時,會調用aof_fsync(文件描述符號)將數據寫入磁盤
其中第三步提到的設定條件,就是AOF性能的關鍵點。目前Redis支持三種保存條件機制:1.AOF_FSYNC_NO:不保存此模式下,每執行一條客戶端的命令,都會將協議字符串追加到server.aof_buf中,但不會執行寫入磁盤。寫入只發生在:1.Redis被正常關閉2.Aof功能關閉3.系統寫緩存已滿,或後台定時保存操作被執行上面三種情況都會阻塞主進程,導致客戶端請求失敗。2.AOF_FSYNC_EVERYSECS:每一秒保存一次由後台子進程調用寫入保存,不會阻塞主進程。如果發生宕機,那麼最大丟失數據會在2s以內的數據。這也是默認的設置選項3.AOF_FSYNC_ALWAYS:每執行一個命令都保存一次這種模式下,可以保證每一條客戶端指令都被保存,保證數據不會丟失。但缺點就是性能大大下降,因為每一次操作都是獨占性的,需要阻塞主進程。
b)讀取
AOF保存的是數據協議格式的數據,所以只要將AOF中的數據轉換為命令,模擬客戶端重新執行一遍,就可以還原所有數據庫狀態。
讀取的過程是:
1.創建模擬的客戶端
2.讀取AOF保存的文本,還原數據為原命令和原參數。然後使用模擬的客戶端發出這個命令請求。
3.繼續執行第二步,直到讀取完AOF文件
AOF需要將所有的命令都保存到磁盤,那麼這個文件會隨著時間變得越來越大。讀取也會變得很慢。
Redis提供了AOF的重寫機制,幫助減少文件的大小。實現的思路是:
[plain]view plaincopy
- LPUSHlist12345
[plain]view plaincopy
- LPOPlist
[plain]view plaincopy
- LPOPlist
[plain]view plaincopy
- LPUSHlist1
最初保存到AOF文件的將會是四條指令。但經過AOF重寫後,會變成一條指令:
[plain]view plaincopy
- LPUSHlist1345
同時,考慮到為了在AOF重寫時,不影響AOF的寫入增加了AOF重寫緩存的概念。
也就是說Redis在開啟AOF時,除了將命令格式數據寫入到AOF文件,同時也會寫入到AOF重寫緩存。這樣AOF的寫入、重寫就做到了隔離,保證了重寫時不會阻塞寫入。
c)AOF重寫流程
1.AOF重寫完成會向主進程發送一個完成的信號
2.會將AOF重寫緩存中的數據全部寫入到文件中
3.用新的AOF文件,覆蓋原有的AOF文件。
d)AOF缺點
1.AOF文件通常會大於相同數據集的RDB文件
2.AOF模式下性能與RDB模式下性能高低,主要取決於AOF選用的fsync模式
下面給出客戶端請求RedisServer時,server端持久化的部分操作圖解。
四、Redis數據庫的實現
Redis是一個鍵值對數據庫,稱為鍵空間。實現這種KV形式的存儲,Redis使用了兩種數據結構類型:1、字典
Redis字典使用的是哈希表實現,原本不准備詳細介紹Redis哈希表的實現。但發現Redis在實現哈希表時,
提供了一個很好的rehash方案,這個方案思路很好,甚至可以衍生到其他各個應用中使用,方案的名稱叫“漸進式Rehash”。
實現哈希表的方法大同小異,但為何各個開源軟件總是去開發自己獨有的哈希數據結構呢?
從研究PHP內核的哈希實現與Redis哈希實現,發現應用場景決定了必須定制才能更好的發揮性能。(關於PHP哈希實現可以參看:PHP內核中的神器之HashTable)
a)PHP主要應用於WEB場景,在WEB場景針對單次請求數據之間是隔離的,並且哈希的數量是有限的,那麼進行一次rehash也是很快的。
所以PHP內核使用阻塞形式rehash,即rehash進行中將不能對當前哈希表進行任何操作。
b)在來看Redis,常駐進程,接收客戶端請求處理各項事務,並且操作的數據是相關且數據量較大的,如果使用PHP內核的那種方式就會出現:
對哈希表進行rehash時,此時將阻塞所有客戶端請求,並發性能會大大下降。
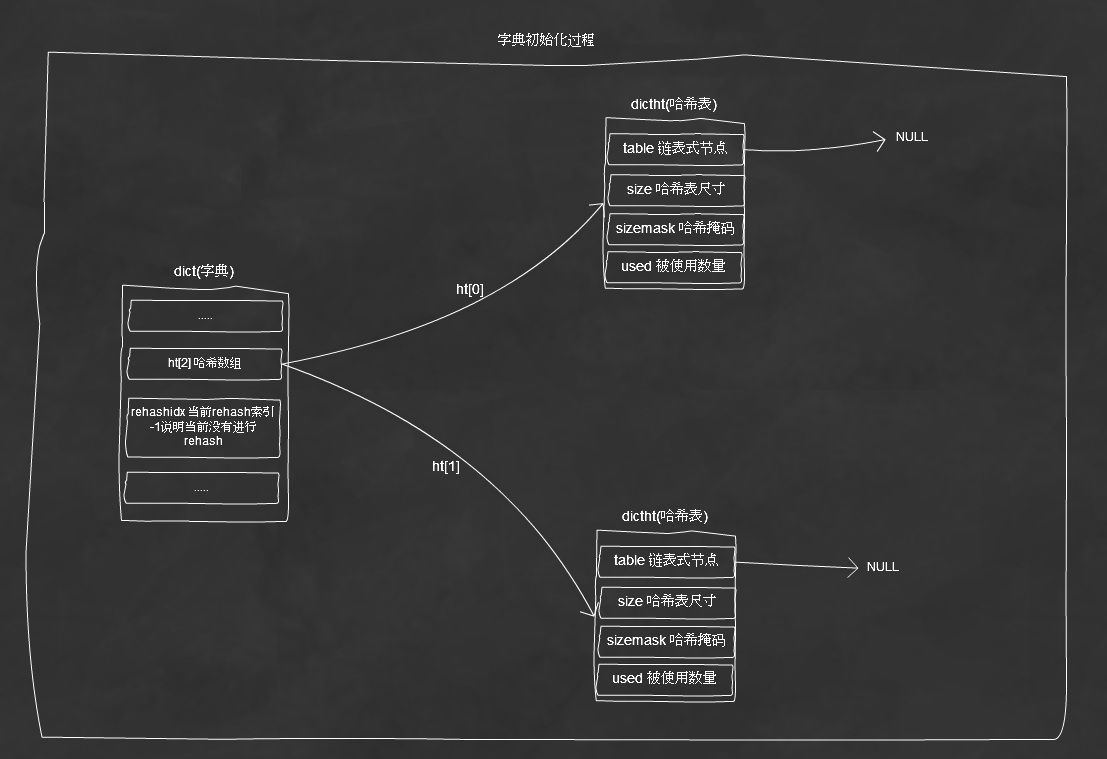
初始化字典圖解:
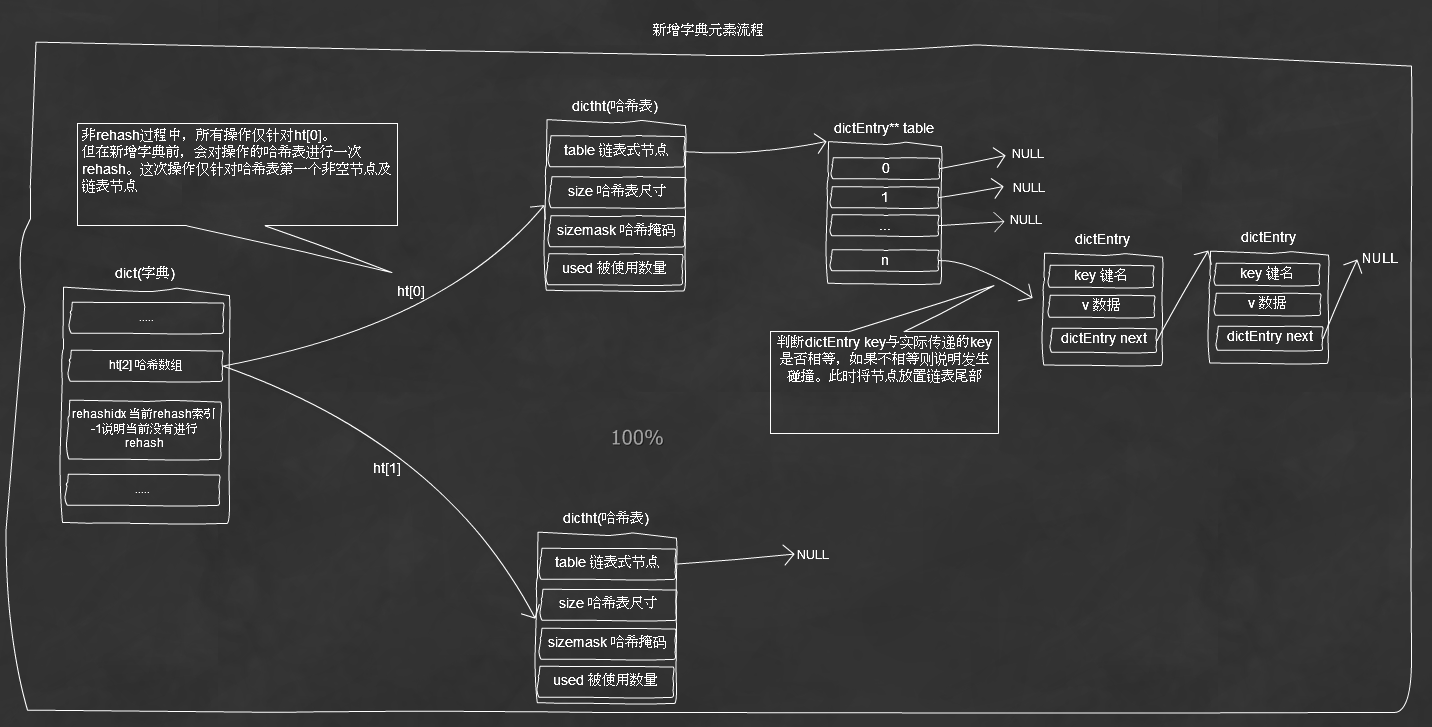
新增字典元素圖解:
Rehash執行流程:
 android 手機密碼忘了不用急
android 手機密碼忘了不用急
孩放假,在家沒事,所以把手機丟給他玩,沒想到他自己琢磨,竟然設置了密碼。各種試,各種問,都沒解開。實在不想清空數據,因為裡面記了很多賬,還有不少重要的短消息
 實例講解Android中的AutoCompleteTextView自動補全組件
實例講解Android中的AutoCompleteTextView自動補全組件
AutoCompleteTextView是一個具有自動補全功能的EditView,當用戶輸入數據後,AutoCompleteTextView就會將用戶輸入的數據與他自己的
 Android招財進寶手勢密碼的實現
Android招財進寶手勢密碼的實現
這幾個月都是在做招財進寶項目,一個高收益低風險的理財APP,有興趣的可以下載玩玩,收益不錯哦!!! 招財進寶下載地址:http://8.shengpay.com/
 詳解Android/IOS平台下抓包工具使用以及如何模仿一個app
詳解Android/IOS平台下抓包工具使用以及如何模仿一個app
抓包(Packet Capture),實際上就是對網絡請求(包括發送與接收)的數據包進行截獲、重發、編輯、轉存等操作,在Android下,也經常被用來進行數據截取等。學會