編輯:關於Android編程
前一篇文章我們介紹了Android中直播視頻技術的基礎大綱知識,這裡就開始一一講解各個知識點,首先主要來看一下視頻直播中的一個重要的基礎核心類:ByteBuffer,這個類看上去都知道了,是字節緩沖區處理字節的,這個類的功能非常強大,也在各個場景都有用到,比如網絡數據底層處理,特別是結合網絡通道信息處理的時候,還有就是後面要說到的OpenGL技術也要用到,當然在視頻處理中也是很重要的,因為要處理視頻流信息,比如在使用MediaCodec進行底層的視頻流編碼的時候,處理的就是字節,我們如果單純的借助字節數組來進行操作的話,首先效率有很大的問題,其次是數組最大的問題就是擔心越界報異常等信息,這個在處理的時候特別麻煩,所以Java中就有類似的高效率的處理字節的封裝類:ByteBuffer
關於這個類,其實他有兩個子類:一個是HeapByteBuffer和DirectByteBuffer關於這兩個類的區別很好理解:
DirectByteBuffer不是分配在堆上的,它不被GC直接管理(但Direct Buffer的JAVA對象是歸GC管理的,只要GC回收了它的JAVA對象,操作系統才會釋放Direct Buffer所申請的空間),它似乎給人感覺是“內核緩沖區(buffer in kernel)”。HeapByteBuffer則是分配在堆上的,或者我們可以簡單理解為Heap Buffer就是byte[]數組的一種封裝形式,查看JAVA源代碼實現,HeapByteBuffer也的確是這樣。 說白了就是HeapByteBuffer是在JVM堆內存中分配會被JVM管理回收,但是DirectByteBuffer是直接由系統內存進行分配,不被JVM管理。通過上面的區別看到:
1、創建和釋放DirectByteBuffer的代價比HeapByteBuffer得要高,因為JVM堆中分配和釋放內存肯定比系統分配和創建內存高效
2、因為平時的read/write,都會在I/O設備與應用程序空間之間經歷一個“內核緩沖區”。 DirectByteBuffer就好比是“內核緩沖區”上的緩存,不直接受GC管理;而Heap Buffer就僅僅是byte[]字節數組的包裝形式。因此把一個Direct Buffer寫入一個Channel的速度要比把一個HeapByteBuffer寫入一個Channel的速度要快。
所以這兩個類操作起來各有好處,要視情況而定,一般如果是一個ByteBuffer經常被重用的話,就可以使用DirectByteBuffer對象。如果是需要經常釋放和分配的地方用HeapByteBuffer對象。
下面來通過他們的源碼來確定內存分配原理,首先是HeapByteBuffer對象:

看到了,這裡直接使用了byte數組的,Java中的數組都是在JVM的堆內存中進行分配的。
再來看看DirectByteBuffer對象:
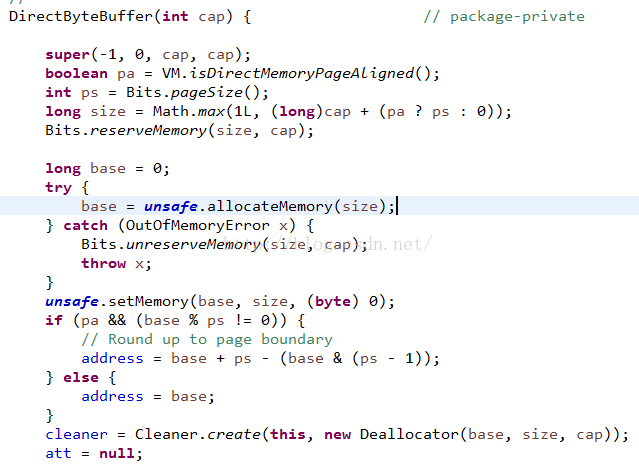
內部直接使用了Unsafe類對象,關於這個類:
Java不能直接訪問操作系統底層,而是通過本地方法來訪問。Unsafe類提供了硬件級別的原子操作,主要提供了以下功能:
1》、通過Unsafe類可以分配內存,可以釋放內存;
類中提供的3個本地方法allocateMemory、reallocateMemory、freeMemory分別用於分配內存,擴充內存和釋放內存,與C語言中的3個方法對應:
public native long allocateMemory(long l);
public native long reallocateMemory(long l, long l1);
public native void freeMemory(long l);
2》、可以定位對象某字段的內存位置,也可以修改對象的字段值,即使它是私有的。
從上面源碼分析可以得知HeapByteBuffer對象是直接操作堆中的字節數組對象的,而DirectByteBuffer對象是直接操作系統內存的。
好了上面分析了ByteBuffer的兩個子類,這兩個子類會通過兩個方法來獲取的:
一個是allocate方法獲取到HeapByteBuffer:
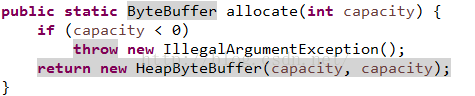
一個是allocateDirect方法獲取到DirectByteBuffer:

這兩個方法的使用在後面會詳細說明。
不管是HeapByteBuffer還是DirectByteBuffer,他們操作字節的方法都是相同的,因為都是繼承ByteBuffer類,大部分操作字節的方法都在這個父類中定義的。後續的例子中就用HeapByteBuffer類來做演示,先來大致分析一下HeapByteBuffer的工作原理,看一下他的取出一個字節的方法:

這個hb對象是在父類ByteBuffer中定義的:
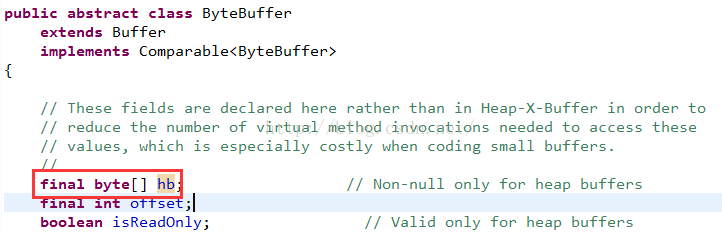
好了,看到了,其實hb就是一個字節數組,所以說HeapByteBuffer是在JVM的堆內存中分配的,我們再看看DirectByteBuffer類的get方法:

這裡直接使用Unsafe對象進行操作的,並沒有使用hb字節數組。
上面分析了ByteBuffer有兩個重要的子類來進行操作字節,他們兩個各有優勢也有很大的區別,然後分析了他們兩個類在處理字節的基本原理。下面就借助HeapByteBuffer這個子類來介紹ByteBuffer中一些操作字節的方法,這裡大致分為四類:
因為Java中沒有指針的概念,但是為了下面內容講解方便,這裡就引用了指針的名詞。先來看一下圖解:
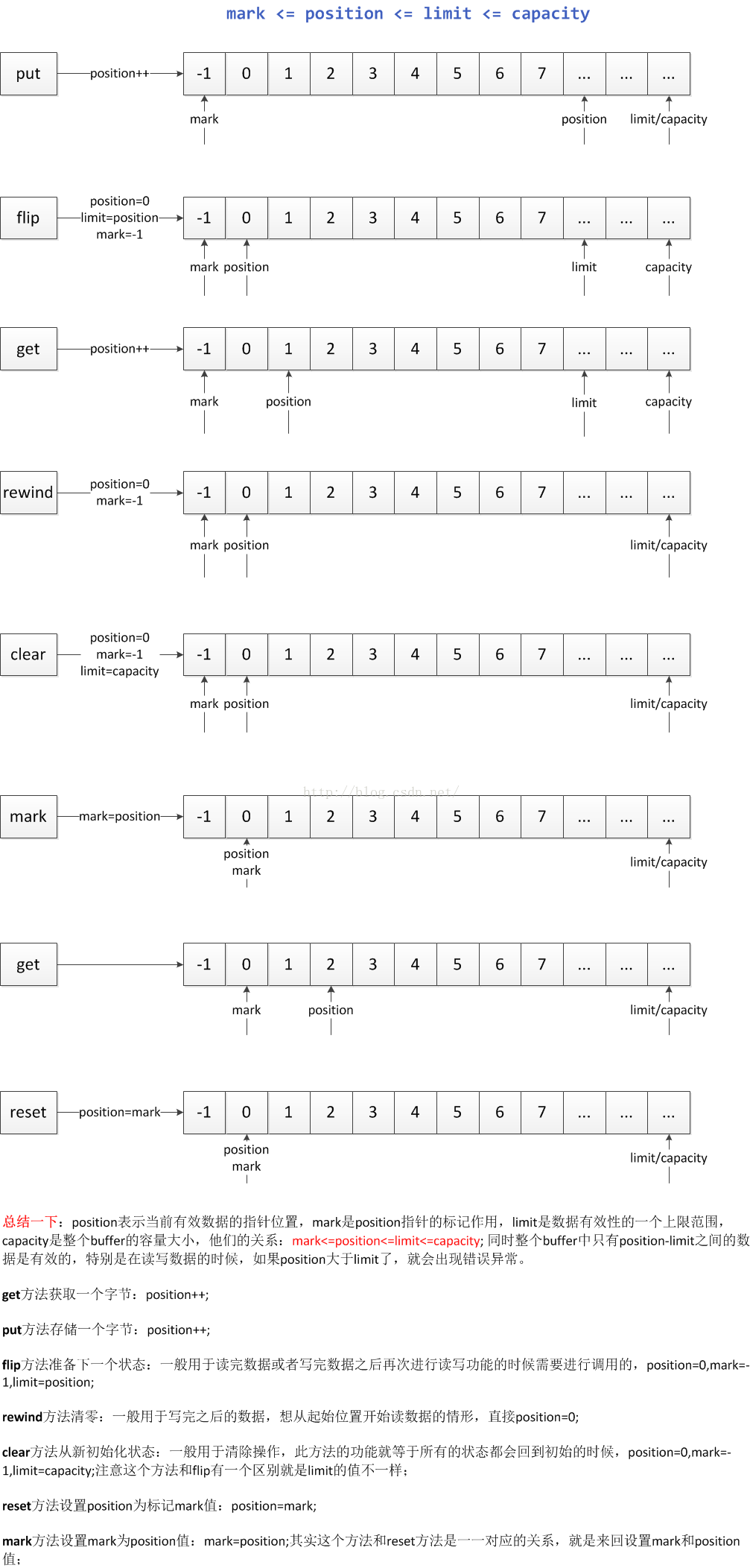
這張圖中我們可以看到在操作ByteBuffer的時候,有四個指針來進行操作:
capacity指針:這個指針是在調用allocate方法分配完內存之後直接指向字節數組的末尾,不會在發生改變的,除非再次調用allocate方法重新分配內存大小。
limit指針:這個指針在初始化分配內存的時候和capacity指針一樣,指向數組的末尾,但是這個指針是會發生改變的,有一個limit方法可以設置他的值。同時像flip,clear等方法也會改變他的值。它更像是數組的一個有效數據的范圍上限指針。limit<=capacity
position指針:這個指針是指向當前有效數據的起始位置,在初始化分配內存的時候指向數組的起始位置,後續可以通過position方法進行設置,同時他在很多地方都會發生改變,特別是在讀寫數據方法get,put的時候,每次讀寫一次,指針就加一,直到遇到了limit指針,position<=limit;所以可以看到整個數組中只有position-limit之間的數據是有效的,是可以進行讀寫操作的。
mark指針:這個指針在初始化的時候就是-1,起到一個數組指針不合法的哨兵作用,只要不調用mark方法,他的值一直是-1,最主要的是對position進行標記作用,有時候有一種需求就是想臨時保存一下當前讀寫指針position的值,因為position隨時都會發生改變,但是有時候還想再回來,那麼mark指針就是這個作用,用來標記position的前一個狀態,對應的方法是mark,還原方法是reset,這個指針只有在mark方法,clear,flip等方法會發生變化。mark<=position
通過上面的四個指針分析之後,發現有了mark和limit指針,我們不會擔心數組越界的問題了,有了position指針我們能夠很簡單的操作數組數據,效率也高。
下面通過一個代碼來驗證這些方法的具體作用:
1、首先看一下打印ByteBuffer中四個指針的方法,這裡ByteBuffer都提供了position,limit,capacity三個指針的訪問方法,但是mark指針沒有,所以這裡需要用反射去操作,注意的是,我們allocate出來的是HeapByteBuffer對象,但是這四個指針都是定義在Buffer類中的,HeapByteBuffer->ByteBuffer->Buffer

下面來看一個這些方法的操作案例:

1、allocate方法
這裡首先調用allocate方法分配10個大小的內存,然後從起始位置開始寫入5個數據,再次調用flip方法准備讀狀態,然後在從起始位置讀取四個數據,運行結果如下:

2、flip方法
這裡看到了,在put完數據之後,position就變成了5了,所以需要調用flip方法來改變狀態,才能正確的讀到剛剛寫入的數據,假設這裡不調用flip方法:
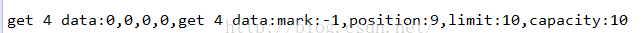
看到了,讀取出來的數據都是髒數據0,而且看到position變成了5+4=9了。所以在每次讀寫之後一定要記得改變狀態,改變狀態有flip,rewind,clear這三種方法,但是flip方法是最合理的。因為他把有效數據的末尾指針position賦值給了limit指針。
看一下flip源碼:
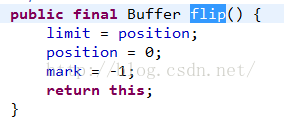
3、put方法
再來看一下put方法:
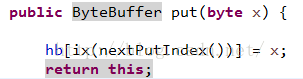
使用直接索引的方式寫入字節數組,看看nextPutIndex方法:
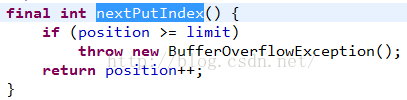
看到了position++了,所以所有put方法都會改變position的值。
同樣的get方法是同理,這裡不再解釋了。
4、clear方法
後續的代碼,我們使用了put方法直接寫入一個字節數組,但是在之前我們使用了clear方法來設置狀態,下面來看看clear源碼:
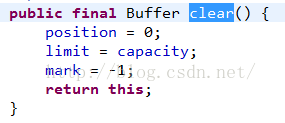
這時候就相當於到了起始狀態了:來看看put方法源碼:
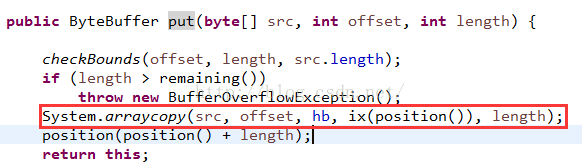
其實內部實現很簡單,就是把源字節數組copy到hb中,然後position=position+length即可。
5、rewind方法
然後調用rewind方法設置狀態,准備後面的讀取數據,看一下rewind方法源碼:
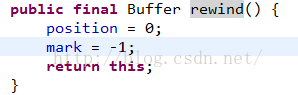
這裡直接把position清零,這樣才能正確的讀取到剛剛的那個寫入的數據,但是這個方法有一個問題,也就是和flip不同的地方,我們下面來改一下代碼:
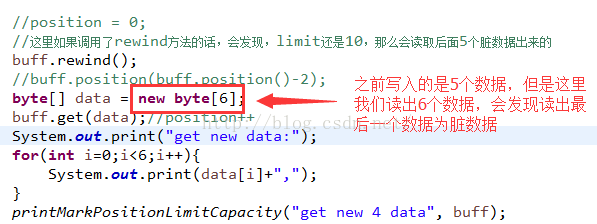
這裡看到,我們上面寫入了5個數據,但是調用rewind方法之後,再去讀6個數據,這時候肯定不會出現錯誤的,但是會讀取髒數據:
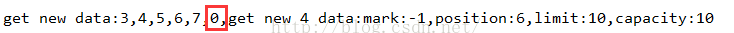
因為limit=capacity=10,但是flip方法就會把limit設置成position,不會讀出髒數據的,所以flip和rewind方法的區別。
6、position和limit方法
這裡我們還可以手動去設置position和limit值,做到我們想要的想過,比如這裡可以模仿clear方法:

看到了,這裡手動的將狀態設置初始狀態,打印結果:

7、mark和reset方法
下面再來看一下mark和reset方法的使用效果:

首先調用mark把mark設置position=0,然後在去操作position值,最後在調用reset進行復位,position又等於0了,看一下運行結果:

8、remaining和hasRemaining方法
再來看一下ByteBuffer容量剩余的方法remaining和hasRemaining:

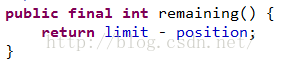
hasRemaining方法就是判斷ByteBuffer有沒有到上限,即position是否大於limit,看看方法的源碼:
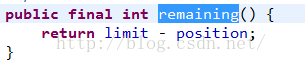
同時還有一個remaining方法獲取當前剩余的范圍值,就是limit-position的值,看看源碼:
看看上面的運行結果:

好了,上面就看到了所有的關於ByteBuffer四個指針的操作方法,下面來總結一下:
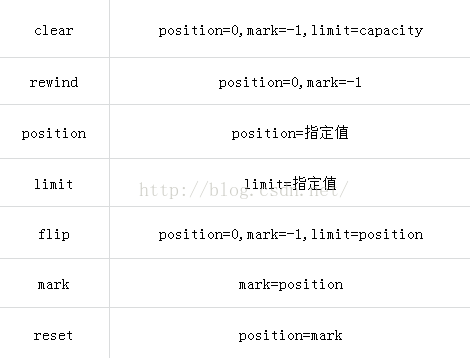
1、四個指針:mark,position,limit,capacity,他們之間的關系:mark<=position<=limit<=capacity
2、allocate分配方法可以改變capacity的值
3、flip,limit,clear,allocate方法可以改變limit的值
4、put,get,flip,clear,rewind,position,reset等讀寫數據的方法都會改變position的值
5、mark,flip,clear,rewind等方法會改變mark的值
6、capacity,limit,position是可以通過方法獲取到值的,其中limit,position方法可以直接改變limit和position的值
7、hasRemaining和remaining方法是用來判斷當前ByteBuffer中還有多少空間可以使用,一般先判斷hasRemaining是否有空,如果沒有空間的話,在把capacity設置成limit的,使用limit(buff.capacity)方法設置即可。如果在超出的話,就需要重新分配空間了。
這裡主要來介紹一下ByteBuffer的內存分配內容,在之前其實已經介紹了關於allocate和allocateDirect方法的區別了,其實還有一個重要方法就是wrap方法,下面先來看一下圖簡介:
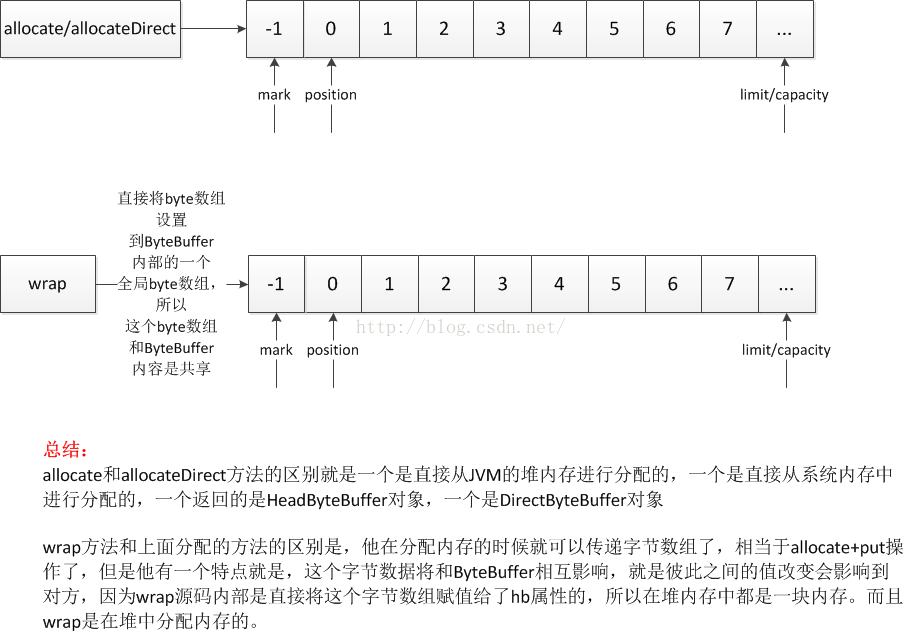
下面來看一下代碼:

1、allocate和allocateDirect方法
這裡首先查看JVM內存大小,然後在使用allocate方法分配一個大內存,在查看JVM內存大小,然後在使用allocateDirect方法分配一個大內存,在查看JVM內存大小,看看打印結果:

看到了,在調用了allocate方法之後,JVM內存發生了變化,但是allocateDirect方法沒有,還是之前allocate方法執行完之後的內存大小。
2、wrap方法
然後在看看wrap方法進行內存分配,同時進行寫數據,首先來看一下wrap的源碼:
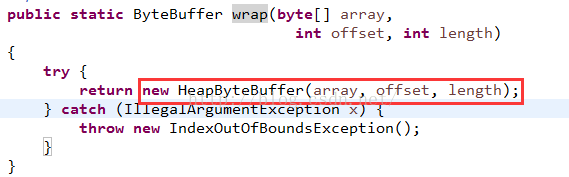
這裡看到了,直接構造一個HeapByteBuffer對象返回了,傳入的array就直接賦值給了全局數組hb了,看看構造方法:

構造方法中,前四個參數就是mark,position,limit,capacity的值了,從這裡看到,position就是wrap中需要傳遞字節數組的有效數據的開始索引,limit就是有效數據的上限,capacity就是整個數組的大小了,這樣看來其實是很合理的,我們調用wrap方法之後看結果:

看到了,這裡的position和limit值就是數組起始位置和結束位置。同時修改了字節數組的第11個值,然後ByteBuffer內容也被影響進行了修改了。
所以看到wrap方法有這幾個特點:
1、他的功相當於是allocate+put方法的結合,同時分配內存,也寫入數據了。
2、寫入的字節數據和ByteBuffer內容在堆中是一份數據的,相互影響的,所以這個方法在使用的時候需要特別小心,注意數據的有效性,同時這個方法因為是直接操作堆內存的,所以返回的就是HeapByteBuffer對象了。
3、通過傳遞的字節數組的offset和len值,來設置mark,position,limit,capacity的大小了
ByteBuffer中操作子Buffer的方法大致是四個:slice,duplicate,array,get;下面來看一下圖解吧:
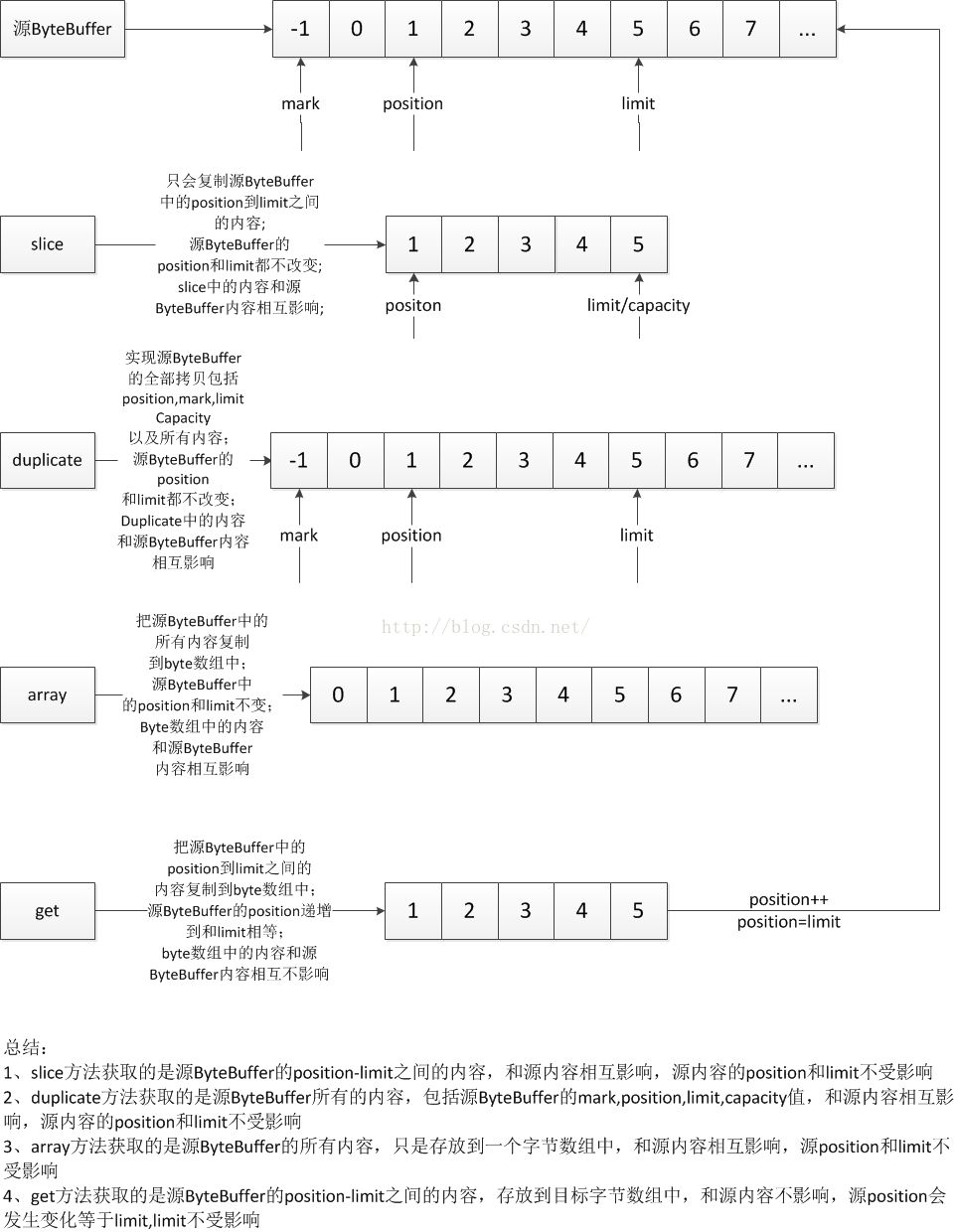
看到上面的圖之後,發現這四個方法其實比較起來就三個方面:拷貝的內容范圍,會影響源內容,執行完之後會影響源內容的position和limit值;
1、slice方法
下面通過代碼來看看,首先看一下slice方法:
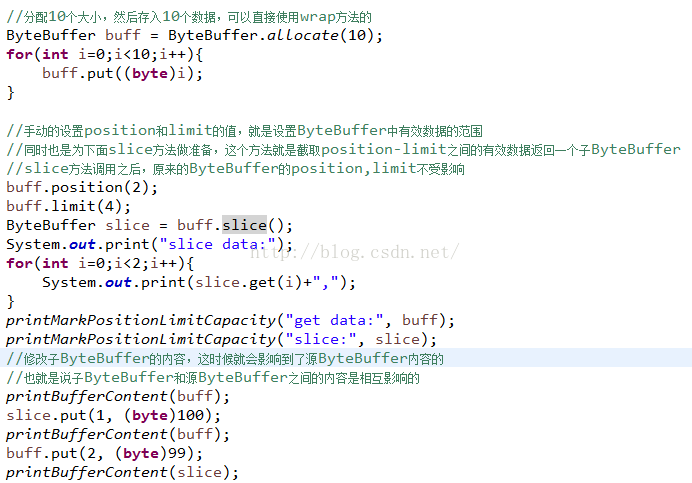
slice方法其實就是copy一個原來的ByteBuffer的position-limit之間的有效數據,所以如果你想拷貝那一段數據,需要提前設置position和limit值,同時看看slice內容和源內容是否相互影響,看一下運行結果:

再來看一下slice源碼:
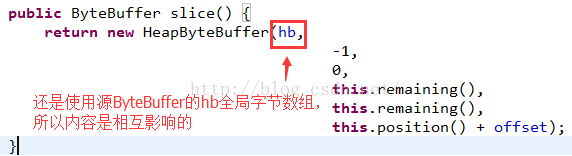
看到源碼就知道了,和源ByteBuffer共用一個hb,只是改變了position和limit,capacity的值,內容肯定是相互影響的。但是沒有影響到了源ByteBuffer的position和limit值。
2、duplicate方法
再來看一下duplicate方法,這個方法是直接拷貝源ByteBuffer的一個副本,不僅把所有的內容拷貝過來,而且還把mark,position,limit,capacity也全部拷貝過來了:
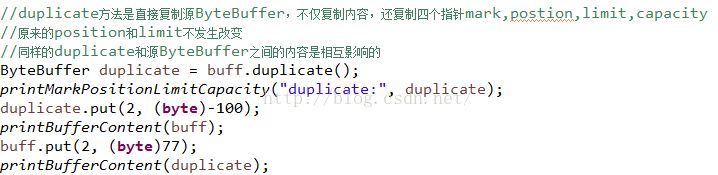
看一下運行結果:

在來看一下duplicate的源碼:
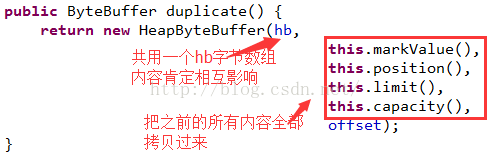
這個構造方法直接把hb賦值過去,同時設置源ByteBuffer的所有標記指針值。所以內容肯定也是相互影響的。但是沒有影響到了源ByteBuffer的position和limit值。
3、array方法
再來看一下array方法,這個方法也是拷貝所有的內容到一個字節數組中:

運行結果看看:

下面來看看源碼:
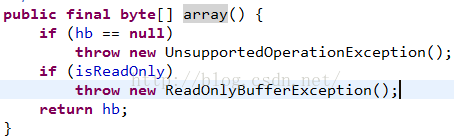
這個方法很簡單,直接返回了ByteBuffer全局的字節數組hb,那麼內容肯定是相互影響的,但是沒有影響到了源ByteBuffer的position和limit值。
4、get方法
最後再來看一個get方法,他是拷貝源ByteBuffer的position到limit之間的有效數據內容的:


查看源碼:
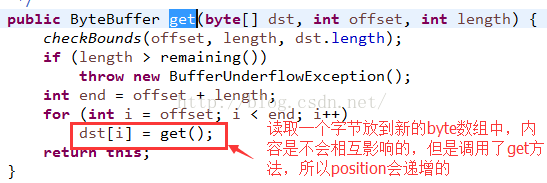
源碼中可以看到,內部使用了get方法讀取一個字節,然後存放到新的字節數組中,那麼這樣看來就不會內容之間相互影響了,但是因為調用了get方法,所以position值會遞增的。
看完了上面的四個方法,下面就來總結一下吧:
1》、slice方法獲取的是源ByteBuffer的position-limit之間的內容,和源內容相互影響,源內容的position和limit不受影響
2》、duplicate方法獲取的是源ByteBuffer所有的內容,包括源ByteBuffer的mark,position,limit,capacity值,和源內容相互影響,源內容的position和limit不受影響
3》、array方法獲取的是源ByteBuffer的所有內容,只是存放到一個字節數組中,和源內容相互影響,源position和limit不受影響
4》、get方法獲取的是源ByteBuffer的position-limit之間的內容,存放到目標字節數組中,和源內容不影響,源position會發生變化等於limit,limit不受影響
這裡主要來看看ByteBuffer中的數據壓縮,以及和其他基本類型之間的轉化內容了,先來看一下圖解:
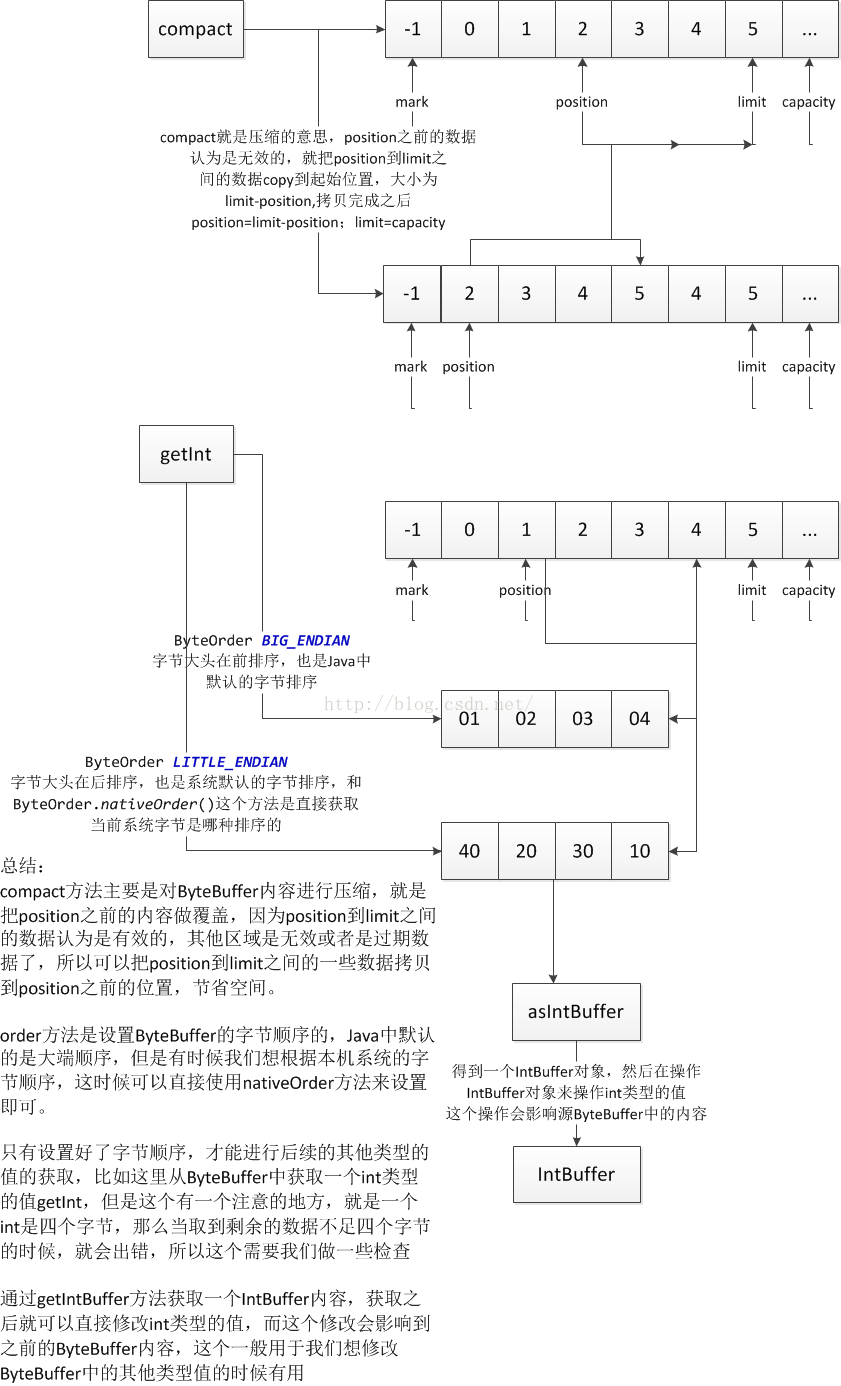
下面依次來看看具體內容:
1、compact方法
首先來看一下壓縮方法compact:
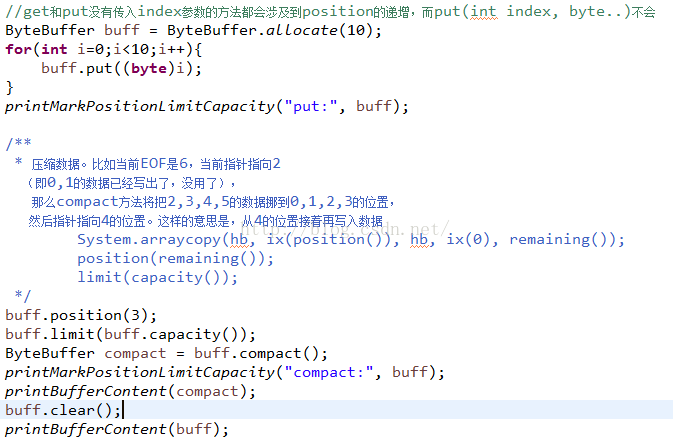
這裡首先初始化ByteBuffer內容為0-10,然後設置position為3,那麼壓縮前,0-2這三個位置就是無效數據了,那麼就把從3開始的,長度是10-3=7的數據拷貝到位置是0-7中。同時position=limit-position;為了方便看結果,這裡調用clear方法,回到初始狀態,看看結果:

看到了結果就會明白了,這裡個把0-2的位置給頂替了,再來看看他的源碼:
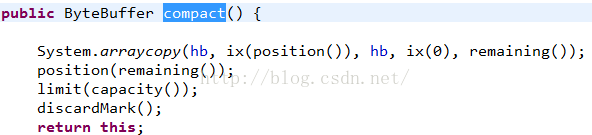
通過源碼可以看到:直接拷貝內容,然後在設置position和limit的值。
2、getInt和asIntBuffer,order方法
再來看一下ByteBuffer中和其他類型之間的轉化
說到其他類型的轉化之前,必須先說一下字節排序,我們知道所有的內容最後存放到內存中都是二進制,那麼在學習計算機組成原理的時候都知道,內存中的數據有高序和低序之分的,那麼不同的排序,輸出的結果也是不同的,同樣ByteBuffer中的字節也是有排序的,簡稱大端和小端排序,Java中默認的是大端排序,如果想設置小端排序的話,可以通過order方法進行設置:

有三個選項,前兩個是枚舉,大端排序和小端排序,後一個是一個方法,這個方法其實就是底層實現的,根據本機系統支持的排序,因為Java默認是大端排序的,所以有時候我們在涉及到底層開發的時候,需要根據本機系統來進行操作,那麼這時候這個方法就非常有效了,比如後面說到的openGL就經常用到這個方法。
設置完了字節排序之後,我們才能開始轉化其他類型,因為其他類型都是由多個字節組成的,比如int類型就4個字節,可以通過getInt方法來獲取一個int值,但是需要注意的是ByteBuffer的字節有效性,每次取數據都是在position到limit之間的數據,然後通過取4個字節以及字節排序來進行int值的轉化,加入limit-position % 4 !=0的話,那麼在取最後一個int值會發生錯誤,因為字節個數不足4了,這個需要做一次判斷的,下面來看看代碼:
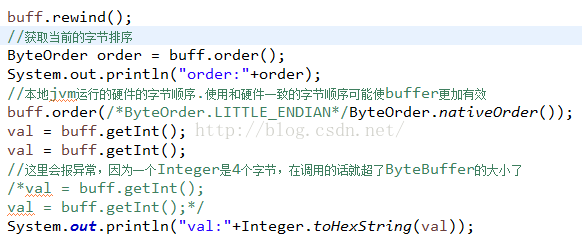
首先我們打印一下JVM默認的字節排序,然後在設置本機系統的字節排序,運行結果:

這裡看到了,默認是大端排序的,然後通過打印結果是:07090809來看應該是低端排序了,因為本來是:
03040506 07080907 0809
因為調用了兩次getInt,所以是中間的內容,但是看到了是倒序的,加入我們沒有設置字節排序,使用默認的排序:
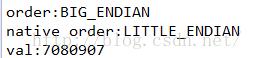
這下就看到了,nativeOrder是小端排序的,看到內容也是。
這裡同時也看到了,每次調用getInt方法,position都會遞增的,下面來看一下源碼:

nextGetIndex方法在之前分析了,內部是position做加法操作的。
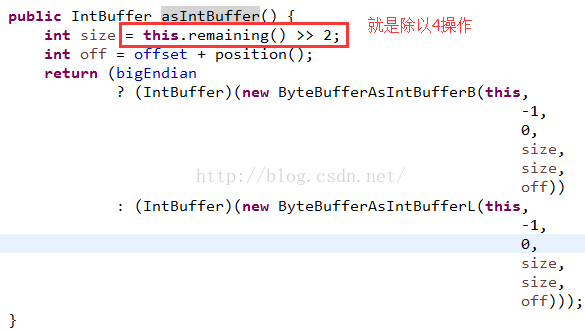
最後再來看看如果想改ByteBuffer中整型內容值該怎麼辦?有一個asIntBuffer方法:

調用了asIntBuffer對象返回的是IntBuffer對象,其他類型的都有對應的對象,然後我們打印結果,在修改IntBuffer中的值,在打印ByteBuffer內容,看看結果:

看到了,修改了前四個字節的內容,正好是IntBuffer的第一個數據,而IntBuffer的limit=2,這個就是通過ByteBuffer的remaining的值除以4得到的,這裡是(limit-position=10)/4=2,可以看看源碼:
到這裡,我們就看完了,如何把ByteBuffer中字節轉化成int類型,同時修改int值來同步到ByteBuffer中,當然其他基本類型操作方法類似的,最後再來看一個比較安全有用的方法:asReadOnlyBuffer,這個方法主要是返回一個只讀的ByteBuffer的副本對象,如果我們調用了這個對象的put方法:

運行就會出錯:

所以這個方法對於,我們不想給源ByteBuffer的數據造成影響,但是又想讀取數據的話,就這個方法了。
上面就介紹完了整個ByteBuffer的所有內容了,首先我們知道他是一個操作字節數據的高效類。
1、ByteBuffer的操作原理
ByteBuffer有兩個子類HeapByteBuffer和DirectByteBuffer,這兩個類的區別就在於前一個類是基於JVM堆內存的,後一個是基於系統內存的,他們通過allocate和allocateDirect方法獲取。
2、四個“指針”
mark,position,limit,capacity這四個指針來操作數據,mark最不常用,默認是-1,就是為了存儲上一次position的值,而position是最常用的,在進行數據的讀寫,狀態改變都會設置這個值,就是表示當前有效數據的起始位置,limit的值是當前有效數據的末尾位置,可以通過limit方法直接設置值,capacity值是整個內存的容量,一般不會改變,只有在內存不足的的時候再次分配會被重新復制。同時position和limit可以通過對應的方法隨意設置指定的值,而position和limit以及capacity這三個可以有對應的方法來訪問他們的值。最重要的是:position到limit中間的數據被認為是有效數據。
3、操作內存分配方法
這裡主要介紹了allocate和allocateDirect方法的區別,以及wrap方法和前面的兩個方法的區別,wrap方法相當於是allocate+put方法結合體,需要注意的是wrap方法傳遞進入的字節數組和ByteBuffer內容是相互影響的。
4、操作子Buffer的方法
這裡主要介紹了slice方法,duplicate方法,array方法,get方法,這四個方法從三個方面:拷貝源ByteBuffer內容,是否影響源ByteBuffer內容,是否會改變源ByteBuffer的postion和limit值,來作比較的。
5、壓縮數據以及和其他基本類型的轉化
這裡主要介紹了ByteBuffer中的compact方法的作用,然後介紹了ByteBuffer中的字節排序,以及如何轉化成int類型值,修改int類型值。
最後再來看一張表格,來比較這些方法的區別:
首先是操作四個指針的方法:
然後是操作內容的一些方法比較:

項目下載:http://download.csdn.net/detail/jiangwei0910410003/9575398
介紹了ByteBuffer內容之後,我們就可以進行後續的操作了,比如在處理MediaCodec中編碼視頻流的時候,用到了ByteBuffer類型,在處理OpenGL的時候,需要用到ByteBuffer類型,當然介紹完了ByteBuffer類型之後,其他基本類型大致相同也就可以大致了解就可以了。
 Android開發自學筆記(四):APP布局下
Android開發自學筆記(四):APP布局下
篇幅較長遂分成上下兩篇,上一篇我們已經快要一氣呵成了,但是美中不足的是,這個界面並不能討得美工MM的歡心,美工MM曾寄希望於您,卻交出這麼作出這麼一副死型樣,我都替你汗顏
 Android仿IOS底部彈出對話框
Android仿IOS底部彈出對話框
在Android開發過程中,常常會因為感覺Android自帶的Dialog的樣式很丑,項目開發過程中會影響整體效果,會使得開發過程很是憂傷....(話唠時間結束!)本文我
 Android 中ListView點擊Item無響應問題的解決辦法
Android 中ListView點擊Item無響應問題的解決辦法
如果listitem裡面包括button或者checkbox等控件,默認情況下listitem會失去焦點,導致無法響應item的事件,最常用的解決辦法是在listitem
 android屬性動畫Property
android屬性動畫Property
1、概述Android提供了幾種動畫類型:View Animation 、Drawable Animation 、Property Animation 。View Ani