編輯:關於Android編程
curl -XPUT localhost:9200/my_index/my_type/_bulk -d '
{ "index": { "_id": 1 }}
{ "title": "The quick brown fox" , "age":"18"}
{ "index": { "_id": 2 }}
{ "title": "The quick brown fox jumps over the lazy dog" , "age":"20" }
{ "index": { "_id": 3 }}
{ "title": "The quick brown fox jumps over the quick dog" , "age":"19" }
{ "index": { "_id": 4 }}
{ "title": "Brown fox brown dog" , "age":"18" }
'
請求示例, 查詢index名為my_index、type名為my_type下所有的數據
from、size: 用於分頁,從第0條開始,取10條數據
sort: 排序的條件
aggs: 聚合分析的條件,與aggregations等價
bool: 用於組合多個查詢條件,後面的內容會講解
curl -XPOST localhost:9200/my_index/my_type/_search?pretty=true -d '
{
"query": {
"bool": {
"must": [
{
"match_all": { }
}
],
"must_not": [ ],
"should": [ ]
}
},
"from": 0,
"size": 10,
"sort": [ ],
"aggs": { }
}
'
返回結果:
took: 本次請求處理耗費的時間(單位:ms)
time_out: 請求處理是否超時。tip:如果查詢超時,將返回已獲取的結果,而不是終止查詢
_shards:本次請求涉及的分片信息,共5個分片處理,成功5個,失敗0個
hits:查詢結果信息
hits.total: 滿足查詢條件總的記錄數
hits.max_score: 最大評分(相關性),因為本次沒有查詢條件,所以沒有相關性評分,每條記錄的評分均為1分(_score=1)
hits.hits: 本次查詢返回的結果, 即從from到min(from+size,hits.total)的結果集
hits.hits._score: 本條記錄的相關度評分,因為本次沒有查詢條件,所以沒有相關性評分,每條記錄的評分均為1分
hits.hits._source: 每條記錄的原數據
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 4,
"max_score" : 1.0,
"hits" : [ {
"_index" : "my_index",
"_type" : "my_type",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"age" : "20"
}
}, {
"_index" : "my_index",
"_type" : "my_type",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"title" : "Brown fox brown dog",
"age" : "18"
}
}, {
"_index" : "my_index",
"_type" : "my_type",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "The quick brown fox",
"age" : "18"
}
}, {
"_index" : "my_index",
"_type" : "my_type",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"age" : "19"
}
} ]
}
}
Client client = ConnectionUtil.getLocalClient();
SearchRequestBuilder requestBuilder =
client.prepareSearch("my_index").setTypes("my_type")
.setFrom(0).setSize(10);
Log.debug(requestBuilder);
SearchResponse response = requestBuilder.get();
Log.debug(response);
term, terms, range, exists, missing
match, match_all, multi_match
高亮搜索、scroll、排序
主要用於精確匹配,如數值、日期、布爾值或未經分析的字符串(not_analyzed)
{ "term": { "age": 26 }}
{ "term": { "date": "2014-09-01" }}
{ "term": { "public": true }}
{ "term": { "tag": "full_text" }}
Java代碼:
QueryBuilder ageBuilder = QueryBuilders.termQuery("age", "10");
和term有點類似,可以允許指定多個匹配條件。如果指定了多個條件,文檔會去匹配多個條件,多個條件直接用or連接。以下表示查詢title中包含內容dog或jumps的記錄
{
"terms": {
"title": [ "dog", "jumps" ]
}
}
等效於:
"bool" : {
"should" : [ {
"term" : {
"title" : "dog"
}
}, {
"term" : {
"title" : "jumps"
}
} ]
}
Java代碼:
QueryBuilder builder = QueryBuilders.termsQuery("title", "dog", "jumps");
// 與termsQuery等效
builder = QueryBuilders.boolQuery().should(QueryBuilders.termQuery("title", "dog")).should(QueryBuilders.termQuery("title", "jumps"));
允許我們按照指定范圍查找一批數據。數值、字符串、日期等
數值:
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
日期:
"range" : {
"timestamp" : {
"gt" : "2014-01-01 00:00:00",
"lt" : "2014-01-07 00:00:00"
}
}
當用於日期字段時,range 過濾器支持日期數學操作。例如,我們想找到所有最近一個小時的文檔:
"range" : {
"timestamp" : {
"gt" : "now-1h"
}
}
日期計算也能用於實際的日期,而不是僅僅是一個像 now 一樣的占位符。只要在日期後加上雙豎線 ||,就能使用日期數學表達式了。
"range" : {
"timestamp" : {
"gt" : "2014-01-01 00:00:00",
"lt" : "2014-01-01 00:00:00||+1M" <1>
}
}
<1> 早於 2014 年 1 月 1 號加一個月
范圍操作符包含:
gt :: 大於
gte:: 大於等於
lt :: 小於
lte:: 小於等於
Java代碼:
QueryBuilders.rangeQuery("age").gte(18).lt(20);
過濾字符串時,字符串訪問根據字典或字母順序來計算。例如,這些值按照字典順序排序:
5, 50, 6, B, C, a, ab, abb, abc, b
Tip: 使用range過濾/查找時,數字和日期字段的索引方式讓他們在計算范圍時十分高效。但對於字符串來說卻不是這樣。為了在字符串上執行范圍操作,Elasticsearch 會在這個范圍內的每個短語執行 term 操作。這比日期或數字的范圍操作慢得多。
+
字符串范圍適用於一個基數較小的字段,一個唯一短語個數較少的字段。你的唯一短語數越多,搜索就越慢。
exists和missing過濾可以用於查找文檔中是否包含指定字段或沒有某個字段,類似於SQL語句中的is not null和is null條件
目前es不推薦使用missing過濾, 使用bool.mustNot + exists來替代
{
"exists": {
"field": "title"
}
}
{
"missing": {
"field": "title"
}
}
"bool" : {
"must_not" : {
"exists" : {
"field" : "title"
}
}
}
Java代碼:
// exits
QueryBuilder builder = QueryBuilders.existsQuery("title");
// missing
builder = QueryBuilders.missingQuery("title");
// instead of missing
builder = QueryBuilders.boolQuery().mustNot(QueryBuilders.existsQuery("title"));
match_all用於查詢所有內容,沒有指定查詢條件
{
"match_all": {}
}
常用與合並過濾或查詢結果。
match查詢是一個標准查詢,全文查詢或精確查詢都可以用到他
如果你使用 match 查詢一個全文本字段,它會在真正查詢之前用分析器先分析match一下查詢字符。使用match查詢字符串時,查詢關鍵字和查詢目標均會進行分析(和指定的分詞器有關),指定not_analyzed除外。
{
"match": {
"tweet": "About Search"
}
}
如果用match下指定了一個確切值,在遇到數字,日期,布爾值或者not_analyzed 的字符串時,它將為你搜索你給定的值:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}
match參數type、operator、minimum_should_match壽命
type取值
boolean: 分析後進行查詢
phrase: 確切的匹配若干個單詞或短語, 如title: “brown dog”, 則查詢title中包含brown和dog, 且兩個是連接在一起的
phrase_prefix: 和phrase類似,最後一個搜索詞(term)會進行前面部分匹配
官網解釋:The match_phrase_prefix is the same as match_phrase, except that it allows for prefix matches on the last term in the text
operator取值
and: “brown dog”, 包含brown且包含dog
or: “brown dog”, 包含brown或dog
minimum_should_match:取值為整數或者百分數,用於精度控制。如取4,表示需要匹配4個關鍵字,50%,需要匹配一半的關鍵字。設置minimum_should_match時operator將失效
"match" : {
"title" : {
"query" : "BROWN DOG",
"type" : "boolean",
"operator" : "OR",
"minimum_should_match" : "50%"
}
}
multi_match查詢允許你做match查詢的基礎上同時搜索多個字段:
{
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
}
tip:
1. 查詢字符串時,match與term的區別
term查找時內容精確匹配,match則會進行分
析器處理,分析器中的分詞器會將搜索關鍵字分割成單獨的詞(terms)或者標記(tokens)
eg. 查詢title包含Jumps的內容, 用示例數據時,term匹配不到結果,但match會轉化成jumps匹配,然後查找到結果。和使用的分析器有關,筆者使用的是自帶的標准分析器
http://localhost:9200/my_index/_analyze?pretty=true&field=title&text=Jumps
{
"tokens" : [ {
"token" : "jumps",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
} ]
}
Java代碼:
QueryBuilder builder = QueryBuilders.matchAllQuery();
builder = QueryBuilders.matchQuery("title", "Jumps");
builder = QueryBuilders.matchQuery("title", "BROWN DOG!").operator(MatchQueryBuilder.Operator.OR).type(MatchQueryBuilder.Type.BOOLEAN);
builder = QueryBuilders.multiMatchQuery("title", "dog", "jump");
本篇暫不介紹
和數據庫中order by類似
"sort": { "date": { "order": "desc" }}
Java代碼:
SearchRequestBuilder requestBuilder =
client.prepareSearch("my_index").setTypes("my_type")
.setFrom(0).setSize(10)
.addSort("age", SortOrder.DESC);
scroll 類似於數據庫裡面的游標,用於緩存大量結果數據
一個search請求只能返回結果的一個單頁(10條記錄),而scroll API能夠用來從一個單一的search請求中檢索大量的結果(甚至全部)
,這種行為就像你在一個傳統數據庫內使用一個游標一樣。
scrolling目的不是為了實時的用戶請求,而是為了處理大量數據。
官網解釋(https://www.elastic.co/guide/en/elasticsearch/reference/2.3/search-request-scroll.html):
While a search request returns a single “page” of results, the scroll API can be used to retrieve large numbers of results (or even all results) from a single search request, in much the same way as you would use a cursor on a traditional database.
Scrolling is not intended for real time user requests, but rather for processing large amounts of data, e.g. in order to reindex the contents of one index into a new index with a different configuration.
通過scroll檢索數據時,每次會返回一個scroll_id,檢索下一批數據時,這個id必需要傳遞到scroll API
Client client = ConnectionUtil.getLocalClient();
SearchRequestBuilder requestBuilder = client.prepareSearch("my_index").setTypes("my_type")
.setScroll(new TimeValue(20000)) // 設置scroll有效時間
.setSize(2);
System.out.println(requestBuilder);
SearchResponse scrollResp = requestBuilder.get();
System.out.println("totalHits:" + scrollResp.getHits().getTotalHits());
while (true) {
String scrollId = scrollResp.getScrollId();
System.out.println("scrollId:" + scrollId);
SearchHits searchHits = scrollResp.getHits();
for (SearchHit hit : searchHits.getHits()) {
System.out.println(hit.getId() + "~" + hit.getSourceAsString());
}
System.out.println("=================");
// 3. 通過scrollId獲取後續數據
scrollResp = client.prepareSearchScroll(scrollId)
.setScroll(new TimeValue(20000)).execute().actionGet();
if (scrollResp.getHits().getHits().length == 0) {
break;
}
}
bool: 組合查詢, 包含must, must not, should
搜索關鍵字的權重
上面介紹查詢/過濾關鍵子時多次提到bool,我們現在介紹bool
bool 可以用來合並多個條件,bool可以嵌套bool,已用於組成復雜的查詢條件,它包含以下操作符:
must :: 多個查詢條件的完全匹配,相當於 and。
must_not :: 多個查詢條件的相反匹配,相當於 not。
should :: 至少有一個查詢條件匹配, 相當於 or。
這些參數可以分別繼承一個條件或者一個條件的數組:
{
"bool": {
"must": { "term": { "folder": "inbox" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "term": { "starred": true }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
tip: bool下面,must、must_not、should至少需存在一個
Java代碼:
// (price = 20 OR productID = "1234") AND (price != 30)
QueryBuilder queryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.termQuery("price", "20"))
.should(QueryBuilders.termQuery("productId", "1234"))
.mustNot(QueryBuilders.termQuery("price", "30"));
假設我們想搜索包含”full-text search”的文檔,但想給包含“Elasticsearch”或者“Lucene”的文檔更高的權重。即包含“Elasticsearch”或者“Lucene”的相關性評分比不包含的高,這些文檔在結果文檔中更靠前。
一個簡單的bool查詢允許我們寫出像下面一樣的非常復雜的邏輯:
"bool": {
"must": {
"match": {
"content": { (1)
"query": "full text search",
"operator": "and"
}
}
},
"should": [ (2)
{ "match": { "content": "Elasticsearch" }},
{ "match": { "content": "Lucene" }}
]
}
content字段必須包含full,text,search這三個單詞。
如果content字段也包含了“Elasticsearch”或者“Lucene”,則文檔會有一個更高的得分。
在上例中,如果想給包含”Elasticsearch”一詞的文檔得分更高於”Lucene”,則可以指定一個boost值控制權重,該值默認為1。一個大於1的boost值可以提高查詢子句的相對權重。
"bool": {
"must": {
"match": { (1)
"content": {
"query": "full text search",
"operator": "and"
}
}
},
"should": [
{ "match": {
"content": {
"query": "Elasticsearch",
"boost": 3 (2)
}
}},
{ "match": {
"content": {
"query": "Lucene",
"boost": 2 (3)
}
}}
]
}
這些查詢子句的boost值為默認值1。
這個子句是最重要的,因為他有最高的boost值。
這個子句比第一個查詢子句的要重要,但是沒有“Elasticsearch”子句重要。
Java代碼:
QueryBuilders.matchQuery("title", "Dog").boost(3);
部分內容摘錄於:http://es.xiaoleilu.com/ 第12、13章
附:測試類完整Java代碼
package cn.com.axin.elasticsearch.qwzn.share;
import java.net.UnknownHostException;
import org.elasticsearch.action.search.SearchRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortOrder;
import cn.com.axin.elasticsearch.util.ConnectionUtil;
import cn.com.axin.elasticsearch.util.Log;
/**
* @Title
*
* @author
* @date 2016-8-11
*/
public class Search {
public static void main(String[] args) throws Exception {
// searchAll();
// execQuery(termSearch());
// execQuery(termsSearch());
// execQuery(rangeSearch());
// execQuery(existsSearch());
// execQuery(matchSearch());
execQuery(boolSearch());
// highlightedSearch();
// scorll();
//
}
/**
* @return
*/
private static QueryBuilder boolSearch() {
// age > 30 or last_name is Smith
QueryBuilder queryBuilder = QueryBuilders.boolQuery()
.should(QueryBuilders.rangeQuery("age").gt("30"))
.should(QueryBuilders.matchQuery("last_name", "Smith"));
// 挺高查詢權重
// QueryBuilders.matchQuery("title", "Dog").boost(3);
// QueryBuilders.boolQuery().must(null);
// QueryBuilders.boolQuery().mustNot(null);
return queryBuilder;
}
private static void scorll() {
Client client = null;
try {
client = ConnectionUtil.getLocalClient(); // 獲取Client連接對象
SearchRequestBuilder requestBuilder = client.prepareSearch("my_index").setTypes("my_type")
// .setQuery(QueryBuilders.termQuery("age", "20"))
.setScroll(new TimeValue(20000)) // 設置scroll有效時間
.setSize(2);
System.out.println(requestBuilder);
SearchResponse scrollResp = requestBuilder.get();
System.out.println("totalHits:" + scrollResp.getHits().getTotalHits());
while (true) {
String scrollId = scrollResp.getScrollId();
System.out.println("scrollId:" + scrollId);
SearchHits searchHits = scrollResp.getHits();
for (SearchHit hit : searchHits.getHits()) {
System.out.println(hit.getId() + "~" + hit.getSourceAsString());
}
System.out.println("=================");
// 3. 通過scrollId獲取後續數據
scrollResp = client.prepareSearchScroll(scrollId)
.setScroll(new TimeValue(20000)).execute().actionGet();
if (scrollResp.getHits().getHits().length == 0) {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != client) {
client.close();
}
}
}
/**
* @return
*/
private static void highlightedSearch() {
QueryBuilder builder = QueryBuilders.termsQuery("age", "18");
Client client = null;
try {
client = ConnectionUtil.getLocalClient();
SearchRequestBuilder requestBuilder =
client.prepareSearch("my_index").setTypes("my_type")
.setFrom(0).setSize(10)
.addHighlightedField("age");
// .addSort("age", SortOrder.DESC);
Log.debug(requestBuilder);
SearchResponse response = requestBuilder.get();
Log.debug(response);
} catch (UnknownHostException e) {
e.printStackTrace();
} finally {
if (null != client) {
client.close();
}
}
}
/**
* @return
*/
private static QueryBuilder matchSearch() {
QueryBuilder builder = QueryBuilders.matchAllQuery();
builder = QueryBuilders.matchQuery("title", "Jumps");
/*
type: boolean 分析後進行查詢
phrase: 確切的匹配若干個單詞或短語,
phrase_prefix: The match_phrase_prefix is the same as match_phrase,
except that it allows for prefix matches on the last term in the text
*/
builder = QueryBuilders.matchQuery("title", "BROWN DOG!").operator(MatchQueryBuilder.Operator.OR).type(MatchQueryBuilder.Type.BOOLEAN);
builder = QueryBuilders.multiMatchQuery("title", "dog", "jump");
return builder;
}
/**
* @return
*/
private static QueryBuilder existsSearch() {
// exits
QueryBuilder builder = QueryBuilders.existsQuery("title");
// missing
builder = QueryBuilders.missingQuery("title");
// instead of missing
builder = QueryBuilders.boolQuery().mustNot(QueryBuilders.existsQuery("title"));
return builder;
}
/**
*
*/
private static QueryBuilder rangeSearch() {
// age >= 18 && age < 20
return QueryBuilders.rangeQuery("age").gte(18).lt(20);
}
private static QueryBuilder termSearch(){
QueryBuilder builder = QueryBuilders.termsQuery("title", "brown");
return builder;
}
private static QueryBuilder termsSearch(){
QueryBuilder builder = QueryBuilders.termsQuery("title", "dog", "jumps");
// 與termsQuery等效
builder = QueryBuilders.boolQuery().should(QueryBuilders.termQuery("title", "dog")).should(QueryBuilders.termQuery("title", "jumps"));
return builder;
}
private static void searchAll() {
Client client = null;
try {
client = ConnectionUtil.getLocalClient();
SearchRequestBuilder requestBuilder =
client.prepareSearch("my_index").setTypes("my_type")
.setFrom(0).setSize(10)
.addSort("age", SortOrder.DESC);
Log.debug(requestBuilder);
SearchResponse response = requestBuilder.get();
Log.debug(response);
} catch (UnknownHostException e) {
e.printStackTrace();
} finally {
if (null != client) {
client.close();
}
}
}
/**
* @param builder
* @throws UnknownHostException
*/
private static void execQuery(QueryBuilder builder)
throws UnknownHostException {
Client client = ConnectionUtil.getLocalClient();
SearchRequestBuilder requestBuilder =
client.prepareSearch("my_index").setTypes("my_type")
.setExplain(true)
.setQuery(builder);
Log.debug(requestBuilder);
SearchResponse response = requestBuilder.get();
Log.debug(response);
}
}
獲取連接對象的代碼
/**
* 獲取本地的連接對象(127.0.0.1:9300)
* @return
* @throws UnknownHostException
*/
public static Client getLocalClient() throws UnknownHostException {
return getClient("127.0.0.1", 9300, "es-stu");
}
/**
* 獲取連接對象
* @param host 主機IP
* @param port 端口
* @param clusterName TODO
* @return
* @throws UnknownHostException
*/
private static Client getClient(String host, int port, String clusterName) throws UnknownHostException {
// 參數設置
Builder builder = Settings.settingsBuilder();
// 啟用嗅探功能 sniff
builder.put("client.transport.sniff", true);
// 集群名
builder.put("cluster.name", clusterName);
Settings settings = builder.build();
TransportClient transportClient = TransportClient.builder().settings(settings).build();
Client client = transportClient.addTransportAddress(
new InetSocketTransportAddress(InetAddress.getByName(host), port));
// 連接多個地址
// transportClient.addTransportAddresses(transportAddress);
return client;
}
 Android studio創建第一個app
Android studio創建第一個app
本文實例為大家介紹了Android studio創建第一個app的詳細步驟,供大家參考,具體內容如下1.創建HelloWorld項目任何編程語言寫出的第一個程序毫無疑問都
 Android FM模塊學習之一 FM啟動流程
Android FM模塊學習之一 FM啟動流程
最近在學習FM模塊,FM是一個值得學習的模塊,可以從上層看到底層。上層就是FM的按扭操作和界面顯示,從而調用到FM底層驅動來實現廣播收聽的功能。 看看
 Android字體大小怎麼自適應不同分辨率?
Android字體大小怎麼自適應不同分辨率?
今天有人問我,android系統不同分辨率,不同大小的手機,字體大小怎麼去適應呢?其實字體的適應和圖片的適應是一個道理的。 一、 原理如下: 假設需要適應320x240,
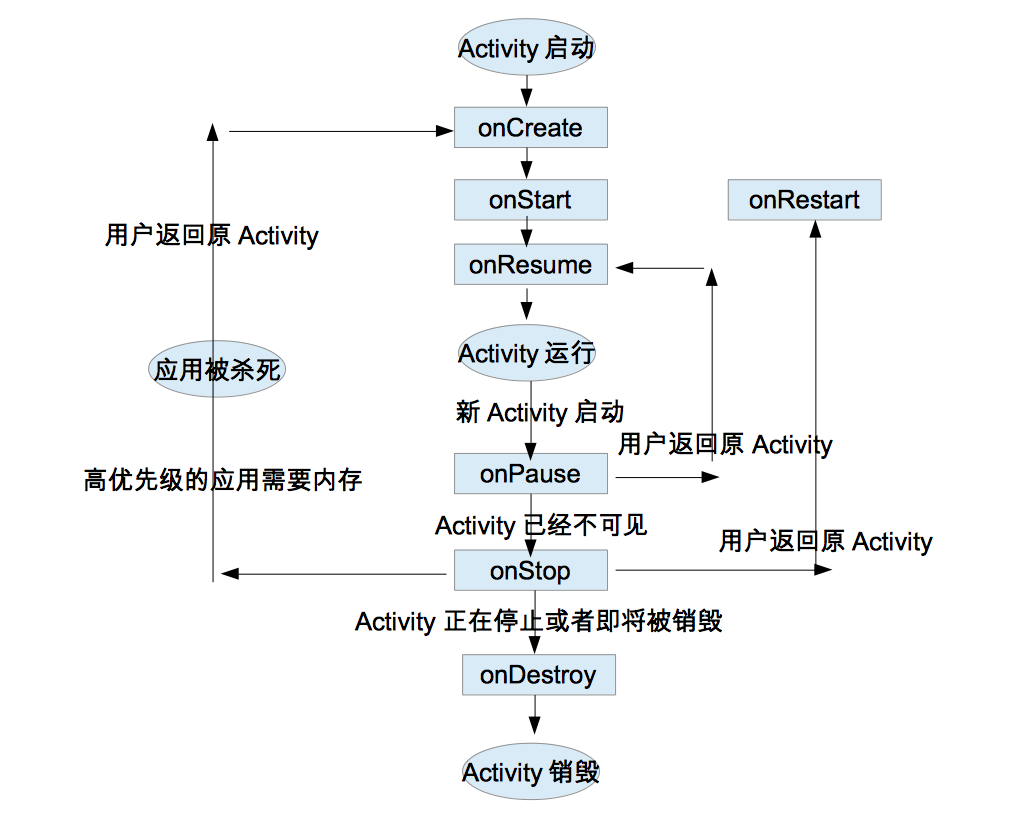 Android開發藝術探索——第一章:Activity的生命周期和啟動模式
Android開發藝術探索——第一章:Activity的生命周期和啟動模式
懷著無比崇敬的心情翻開了這本書,路漫漫其修遠兮,程序人生,為自己加油!一.序作為這本書的第一章,主席還是把Activity搬上來了,也確實,和Activity打交道的次數