編輯:關於Android編程
#coding=utf-8
#---------------------------------------
# 程序:androidbenchmark爬蟲
# 作者:ewang
# 日期:2016-7-11
# 語言:Python 2.7
# 功能:獲取頁面中的Android PassMark Rating信息保存到文件中。
#---------------------------------------
import string
import urllib2
import re
import os
class androidbenchmark_Spider:
#申明相關屬性
def __init__(self,url):
#給SougoPicUrl屬性賦值
self.androidbenchmarkUrl=url
#用來保存圖片URL信息
self.androidbenchmark=[]
print u'爬蟲,爬爬...'
#初始化加載頁面並將其轉碼存儲
def AndroidBenchMark(self):
#讀取頁面的原始信息
Page=urllib2.urlopen(self.androidbenchmarkUrl).read()
#獲取頁面標題
title=self.find_title(Page)
print u'網頁名稱:'+title
#獲取頁面中文本信息
self.save_infor(title)
#查找頁面標題
def find_title(self,page):
#匹配<title>xxxx</title>
myTitle=re.search(r'<title>(.*?)</title>',page,re.S)
#初始化標題名為暫無標題
title=u'暫無標題'
#如果標題存在把標題賦值給title
if myTitle:
#(.*?)這稱作一個group,組是從1開始
title=myTitle.group(1)
else:
print u'爬蟲報告:無法加載網頁標題...'
return title
#保存頁面信息
def save_infor(self,title):
#加載頁面文本信息到數組中
self.get_infor()
#創建並打開本地文件
f=open(title+'.csv','w+')
#把獲取的頁面信息寫入文件中
f.writelines(self.androidbenchmark)
#關閉打開的文件
f.close()
print u'爬蟲報告:文件'+title+'.csv'+u'已經下載:'+os.getcwd()
print u'按任意鍵退出...'
raw_input()
#獲取頁面源碼並將其存儲到數組中
def get_infor(self):
#獲取頁面中的源碼
page=urllib2.urlopen(self.androidbenchmarkUrl).read()
#把頁面中所有jpg圖片的URL提取出來
self.deal_Android_Device(page)
def deal_Android_Device(self,page):
#獲取所有設備名稱
Android_Device=re.findall('\<a href=\"phone\.php\?phone=(.*?)\"\>',page,re.S)
#把手機型號的添加到androidbenchmark列表中
for aItem in Android_Device:
self.androidbenchmark.append(aItem+"\n")
#------------程序入口處----------------
print u"""#---------------------------------------
# 程序:程序:androidbenchmark爬蟲
# 作者:ewang
# 日期:2016-7-7
# 語言:Python 2.7
# 功能:獲取頁面中的Android PassMark Rating信息保存到文件中。
#--------------------------------------------------
"""
#print u'需要爬取得URL(passmark_chart,memmark_chart,cpumark_chart,diskmark_chart,g2dmark_chart,g3dmark_chart):'
#bdurl = 'http://www.androidbenchmark.net/' + str(raw_input(u'http://www.androidbenchmark.net/')) +'.html'
And_ipone=['http://www.androidbenchmark.net/','http://www.iphonebenchmark.net/']
chart_page=['passmark_chart.html','memmark_chart.html','cpumark_chart.html','diskmark_chart.html','g2dmark_chart.html','g3dmark_chart.html']
for dev in And_ipone:
for chart in chart_page:
bdurl=dev+chart
Android_Device_Name=androidbenchmark_Spider(bdurl)
Android_Device_Name.AndroidBenchMark()
#coding=utf-8
#---------------------------------------
# 程序:androidbenchmark爬蟲
# 作者:ewang
# 日期:2016-7-11
# 語言:Python 2.7
# 功能:獲取頁面中的Android PassMark Rating信息保存到文件中。
#---------------------------------------
import string
import urllib2
import re
import os
class androidbenchmark_Spider:
#申明相關屬性
def __init__(self,url):
#給SougoPicUrl屬性賦值
self.androidbenchmarkUrl=url
#用來保存圖片URL信息
self.androidbenchmark=[]
print u'爬蟲,爬爬...'
#初始化加載頁面並將其轉碼存儲
def AndroidBenchMark(self):
#讀取頁面的原始信息
Page=urllib2.urlopen(self.androidbenchmarkUrl).read()
#獲取頁面標題
title=self.find_title(Page)
print u'網頁名稱:'+title
#獲取頁面中文本信息
self.save_infor(title)
#查找頁面標題
def find_title(self,page):
#匹配<title>xxxx</title>
myTitle=re.search(r'<title>(.*?)</title>',page,re.S)
#初始化標題名為暫無標題
title=u'暫無標題'
#如果標題存在把標題賦值給title
if myTitle:
#(.*?)這稱作一個group,組是從1開始
title=myTitle.group(1)
else:
print u'爬蟲報告:無法加載網頁標題...'
return title
#保存頁面信息
def save_infor(self,title):
#加載頁面文本信息到數組中
self.get_infor()
#創建並打開本地文件
f=open(title+'.csv','w+')
#把獲取的頁面信息寫入文件中
f.writelines(self.androidbenchmark)
#關閉打開的文件
f.close()
print u'爬蟲報告:文件'+title+'.csv'+u'已經下載:'+os.getcwd()
print u'按任意鍵退出...'
raw_input()
#獲取頁面源碼並將其存儲到數組中
def get_infor(self):
#獲取頁面中的源碼
page=urllib2.urlopen(self.androidbenchmarkUrl).read()
#把頁面中所有jpg圖片的URL提取出來
self.deal_Android_Device(page)
def deal_Android_Device(self,page):
#獲取所有設備名稱
Android_Device=re.findall('\<a href=\"phone\.php\?phone=(.*?)\"\>',page,re.S)
#把手機型號的添加到androidbenchmark列表中
for aItem in Android_Device:
self.androidbenchmark.append(aItem+"\n")
#------------程序入口處----------------
print u"""#---------------------------------------
# 程序:程序:androidbenchmark爬蟲
# 作者:ewang
# 日期:2016-7-7
# 語言:Python 2.7
# 功能:獲取頁面中的Android PassMark Rating信息保存到文件中。
#--------------------------------------------------
"""
print u'需要爬取得URL(passmark_chart,memmark_chart,cpumark_chart,diskmark_chart,g2dmark_chart,g3dmark_chart):'
bdurl = 'http://www.androidbenchmark.net/' + str(raw_input(u'http://www.androidbenchmark.net/')) +'.html'
Android_Device_Name=androidbenchmark_Spider(bdurl)
Android_Device_Name.AndroidBenchMark()
#coding=utf-8
#---------------------------------------
# 程序:androidbenchmark爬蟲
# 作者:ewang
# 日期:2016-7-11
# 語言:Python 2.7
# 功能:獲取頁面中的Android PassMark Rating信息保存到文件中。
#---------------------------------------
import string
import urllib2
import re
import os
class androidbenchmark_Spider:
#申明相關屬性
def __init__(self,url):
#給SougoPicUrl屬性賦值
self.androidbenchmarkUrl=url
#用來保存圖片URL信息
self.androidbenchmark=[]
print u'爬蟲,爬爬...'
#初始化加載頁面並將其轉碼存儲
def AndroidBenchMark(self):
#讀取頁面的原始信息
Page=urllib2.urlopen(self.androidbenchmarkUrl).read()
#獲取頁面標題
title=self.find_title(Page)
print u'網頁名稱:'+title
#獲取頁面中文本信息
self.save_infor(title)
#查找頁面標題
def find_title(self,page):
#匹配<title>xxxx</title>
myTitle=re.search(r'<title>(.*?)</title>',page,re.S)
#初始化標題名為暫無標題
title=u'暫無標題'
#如果標題存在把標題賦值給title
if myTitle:
#(.*?)這稱作一個group,組是從1開始
title=myTitle.group(1)
else:
print u'爬蟲報告:無法加載網頁標題...'
return title
#保存頁面信息
def save_infor(self,title):
#加載頁面文本信息到數組中
self.get_infor()
#創建並打開本地文件
f=open(title+'.csv','w+')
#把獲取的頁面信息寫入文件中
f.writelines(self.androidbenchmark)
#關閉打開的文件
f.close()
print u'爬蟲報告:文件'+title+'.csv'+u'已經下載:'+os.getcwd()
print u'按任意鍵退出...'
raw_input()
#獲取頁面源碼並將其存儲到數組中
def get_infor(self):
#獲取頁面中的源碼
page=urllib2.urlopen(self.androidbenchmarkUrl).read()
#把頁面中所有jpg圖片的URL提取出來
self.deal_Android_Device(page)
def deal_Android_Device(self,page):
#獲取所有設備名稱
Android_Device=re.findall('\<a href=\"phone\.php\?phone=(.*?)\"\>',page,re.S)
#把手機型號的添加到androidbenchmark列表中
for aItem in Android_Device:
self.androidbenchmark.append(aItem+"\n")
#------------程序入口處----------------
print u"""#---------------------------------------
# 程序:程序:androidbenchmark爬蟲
# 作者:ewang
# 日期:2016-7-7
# 語言:Python 2.7
# 功能:獲取頁面中的Android PassMark Rating信息保存到文件中。
#--------------------------------------------------
"""
print u'需要爬取得URL(passmark_chart,memmark_chart,cpumark_chart,diskmark_chart,g2dmark_chart,g3dmark_chart):'
bdurl = 'http://www.androidbenchmark.net/' + str(raw_input(u'http://www.androidbenchmark.net/')) +'.html'
Android_Device_Name=androidbenchmark_Spider(bdurl)
Android_Device_Name.AndroidBenchMark()
#coding=utf-8
#---------------------------------------
# 程序:iphonebenchmark爬蟲
# 作者:ewang
# 日期:2016-7-11
# 語言:Python 2.7
# 功能:獲取頁面中的iphone PassMark Rating信息保存到文件中。
#---------------------------------------
import string
import urllib2
import re
import os
class iphonebenchmark_Spider:
#申明相關屬性
def __init__(self,url):
#給SougoPicUrl屬性賦值
self.iphonebenchmarkUrl=url
#用來保存圖片URL信息
self.iphonebenchmark=[]
print u'爬蟲,爬爬...'
#初始化加載頁面並將其轉碼存儲
def iphoneBenchMark(self):
#讀取頁面的原始信息
Page=urllib2.urlopen(self.iphonebenchmarkUrl).read()
#獲取頁面標題
title=self.find_title(Page)
print u'網頁名稱:'+title
#獲取頁面中文本信息
self.save_infor(title)
#查找頁面標題
def find_title(self,page):
#匹配<title>xxxx</title>
myTitle=re.search(r'<title>(.*?)</title>',page,re.S)
#初始化標題名為暫無標題
title=u'暫無標題'
#如果標題存在把標題賦值給title
if myTitle:
#(.*?)這稱作一個group,組是從1開始
title=myTitle.group(1)
else:
print u'爬蟲報告:無法加載網頁標題...'
return title
#保存頁面信息
def save_infor(self,title):
#加載頁面文本信息到數組中
self.get_infor()
#創建並打開本地文件
f=open(title+'.csv','w+')
#把獲取的頁面信息寫入文件中
f.writelines(self.iphonebenchmark)
#關閉打開的文件
f.close()
print u'爬蟲報告:文件'+title+'.csv'+u'已經下載:'+os.getcwd()
print u'按任意鍵退出...'
raw_input()
#獲取頁面源碼並將其存儲到數組中
def get_infor(self):
#獲取頁面中的源碼
page=urllib2.urlopen(self.iphonebenchmarkUrl).read()
#把頁面中所有jpg圖片的URL提取出來
self.deal_iphone_Device(page)
def deal_iphone_Device(self,page):
#獲取所有設備名稱
iphone_Device=re.findall('\<a href=\"phone\.php\?phone=(.*?)\"\>',page,re.S)
#把手機型號的添加到iphonebenchmark列表中
for aItem in iphone_Device:
self.iphonebenchmark.append(aItem+"\n")
#------------程序入口處----------------
print u"""#---------------------------------------
# 程序:程序:iphonebenchmark爬蟲
# 作者:ewang
# 日期:2016-7-7
# 語言:Python 2.7
# 功能:獲取頁面中的iphone PassMark Rating信息保存到文件中。
#--------------------------------------------------
"""
print u'需要爬取得URL(passmark_chart,memmark_chart,cpumark_chart,diskmark_chart,g2dmark_chart,g3dmark_chart):'
bdurl = 'http://www.iphonebenchmark.net/' + str(raw_input(u'http://www.iphonebenchmark.net/')) +'.html'
iphone_Device_Name=iphonebenchmark_Spider(bdurl)
iphone_Device_Name.iphoneBenchMark()
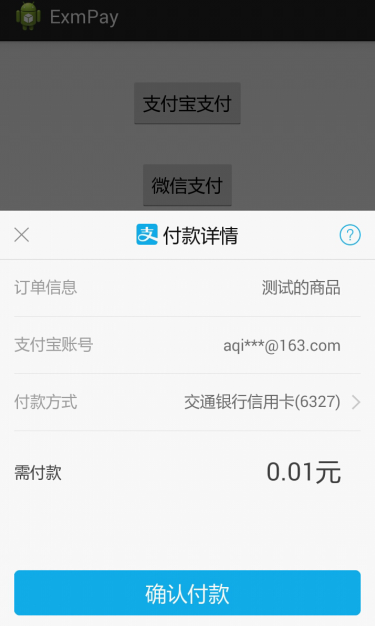 Android開發筆記(一百零六)支付繳費SDK
Android開發筆記(一百零六)支付繳費SDK
第三方支付第三方支付指的是第三方平台與各銀行簽約,在買方與賣方之間實現中介擔保,從而增強了支付交易的安全性。國內常用的支付平台主要是支付寶和微信支付,其中支付寶的市場份額
 ReactNative實現ListView分組,懸浮效果
ReactNative實現ListView分組,懸浮效果
實現效果其實在ReactNative中實現ListView的分組效果的方式與Android中的ExpandableListview非常相似,只是在表現形式上更趨近於IOS
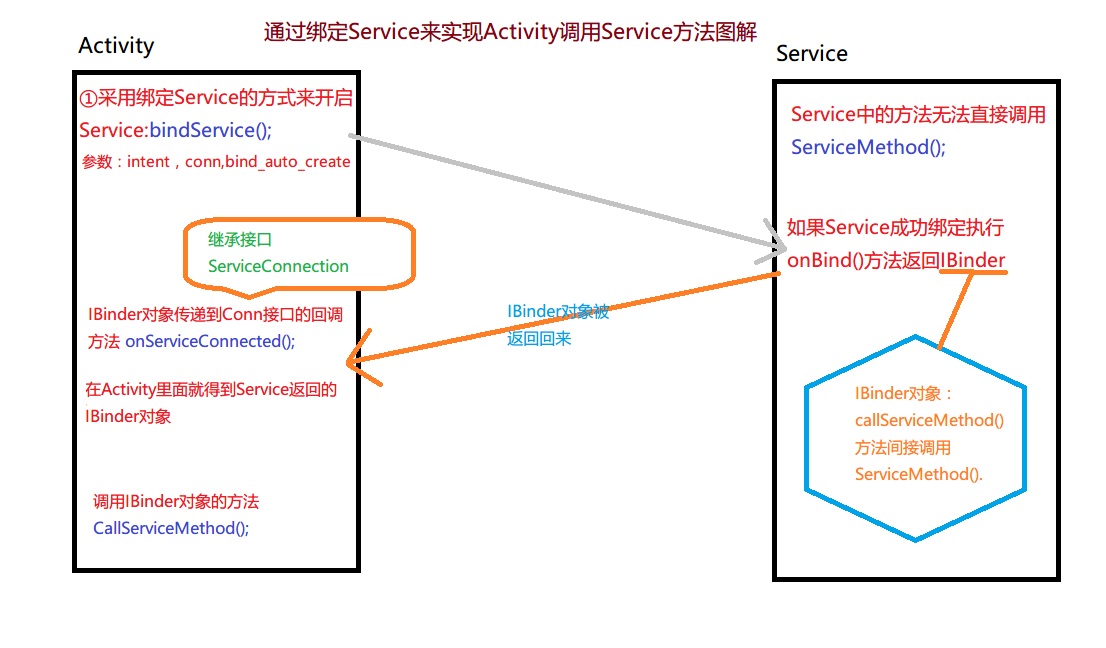 Android IPC機制綁定Service實現本地通信
Android IPC機制綁定Service實現本地通信
**寫作原因:跨進程通信的實現和理解是Android進階中重要的一環。下面博主分享IPC一些相關知識、操作及自己在學習IPC過程中的一些理解。 這一章是為下面的Messe
 從零開始學android(GridView網格視圖.二十八.)
從零開始學android(GridView網格視圖.二十八.)
GridView組件是以網格的形式顯示所有的組件,例如:在制作相冊的時候,所有的圖片都會以相同大小顯示在不同的格子之中,就可以依靠此組件完成,