編輯:關於Android編程
 Jsoup的資料比較少,可供參考的可到其官網進行學習這個庫的使用:http://www.open-Z喎?/kf/ware/vc/" target="_blank" class="keylink">vcGVuLmNvbS9qc291cC8JQVBJsunUxLXY1rejumh0dHA6Ly9qc291cC5vcmcvYXBpZG9jcy8JPGJyIC8+CQkJttTV4rj2v+K1xMq508OxytXf0rKyu8rHt8ezo8rsz6SjrL7N1rvKx7zytaWyzr+8wcvOxLW1tvjN6rPJwcu94s72uaTX96Osy/nS1M/Cw+a1xLHK1d+1xL3izva0+sLr0rLWu8rHzOG5qbLOv7yjrL7fzOW1xL3izva3vbeoo6zH68jP1eay6b+0YXBpzsS1taGjCcjnus7KudPDSnNvdXDV4rj2v+Kyu8rH1ti146Os1ti148rHyOe6zrbUztLDx8/rveLO9rXEzfjSs7340NC31s72o6zI57rO1/a1vc/x0tTPwrXE0Ke5+6O6CTxpbWcgc3JjPQ=="/uploadfile/Collfiles/20141002/20141002090903136.png" alt="\" />
Jsoup的資料比較少,可供參考的可到其官網進行學習這個庫的使用:http://www.open-Z喎?/kf/ware/vc/" target="_blank" class="keylink">vcGVuLmNvbS9qc291cC8JQVBJsunUxLXY1rejumh0dHA6Ly9qc291cC5vcmcvYXBpZG9jcy8JPGJyIC8+CQkJttTV4rj2v+K1xMq508OxytXf0rKyu8rHt8ezo8rsz6SjrL7N1rvKx7zytaWyzr+8wcvOxLW1tvjN6rPJwcu94s72uaTX96Osy/nS1M/Cw+a1xLHK1d+1xL3izva0+sLr0rLWu8rHzOG5qbLOv7yjrL7fzOW1xL3izva3vbeoo6zH68jP1eay6b+0YXBpzsS1taGjCcjnus7KudPDSnNvdXDV4rj2v+Kyu8rH1ti146Os1ti148rHyOe6zrbUztLDx8/rveLO9rXEzfjSs7340NC31s72o6zI57rO1/a1vc/x0tTPwrXE0Ke5+6O6CTxpbWcgc3JjPQ=="/uploadfile/Collfiles/20141002/20141002090903136.png" alt="\" />
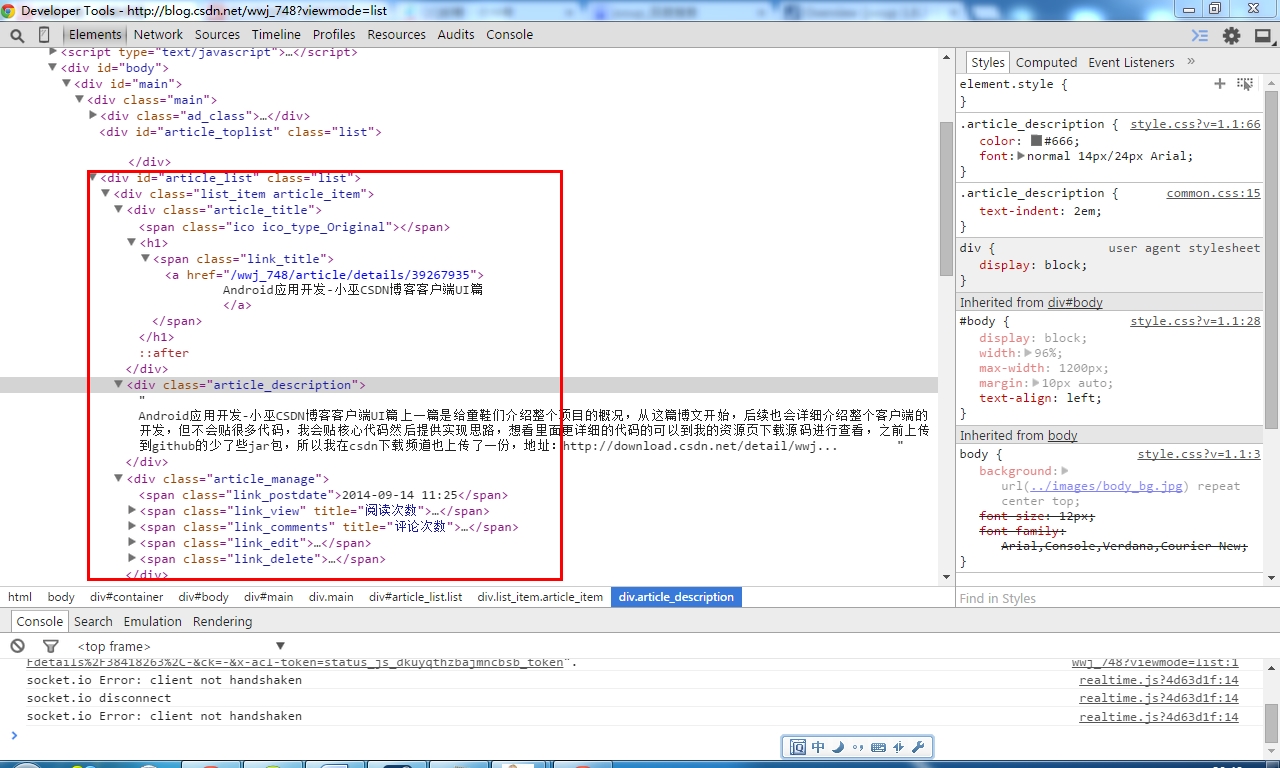 如果想解析一個網頁,還是得你自己以上面這種方式去看,找到你想要的內容。小巫是這樣做的,可以通過右鍵查看元素,直接查看對應的html源代碼,這樣你就知道內容對應的標簽是什麼了。因為小巫想獲得首頁的所有博文列表,所以我就找到博文的最外層的div標簽開始分析,我找到了id為article_list,然後接著找到了每條博文項的內容,確定下它們的具體的標簽,使用了什麼class,博客可以通過class來獲取你想要的元素,然後取得元素的內容。
如果想解析一個網頁,還是得你自己以上面這種方式去看,找到你想要的內容。小巫是這樣做的,可以通過右鍵查看元素,直接查看對應的html源代碼,這樣你就知道內容對應的標簽是什麼了。因為小巫想獲得首頁的所有博文列表,所以我就找到博文的最外層的div標簽開始分析,我找到了id為article_list,然後接著找到了每條博文項的內容,確定下它們的具體的標簽,使用了什麼class,博客可以通過class來獲取你想要的元素,然後取得元素的內容。/** * 使用Jsoup解析html文檔 * * @param blogType * @param str * @return */ public static ListgetBlogItemList(int blogType, String str) { // Log.e("URL---->", str); List list = new ArrayList (); // 獲取文檔對象 Document doc = Jsoup.parse(str); // Log.e("doc--->", doc.toString()); // 獲取class="article_item"的所有元素 Elements blogList = doc.getElementsByClass("article_item"); // Log.e("elements--->", blogList.toString()); for (Element blogItem : blogList) { BlogItem item = new BlogItem(); String title = blogItem.select("h1").text(); // 得到標題 // System.out.println("title----->" + title); String description = blogItem.select("div.article_description") .text(); // System.out.println("descrition--->" + description); String msg = blogItem.select("div.article_manage").text(); // System.out.println("msg--->" + msg); String date = blogItem.getElementsByClass("article_manage").get(0) .text(); // System.out.println("date--->" + date); String link = BLOG_URL + blogItem.select("h1").select("a").attr("href"); // System.out.println("link--->" + link); item.setTitle(title); item.setMsg(msg); item.setContent(description); item.setDate(date); item.setLink(link); item.setType(blogType); // 沒有圖片 item.setImgLink(null); list.add(item); } return list; }
/** * 扒取傳入url地址的博客詳細內容 * * @param url * @param str * @return */ public static ListgetContent(String url, String str) { List list = new ArrayList (); // 獲取文檔內容 Document doc = Jsoup.parse(str); // 獲取class="details"的元素 Element detail = doc.getElementsByClass("details").get(0); detail.select("script").remove(); // 刪除每個匹配元素的DOM。 // 獲取標題 Element title = detail.getElementsByClass("article_title").get(0); Blog blogTitle = new Blog(); blogTitle.setState(Constants.DEF_BLOG_ITEM_TYPE.TITLE); // 設置狀態 blogTitle.setContent(ToDBC(title.text())); // 設置標題內容 // 獲取文章內容 Element content = detail.select("div.article_content").get(0); // 獲取所有標簽為 0) { Elements imgs = c.getElementsByTag("img"); System.out.println("img"); for (Element img : imgs) { if (!img.attr("src").equals("")) { Blog blogImgs = new Blog(); // 大圖鏈接 if (!img.parent().attr("href").equals("")) { blogImgs.setImgLink(img.parent().attr("href")); System.out.println("href=" + img.parent().attr("href")); if (img.parent().parent().tagName().equals("p")) { // img.parent().parent().remove(); } img.parent().remove(); } blogImgs.setContent(img.attr("src")); blogImgs.setImgLink(img.attr("src")); System.out.println(blogImgs.getContent()); blogImgs.setState(Constants.DEF_BLOG_ITEM_TYPE.IMG); list.add(blogImgs); } } } c.select("img").remove(); // 獲取博客內容 Blog blogContent = new Blog(); blogContent.setState(Constants.DEF_BLOG_ITEM_TYPE.CONTENT); if (c.text().equals("")) { continue; } else if (c.children().size() == 1) { if (c.child(0).tagName().equals("bold") || c.child(0).tagName().equals("span")) { if (c.ownText().equals("")) { // 小標題,咖啡色 blogContent .setState(Constants.DEF_BLOG_ITEM_TYPE.BOLD_TITLE); } } } // 代碼 if (c.select("pre").attr("name").equals("code")) { blogContent.setState(Constants.DEF_BLOG_ITEM_TYPE.CODE); blogContent.setContent(ToDBC(c.outerHtml())); } else { blogContent.setContent(ToDBC(c.outerHtml())); } list.add(blogContent); } return list; }
/** * 獲取博文評論列表 * * @param str * json字符串 * @return */ public static ListgetBlogCommentList(String str, int pageIndex, int pageSize) { List list = new ArrayList (); try { // 創建一個json對象 JSONObject jsonObject = new JSONObject(str); JSONArray jsonArray = jsonObject.getJSONArray("list"); // 獲取json數組 int index = 0; int len = jsonArray.length(); BlogCommentActivity.commentCount = String.valueOf(len); // 評論條數 // 如果評論數大於20 if (len > 20) { index = (pageIndex * pageSize) - 20; } if (len < pageSize && pageIndex > 1) { return list; } if ((pageIndex * pageSize) < len) { len = pageIndex * pageSize; } for (int i = index; i < len; i++) { JSONObject item = jsonArray.getJSONObject(i); String commentId = item.getString("CommentId"); String content = item.getString("Content"); String username = item.getString("UserName"); String parentId = item.getString("ParentId"); String postTime = item.getString("PostTime"); String userface = item.getString("Userface"); Comment comment = new Comment(); comment.setCommentId(commentId); comment.setContent(content); comment.setUsername(username); comment.setParentId(parentId); comment.setPostTime(postTime); comment.setUserface(userface); if (parentId.equals("0")) { // 如果parentId為0的話,表示它是評論的topic comment.setType(Constants.DEF_COMMENT_TYPE.PARENT); } else { comment.setType(Constants.DEF_COMMENT_TYPE.CHILD); } list.add(comment); } } catch (JSONException e) { e.printStackTrace(); } return list; }
 最好的5個Android ORM框架
最好的5個Android ORM框架
在開發Android應用時,保存數據有這麼幾個方式, 一個是本地保存,一個是放在後台(提供API接口),還有一個是放在開放雲服務上(如 SyncAdapter 會是一個不
 CSAPP第二次實驗 bomb二進制炸彈的破解
CSAPP第二次實驗 bomb二進制炸彈的破解
一個類似於破解的初級實驗。用到的gdb的指令並不多,只是基礎的使用和內存查看的指令。考的大多是匯編代碼的熟練程度和分析能力。不過有幾個函數長的讓人吐血。本著不輕易爆炸的原
 詳解Android更改APP語言模式的實現過程
詳解Android更改APP語言模式的實現過程
一、效果圖二、描述更改Android項目中的語言,這個作用於只用於此APP,不會作用於整個系統三、解決方案(一)布局文件<LinearLayout xmlns:an
 Android 超高仿微信圖片選擇器 圖片該這麼加載
Android 超高仿微信圖片選擇器 圖片該這麼加載
1、概述 關於手機圖片加載器,在當今像素隨隨便便破千萬的時代,一張圖片占據的內存都相當可觀,作為高大尚程序猿的我們,有必要掌握圖片的壓縮,緩存等處理,以到達