編輯:關於Android編程
Fence是一種同步機制,在Android裡主要用於圖形系統中GraphicBuffer的同步。那它和已有同步機制相比有什麼特點呢?它主要被用來處理跨硬件的情況,尤其是CPU,GPU和HWC之間的同步,另外它還可以用於多個時間點之間的同步。GPU編程和純CPU編程一個很大的不同是它是異步的,也就是說當我們調用GL command返回時這條命令並不一定完成了,只是把這個命令放在本地的command buffer裡。具體什麼時候這條GL command被真正執行完畢CPU是不知道的,除非CPU使用glFinish()等待這些命令執行完,另外一種方法就是基於同步對象的Fence機制。下面舉個生產者把GraphicBuffer交給消費者的例子。如生產者是App中的renderer,消費者是SurfaceFlinger。GraphicBuffer的隊列放在緩沖隊列BufferQueue中。BufferQueue對App端的接口為IGraphicBufferProducer,實現類為Surface,對SurfaceFlinger端的接口為IGraphicBufferConsumer,實現類為SurfaceFlingerConsumer。BufferQueue中對每個GraphiBuffer都有BufferState標記著它的狀態:
這個狀態一定程度上說明了該GraphicBuffer的歸屬,但只指示了CPU裡的狀態,而GraphicBuffer的真正使用者是GPU。也就是說,當生產者把一個GraphicBuffer放入BufferQueue時,只是在CPU層面完成了歸屬的轉移。但GPU說不定還在用,如果還在用的話消費者是不能拿去合成的。這時候GraphicBuffer和生產消費者的關系就比較暧昧了,消費者對GraphicBuffer具有擁有權,但無使用權,它需要等一個信號,告訴它GPU用完了,消費者才真正擁有使用權。一個簡化的模型如下:
 vcv8yrGjrLvht6Kz9tDFusXWuMq+ttPB0Meww+a1xMP8we7S0cirsr/WtNDQzeqxz6Gjuq/K/WVnbENsaWVudFdhaXRTeW5jS0hSKCm/ycjDtffTw9Xf1+jI+7XItP3QxbrFt6LJ+qGjPGJyPgo8YnI+CtTatMu7+bSh1q7Jz6OsQW5kcm9pZLbUxuS9+NDQwcvAqdW5LUFORFJPSURfbmF0aXZlX2ZlbmNlX3N5bmMgIChodHRwOi8vd3d3Lmtocm9ub3Mub3JnL3JlZ2lzdHJ5L2VnbC9leHRlbnNpb25zL0FORFJPSUQvRUdMX0FORFJPSURfbmF0aXZlX2ZlbmNlX3N5bmMudHh0KaOs0MK808HLvdO/2mVnbER1cE5hdGl2ZUZlbmNlRkRBTkRST0lEKCmho8v8v8nS1LDR0ru49s2ssr221M/z16q7r86q0ru49s7EvP7D6Mr2t/ujqLe0uf3AtKOsZWdsQ3JlYXRlU3luY0tIUigpv8nS1LDRzsS8/sPoyva3+9eqs8nNrLK9ttTP8ymho9XiuPbAqdW5z+C1sdPayMNDUFXW0NPQwctHUFXW0M2ssr221M/ztcS+5LH6o6zOxLz+w+jK9rf7v8nS1NTavfizzLzktKu13SjNqLn9YmluZGVyu/Jkb21haW4KIHNvY2tldLXISVBDu/rWximjrNXivs3OqrbgvfizzLzktcTNrLK9zOG5qcHLu/m0oaGjztLDx9aqtcBVbml4z7XNs9K7x9C91M7EvP6jrNLytMujrNPQuPbV4rj2wKnVudLUuvNGZW5jZbXEzajTw9DUtPO089T2x7/By6GjPGJyPgo8YnI+CkFuZHJvaWS7ub340ruyvbfhuLvBy0ZlbmNltcRzb2Z0d2FyZSBzdGFja6Gj1vfSqrfWsrzU2sj9sr+31qO6QyYjNDM7JiM0MzsgRmVuY2XA4M6709ovZnJhbWV3b3Jrcy9uYXRpdmUvbGlicy91aS9GZW5jZS5jcHA7IEO1xGxpYnN5bmO/4s6709ovc3lzdGVtL2NvcmUvbGlic3luYy9zeW5jLmM7IEtlcm5lbCBkcml2ZXKyv7fWzrvT2i9kcml2ZXJzL2Jhc2Uvc3luYy5joaPX3LXDwLTLtaOsa2VybmVsIGRyaXZlcrK/t9bKx82ssr21xNb30qrKtc/Wo6xsaWJzeW5jyse21GRyaXZlcr3Tv9q1xLfi17CjrEZlbmNlyse21GxpYnN5bmO1xL340ruyvbXEQyYjNDM7JiM0Mzu34tewoaNGZW5jZbvhsbvX986qR3JhcGhpY0J1ZmZlcrXEuL3K9Mvm18VHcmFwaGljQnVmZmVy1NrJ+rL61d+6zc/7t9G85LSryuSho8HtzeJGZW5jZbXEyO28/sq1z9bOu9PaL2RyaXZlcnMvYmFzZS9zd19zeW5jLmOho1N5bmNGZWF0dXJlc9PD0tSy6dGvz7XNs9ans9a1xM2ssr27+tbGo7ovZnJhbWV3b3Jrcy9uYXRpdmUvbGlicy9ndWkvU3luY0ZlYXR1cmVzLmNwcKGjPC9wPgo8cD48YnI+Cs/Cw+a31s72z8JGZW5jZdTaQW5kcm9pZNbQtcS+38zl08O3qKGjy/zW99KqtcTX99PDysdHcmFwaGljQnVmZmVy1NpBcHAsIEdQVbrNSFdDyP3V37zktKu13cqx1/fNrLK9oaM8YnI+Cjxicj4KytfPyM7CucrSu8/CR3JhcGhpY0J1ZmZlcrTTQXBwtb1EaXNwbGF5tcTCw7PMoaNHcmFwaGljQnVmZmVyz8jTyUFwcLbL1/fOqsn6svrV37340NC75tbGo6zIu7rzt8XI67W9QnVmZmVyUXVldWWjrLXItP3P+7fR1d/IobP21/fPwtK7sr21xOTWyL66z7PJoaNTdXJmYWNlRmxpbmdlctf3zqrP+7fR1d+jrLvhsNHDv7j2suO21NOmtcRHcmFwaGljQnVmZmVyyKHAtMn6s8lFR0xJbWFnZUtIUrbUz/Oho7rPs8nKsbbU09pHcmFwaGljQnVmZmVytcS0psDtt9bBvdbWx+m/9qGjttTT2k92ZXJsYXm1xLLjo6xTdXJmYWNlRmxpbmdlcrvh1rG9072rxuRidWZmZXIgaGFuZGxlt8XI60hXQ7XETGF5ZXIgbGlzdKGjttTT2tDo0qpHUFW75tbGtcSy46Oos6yz9khXQ7SmwO2y48r9u/LV39PQuLTU07Hku7u1xKOpo6xTdXJmYWNlRmxpbmdlcrvhvavHsMPmyfqzybXERUdMSW1hZ2VLSFLNqLn9Z2xFR0xJbWFnZVRhcmdldFRleHR1cmUyRE9FUygp1/fOqs7GwO29+NDQus+zyaOoaHR0cDovL3Nub3JwLm5ldC8yMDExLzEyLzE2L2FuZHJvaWQtZGlyZWN0LXRleHR1cmUuaHRtbKOpoaO6z7PJzeq681N1cmZhY2VGbGluZ2Vy09bX986qyfqy+tXfo6yw0UdQVbrPs8m6w7XEZnJhbWVidWZmZXK1xGhhbmRsZdbDtb1IV0PW0LXERnJhbWVidWZmZXJUYXJnZXTW0ChIV0PW0Gh3Y19kaXNwbGF5X2NvbnRlbnRzXzFfdNbQtcRod2NfbGF5ZXJfMV90wdCx7dfuuvPSu7j2c2xvdNPD09q3xUdQVbXE5NbIvr3hufvL+dTaYnVmZmVyKaGjSFdD1+6687X+vNNPdmVybGF5suPU2c35RGlzcGxhecnPyNOjrNXiyrFIV0PKx8/7t9HV36Gj1fu49rTz1sLB97PMyOfNvKO6PGJyPgo8L3A+CjxwPjxpbWcgc3JjPQ=="/uploadfile/Collfiles/20141001/201410010908579.png" alt="\">
vcv8yrGjrLvht6Kz9tDFusXWuMq+ttPB0Meww+a1xMP8we7S0cirsr/WtNDQzeqxz6Gjuq/K/WVnbENsaWVudFdhaXRTeW5jS0hSKCm/ycjDtffTw9Xf1+jI+7XItP3QxbrFt6LJ+qGjPGJyPgo8YnI+CtTatMu7+bSh1q7Jz6OsQW5kcm9pZLbUxuS9+NDQwcvAqdW5LUFORFJPSURfbmF0aXZlX2ZlbmNlX3N5bmMgIChodHRwOi8vd3d3Lmtocm9ub3Mub3JnL3JlZ2lzdHJ5L2VnbC9leHRlbnNpb25zL0FORFJPSUQvRUdMX0FORFJPSURfbmF0aXZlX2ZlbmNlX3N5bmMudHh0KaOs0MK808HLvdO/2mVnbER1cE5hdGl2ZUZlbmNlRkRBTkRST0lEKCmho8v8v8nS1LDR0ru49s2ssr221M/z16q7r86q0ru49s7EvP7D6Mr2t/ujqLe0uf3AtKOsZWdsQ3JlYXRlU3luY0tIUigpv8nS1LDRzsS8/sPoyva3+9eqs8nNrLK9ttTP8ymho9XiuPbAqdW5z+C1sdPayMNDUFXW0NPQwctHUFXW0M2ssr221M/ztcS+5LH6o6zOxLz+w+jK9rf7v8nS1NTavfizzLzktKu13SjNqLn9YmluZGVyu/Jkb21haW4KIHNvY2tldLXISVBDu/rWximjrNXivs3OqrbgvfizzLzktcTNrLK9zOG5qcHLu/m0oaGjztLDx9aqtcBVbml4z7XNs9K7x9C91M7EvP6jrNLytMujrNPQuPbV4rj2wKnVudLUuvNGZW5jZbXEzajTw9DUtPO089T2x7/By6GjPGJyPgo8YnI+CkFuZHJvaWS7ub340ruyvbfhuLvBy0ZlbmNltcRzb2Z0d2FyZSBzdGFja6Gj1vfSqrfWsrzU2sj9sr+31qO6QyYjNDM7JiM0MzsgRmVuY2XA4M6709ovZnJhbWV3b3Jrcy9uYXRpdmUvbGlicy91aS9GZW5jZS5jcHA7IEO1xGxpYnN5bmO/4s6709ovc3lzdGVtL2NvcmUvbGlic3luYy9zeW5jLmM7IEtlcm5lbCBkcml2ZXKyv7fWzrvT2i9kcml2ZXJzL2Jhc2Uvc3luYy5joaPX3LXDwLTLtaOsa2VybmVsIGRyaXZlcrK/t9bKx82ssr21xNb30qrKtc/Wo6xsaWJzeW5jyse21GRyaXZlcr3Tv9q1xLfi17CjrEZlbmNlyse21GxpYnN5bmO1xL340ruyvbXEQyYjNDM7JiM0Mzu34tewoaNGZW5jZbvhsbvX986qR3JhcGhpY0J1ZmZlcrXEuL3K9Mvm18VHcmFwaGljQnVmZmVy1NrJ+rL61d+6zc/7t9G85LSryuSho8HtzeJGZW5jZbXEyO28/sq1z9bOu9PaL2RyaXZlcnMvYmFzZS9zd19zeW5jLmOho1N5bmNGZWF0dXJlc9PD0tSy6dGvz7XNs9ans9a1xM2ssr27+tbGo7ovZnJhbWV3b3Jrcy9uYXRpdmUvbGlicy9ndWkvU3luY0ZlYXR1cmVzLmNwcKGjPC9wPgo8cD48YnI+Cs/Cw+a31s72z8JGZW5jZdTaQW5kcm9pZNbQtcS+38zl08O3qKGjy/zW99KqtcTX99PDysdHcmFwaGljQnVmZmVy1NpBcHAsIEdQVbrNSFdDyP3V37zktKu13cqx1/fNrLK9oaM8YnI+Cjxicj4KytfPyM7CucrSu8/CR3JhcGhpY0J1ZmZlcrTTQXBwtb1EaXNwbGF5tcTCw7PMoaNHcmFwaGljQnVmZmVyz8jTyUFwcLbL1/fOqsn6svrV37340NC75tbGo6zIu7rzt8XI67W9QnVmZmVyUXVldWWjrLXItP3P+7fR1d/IobP21/fPwtK7sr21xOTWyL66z7PJoaNTdXJmYWNlRmxpbmdlctf3zqrP+7fR1d+jrLvhsNHDv7j2suO21NOmtcRHcmFwaGljQnVmZmVyyKHAtMn6s8lFR0xJbWFnZUtIUrbUz/Oho7rPs8nKsbbU09pHcmFwaGljQnVmZmVytcS0psDtt9bBvdbWx+m/9qGjttTT2k92ZXJsYXm1xLLjo6xTdXJmYWNlRmxpbmdlcrvh1rG9072rxuRidWZmZXIgaGFuZGxlt8XI60hXQ7XETGF5ZXIgbGlzdKGjttTT2tDo0qpHUFW75tbGtcSy46Oos6yz9khXQ7SmwO2y48r9u/LV39PQuLTU07Hku7u1xKOpo6xTdXJmYWNlRmxpbmdlcrvhvavHsMPmyfqzybXERUdMSW1hZ2VLSFLNqLn9Z2xFR0xJbWFnZVRhcmdldFRleHR1cmUyRE9FUygp1/fOqs7GwO29+NDQus+zyaOoaHR0cDovL3Nub3JwLm5ldC8yMDExLzEyLzE2L2FuZHJvaWQtZGlyZWN0LXRleHR1cmUuaHRtbKOpoaO6z7PJzeq681N1cmZhY2VGbGluZ2Vy09bX986qyfqy+tXfo6yw0UdQVbrPs8m6w7XEZnJhbWVidWZmZXK1xGhhbmRsZdbDtb1IV0PW0LXERnJhbWVidWZmZXJUYXJnZXTW0ChIV0PW0Gh3Y19kaXNwbGF5X2NvbnRlbnRzXzFfdNbQtcRod2NfbGF5ZXJfMV90wdCx7dfuuvPSu7j2c2xvdNPD09q3xUdQVbXE5NbIvr3hufvL+dTaYnVmZmVyKaGjSFdD1+6687X+vNNPdmVybGF5suPU2c35RGlzcGxhecnPyNOjrNXiyrFIV0PKx8/7t9HV36Gj1fu49rTz1sLB97PMyOfNvKO6PGJyPgo8L3A+CjxwPjxpbWcgc3JjPQ=="/uploadfile/Collfiles/20141001/201410010908579.png" alt="\">
可以看到,對於非Overlay的層來說GraphicBuffer先後經過兩個生產消費者模型。我們知道GraphicBuffer核心包含的是buffer_handle_t結構,它指向的native_handle_t包含了gralloc中申請出來的圖形緩沖區的文件描述符和其它基本屬性,這個文件描述符會被同時映射到客戶端和服務端,作為共享內存。
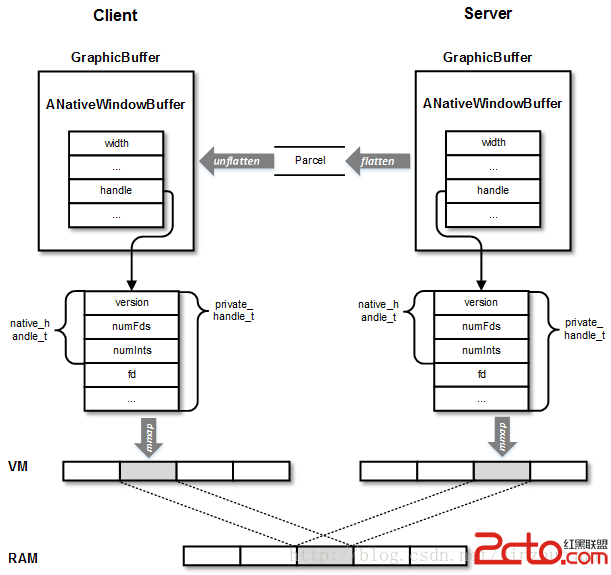
由於服務和客戶端進程都可以訪問同一物理內存,因此不加同步的話會引起錯誤。為了協調客戶端和服務端,在傳輸GraphicBuffer時,還帶有Fence,標志了它是否被上一個使用者使用完畢。Fence按作用大體分兩種:acquireFence和releaseFence。前者用於生產者通知消費者生產已完成,後者用於消費者通知生產者消費已完成。下面分別看一下這兩種Fence的產生和使用過程。首先是acquireFence的使用流程:
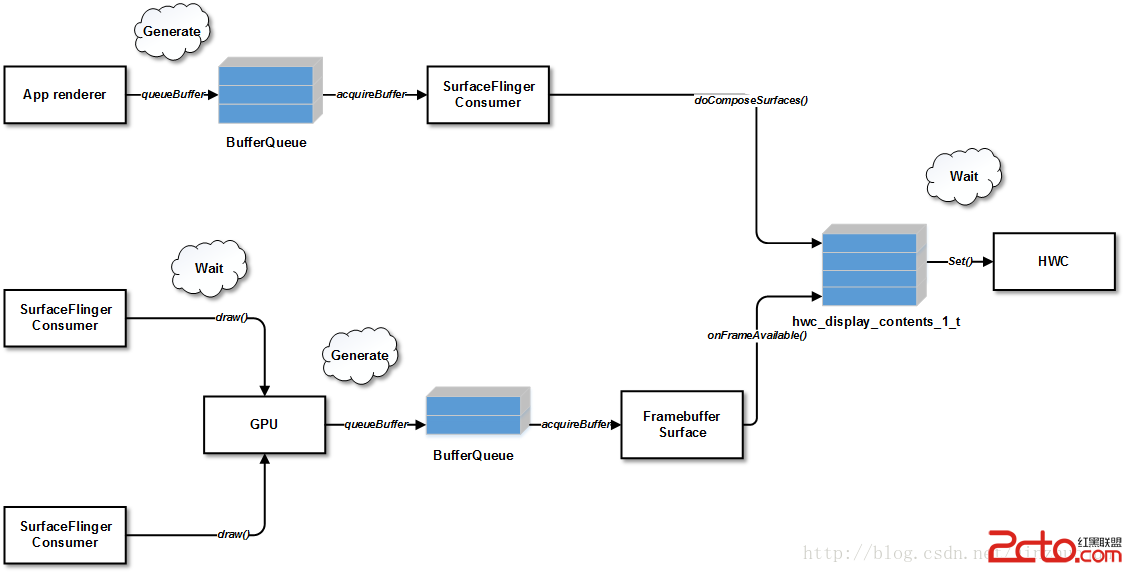
當App端通過queueBuffer()向BufferQueue插入GraphicBuffer時,會順帶一個Fence,這個Fence指示這個GraphicBuffer是否已被生產者用好。之後該GraphicBuffer被消費者通過acquireBuffer()拿走,同時也會取出這個acquireFence。之後消費者(也就是SurfaceFlinger)要把它拿來渲染時,需要等待Fence被觸發。如果該層是通過GPU渲染的,那麼使用它的地方是Layer::onDraw(),其中會通過bindTextureImage()綁定紋理:
486 status_t err = mSurfaceFlingerConsumer->bindTextureImage();
該函數最後會調用doGLFenceWaitLocked()等待acquireFence觸發。因為再接下來就是要拿來畫了,如果這兒不等待直接往下走,那渲染出來的就是錯誤的內容。
如果該層是HWC渲染的Overlay層,那麼不需要經過GPU,那就需要把這些層對應的acquireFence傳到HWC中。這樣,HWC在合成前就能確認這個buffer是否已被生產者使用完,因此一個正常點的HWC需要等這些個acquireFence全被觸發才能去繪制。這個設置的工作是在SurfaceFlinger::doComposeSurfaces()中完成的,該函數會調用每個層的layer::setAcquireFence()函數:
428 if (layer.getCompositionType() == HWC_OVERLAY) {
429 sp
...
431 fenceFd = fence->dup();
...
437 layer.setAcquireFenceFd(fenceFd);
可以看到其中忽略了非Overlay的層,因為HWC不需要直接和非Overlay層同步,它只要和這些非Overlay層合成的結果FramebufferTarget同步就可以了。GPU渲染完非Overlay的層後,通過queueBuffer()將GraphicBuffer放入FramebufferSurface對應的BufferQueue,然後FramebufferSurface::onFrameAvailable()被調用。它先會通過nextBuffer()->acquireBufferLocked()從BufferQueue中拿一個GraphicBuffer,附帶拿到它的acquireFence。接著調用HWComposer::fbPost()->setFramebufferTarget(),其中會把剛才acquire的GraphicBuffer連帶acquireFence設到HWC的Layer
list中的FramebufferTarget slot中:
580 acquireFenceFd = acquireFence->dup();
...
586 disp.framebufferTarget->acquireFenceFd = acquireFenceFd;
綜上,HWC進行最後處理的前提是Overlay層的acquireFence及FramebufferTarget的acquireFence都被觸發。
看完acquireFence,再看看releaseFence的使用流程:
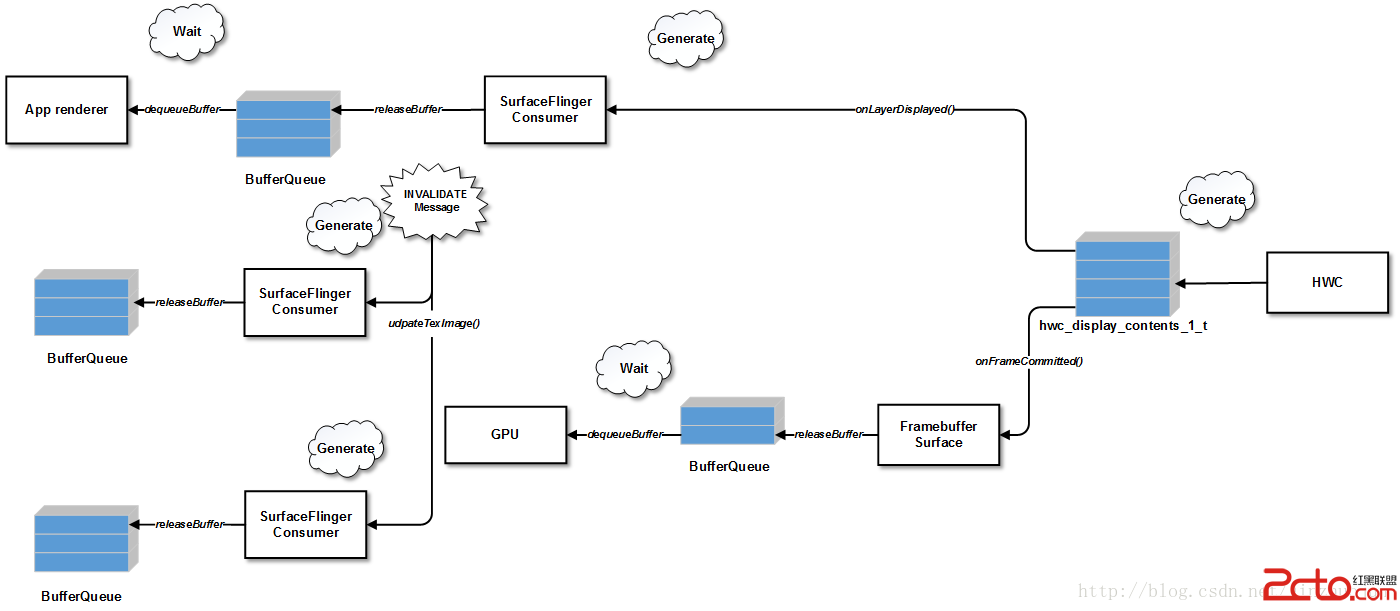
前面提到合成的過程先是GPU工作,在doComposition()函數中合成非Overlay的層,結果放在framebuffer中。然後SurfaceFlinger會調用postFramebuffer()讓HWC開始工作。postFramebuffer()中最主要是調用HWC的set()接口通知HWC進行合成顯示,然後會將HWC中產生的releaseFence(如有)同步到SurfaceFlingerConsumer中。實現位於Layer的onLayerDisplayed()函數中:
151 mSurfaceFlingerConsumer->setReleaseFence(layer->getAndResetReleaseFence());
上面主要是針對Overlay的層,那對於GPU繪制的層呢?在收到INVALIDATE消息時,SurfaceFlinger會依次調用handleMessageInvalidate()->handlePageFlip()->Layer::latchBuffer()->SurfaceFlingerConsumer::updateTexImage() ,其中會調用該層對應Consumer的GLConsumer::updateAndReleaseLocked() 函數。該函數會釋放老的GraphicBuffer,釋放前會通過syncForReleaseLocked()函數插入releaseFence,代表如果觸發時該GraphicBuffer消費者已經使用完畢。然後調用releaseBufferLocked()還給BufferQueue,當然還帶著這個releaseFence。這樣,當這個GraphicBuffer被生產者再次通過dequeueBuffer()拿出時,就可以通過這個releaseFence來判斷消費者是否仍然在使用。
另一方面,HWC合成完畢後,SurfaceFlinger會依次調用DisplayDevice::onSwapBuffersCompleted() -> FramebufferSurface::onFrameCommitted()。onFrameCommitted()核心代碼如下:
148 sp
...
151 status_t err = addReleaseFence(mCurrentBufferSlot,
152 mCurrentBuffer, fence);
此處拿到HWC生成的FramebufferTarget的releaseFence,設到FramebufferSurface中相應的GraphicBuffer Slot中。這樣FramebufferSurface對應的GraphicBuffer也可以被釋放回BufferQueue了。當將來EGL從中拿到這個buffer時,照例也要先等待這個releaseFence觸發才能使用。
 AIDL(續)
AIDL(續)
這篇文章講的是在不同的工程文件中實現IPC。這次我決定用一個工程完成首先,我先介紹一下流程1服務端先創建Service來監聽客戶端的連接請求,然後創建AIDL文件,將暴露
 android各種對話框總結筆記
android各種對話框總結筆記
確定取消對話框(帶圖標) //(上下文,主題) new AlertDialog.Builder(this, AlertDialog.THEME_DEVICE
 Android實習札記(6)---ViewPager使用詳解
Android實習札記(6)---ViewPager使用詳解
Android實習札記(6)---ViewPager使用詳解 札記(5)中介紹了Fragment構建簡單的底部導航欄,在結尾的時候說要在下一節
 Android系統模擬位置的使用方法
Android系統模擬位置的使用方法
本文為大家分享了Android模擬位置的使用方法,支持Android6.0,供大家參考,具體內容如下1、開啟系統設置中的模擬位置Android 6.0 以下:【開發者選項