編輯:關於Android編程
我曾在《淺談XMl解析的幾種方式》一文中介紹了使用DOM方式,SAX方式,Jdom方式,以及dom4j的方式來解析XML。除了可以使用以上方式來解析XML文件外,也可以使用Android系統內置的Pull解析器來解析XML文件。 Pull解析器的運行方式與SAX解析器相似。它提供了類似的事件,如開始元素和結束元素事件。使用parser.next()可以進入下一個元素並觸發相應事件。事件將作為數值代碼被發送,因此可以使用一個switch對感興趣的事件進行選擇,然後進行相應處理。當元素開始解析時,調用parser.nextText()方法可以獲取下一個Text類型元素的值。
(1)簡單的結構:一個接口,一個例外,一個工廠組成了 Pull解析器。
(2)簡單易用:Pull解析器只有一個重要的方法next(),它被用來檢索下一個事件。而它的事件也僅僅只有5個。
Ø START DOCUMENT;
Ø START_TAG;
Ø TEXT;
Ø END_TAG;
Ø END_DOCUMENT。
(3)多功能性:通用的XML解析器和多種實現,並具有可擴展性。
(4)最小的需求:為了與JavaME兼容和在小型設備上運作而設計,並允許創建占用非常小的內存的XMLPULL解析器。
解析XML內容的方式與SAX是相似的,同樣包括開始元素和結束元素事件,使用parser.next()可以進入下一個元素並觸發相應事件。但是它們不同的是,SAX的事件驅動是回調相應方法,需要提供回調的方法,而後在SAX內部自動調用相應的方法。而Pull解析器並沒有強制要求提供觸發的方法。因為它觸發的事件並不是一個方法,而是一個數字。至於觸發的事件要不要處理,由程序員自己決定。
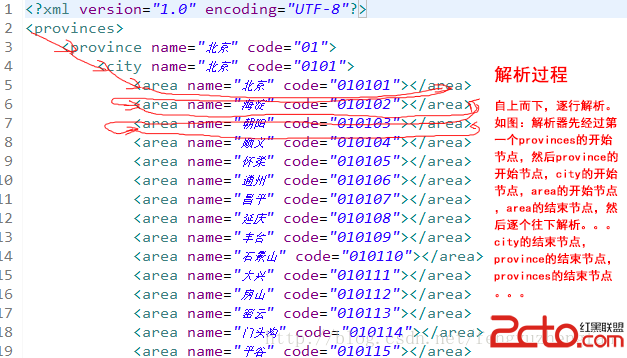
看到這裡,讀者應該明白,為什麼Pull解析器會被集成Android裡了吧。並且Pull解析器,也可以用在JavaEE等非Android項目中,不一定只拘泥於Android的開發。下面我們通過一個示例來理解一下Pull解析的過程吧。
public static ListgetPersons(InputStream inStream) throws Exception{ Person person = null; List persons = null; XmlPullParser pullParser = Xml.newPullParser(); pullParser.setInput(inStream, UTF-8); int event = pullParser.getEventType();//觸發第一個事件 while(event!=XmlPullParser.END_DOCUMENT){ switch (event) { case XmlPullParser.START_DOCUMENT: persons = new ArrayList (); break; case XmlPullParser.START_TAG: if(person.equals(pullParser.getName())){ int id = new Integer(pullParser.getAttributeValue(0)); person = new Person(); person.setId(id); } if(person!=null){ if(name.equals(pullParser.getName())){ person.setName(pullParser.nextText()); } if(age.equals(pullParser.getName())){ person.setAge(new Short(pullParser.nextText())); } } break; case XmlPullParser.END_TAG: if(person.equals(pullParser.getName())){ persons.add(person); person = null; } break; } event = pullParser.next(); } return persons; }
代碼說明:
1)int event =pullParser.getEventType();是Pull解析器的第一個事件。讀者可以看到,這個方法的返回值是int類型的,這就是前面所提到的Pull解析器返回的是一個數字,類似於一個信號。那麼這些信號都代表什麼意思呢? Pull解析器已經定義了這五個常量,而且對於事件,僅僅只有這5個,如下:
• XmlPullParser.START_DOCUMENT (開始解析,只執行一次);
• XmlPullParser.START_TAG (開始元素);
• XmlPullParser.TEXT (解析文本);
• XmlPullParser END_TAG (結束元素);
• XmlPullParser END_DOCUMENT (結束解析,只執行一次)。
2 )“parser.getEventType()”觸發了第一個事件,根據XML的語法,也就是從它開始了解析文檔。那麼,怎麼樣觸發下一個事件呢?要通過Parser中最重要的方法:
parser.next();
注意:該方法是有返回值的,在Pull觸發下—個事件的同時,也獲得該事件的“信號”。通過獲得的信號進行switch操作。
3)“parsergetAttribiiteValue()”獲得相應屬性的值。它有兩種形式,可以通過屬性的索引,也可以通過(命名空間,屬性名)進行索引。
public static void save(Listpersons, OutputStream outStream) throws Exception{ XmlSerializer serializer = Xml.newSerializer(); serializer.setOutput(outStream, UTF-8); serializer.startDocument(UTF-8, true); serializer.startTag(null, persons); for(Person person : persons){ serializer.startTag(null, person); serializer.attribute(null, id, person.getId().toString()); serializer.startTag(null, name); serializer.text(person.getName()); serializer.endTag(null, name); serializer.startTag(null, age); serializer.text(person.getAge().toString()); serializer.endTag(null, age); serializer.endTag(null, person); } serializer.endTag(null, persons); serializer.endDocument(); outStream.flush(); outStream.close(); }
(1 ) “XmlSerializCTserializer= Xml.newSerializer()”定義了一個接口來實現 XML信息的串行化。那串行化又是什麼呢?其也叫做對象的序列化,並不僅僅是簡單地把對象保存在存儲器上,它還可以使我們以二進制方式通過網絡傳輸對象,使對象變得可以像基本數據一樣傳遞。之後可以通過反串行化從這些連續的字節(byte)數據重新構建一個與原始對象狀態相同的對象。
(2)定義一個方法,第一個參數是要生成XML文件的內容,第二個參教是一個寫入器。 Write (寫入器)接口要比輸出流更加靈活。它可以向更多的媒介進行榆出,比如向硬盤、內存、網絡等進行輸出。new”一個持久化的XML對象。在這裡,應該明白為什麼要持久化,說白了就是一種寫入硬盤的行為。
serializer.setOutput(writer);
設置了輸出的方向。它接收兩種類型的輸出,分別是輸出流和寫入器。這點用到了剛才向讀者介紹的writer寫入器。
(3)XML中標簽的成對出現,有開始,必有結束。所以在寫入一個satrtTag()時,筆者習慣緊跟著寫入與之相對應的endTag()。這樣不至於在復雜的生成結構時,弄錯了XML生成結構。
方法說明:第一個參數是XML的命名空間,第二個是標簽名,endTag()相同。
Android開發之解析XML並實現三級聯動效果
 android開發步步為營之31:TabActivity的用法Tab顯示在底部
android開發步步為營之31:TabActivity的用法Tab顯示在底部
Tab標簽頁是一個非常常用的控件,.net裡面就有multipage+tabstrip組合通過標簽的切換實現頁面的切換,同理html裡面我們常用frameset來
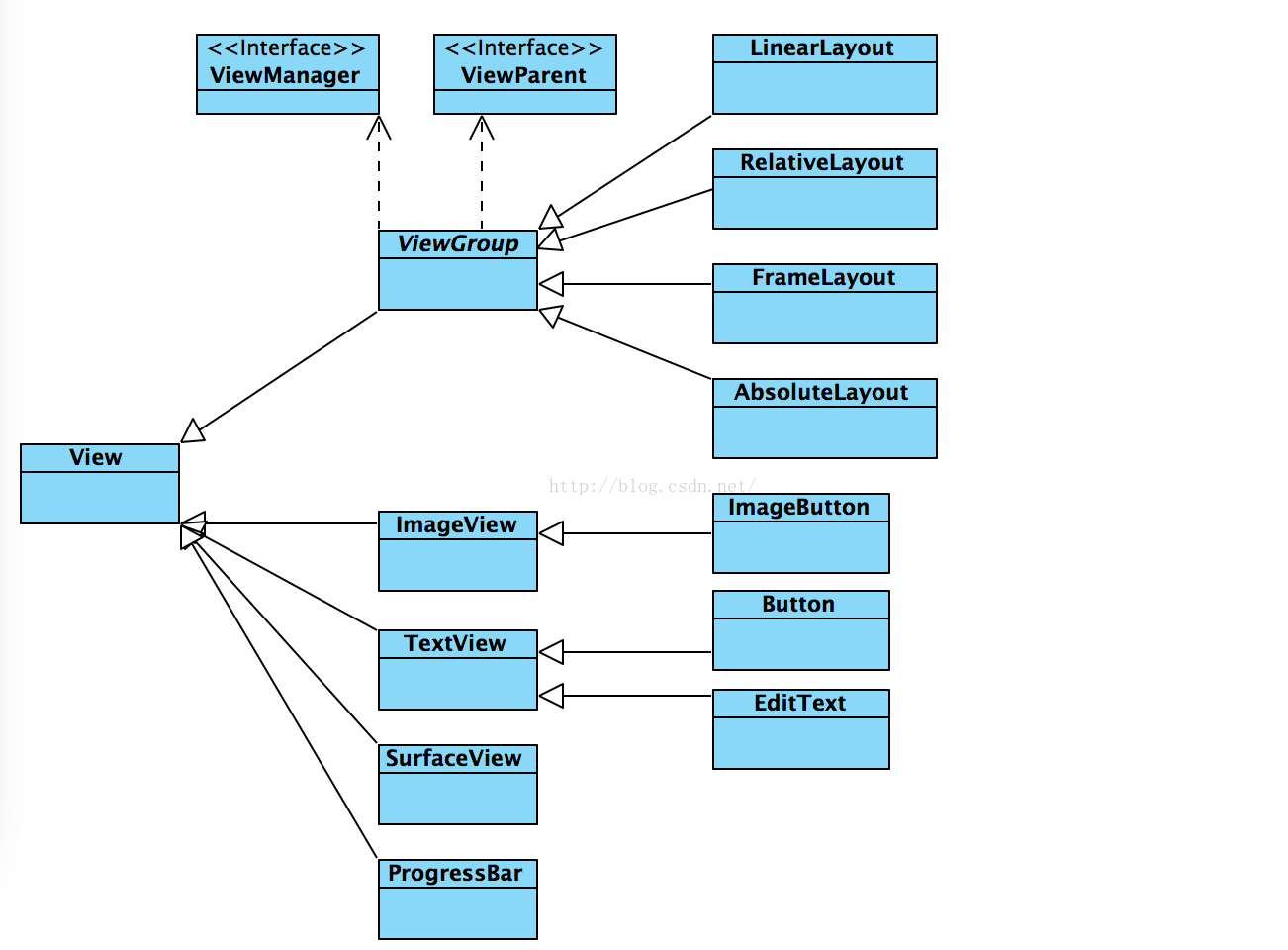 android 自定義控件學習之三 控件布局常用知識總結
android 自定義控件學習之三 控件布局常用知識總結
1、View是什麼View是Android所有控件的基類,簡單到TextView、Button,復雜到RelativeLayout,LinearLayout,其共同基類都
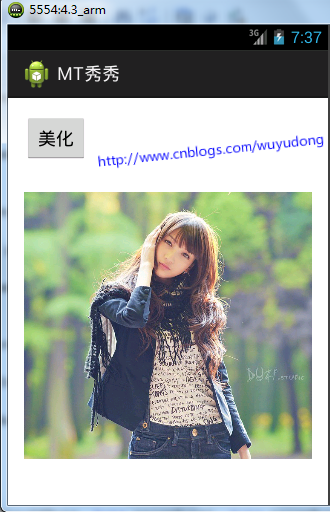 調用meitu秀秀.so文件實現美圖功能
調用meitu秀秀.so文件實現美圖功能
本文屬於實戰系列,是對《Android C代碼回調java方法》等文的實踐,調用meitu秀秀的libmtimage-jni.so文件來實現圖片的美化功能首先反編譯得到/
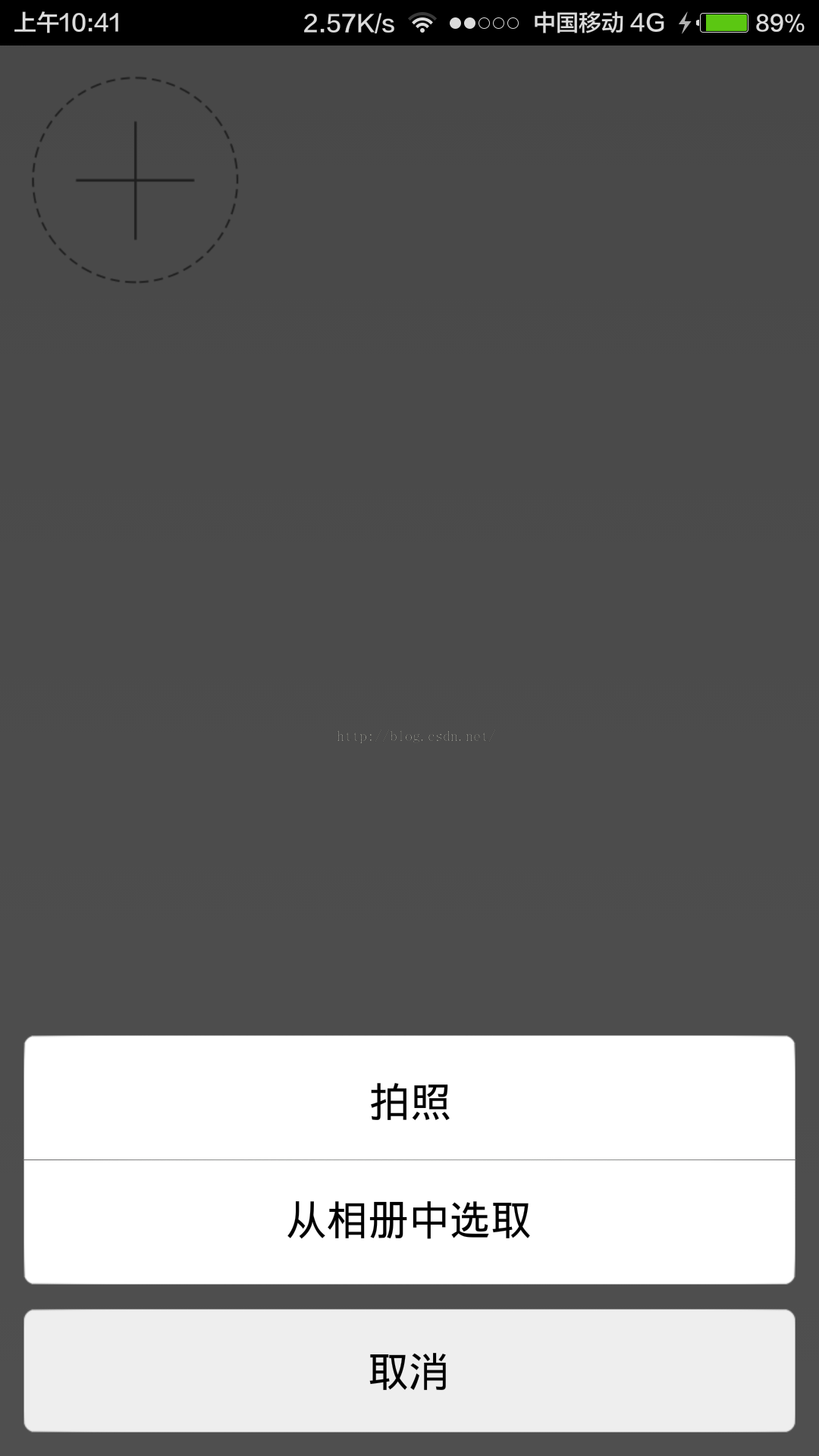 Android仿微信照片選擇器實現預覽查看圖片
Android仿微信照片選擇器實現預覽查看圖片
好了下面進入正題,我們先看一下實現效果吧:下面來介紹一下代碼: 本思路就是: 1.先到手機中掃描jpeg和png的圖片 2.獲取導圖片的路徑和圖片的父路徑名