ml在開發中的作用不可小觑,很多時候我們都要用到這種文件,所以學習它的解析方式很是必要。
我們都知道java中xml的解析有:dom,SAX,但是Android下我們使用pool解析,是更為方便,而且有專門的api可以使用。
dom:一次加載到內存,生成一個樹狀結構,消耗的內存較大
SAX:基於事件,速度快,效率高,不能回退。
1,首先我們需要定義出來解析器,它的定義方式,是通過Xml new出來的,這點要記著。
XmlPullParser parser = Xml.newPullParser();
2,然後我們需要,設置xml的文件源,也即初始化解析器,使用的方法如下,同時我們還要設置起編碼格式,xml的編碼一般為"utf-8",所以第二個參數我們就寫成"utf-8",而第一個參數的話,如果我們的xml放在本地的話,我們可以通過類加載器來得到,且其返回類型就是inputstream。
parser.setInput(InputStream inputStream, String inputEncoding)
類加載器得到文件的位置,並返回inputstream。
MainActivity.class.getClassLoader().getResourceAsStream("xml文件路徑")
3,初始化解析器後,我們就可以開始了,xml的標簽很多,這裡呢,我們需要調用的方法是。
1
int type = parser.getEventType();
我們查看api可知,這裡獲得的是標簽,
比如:(這是系統中的定義)
int START_DOCUMENT = 0;
int END_DOCUMENT = 1;
int START_TAG = 2;
int END_TAG = 3;
從名字我們就能很容易的知道其含義,xml開始與結束的標簽,以及一個標簽對的開始與結束。
所以我們就可以對獲得type與這些標簽進行對比,這樣我們就可以獲取標簽的值。
4,解析xml
復制代碼
while (type != XmlPullParser.END_DOCUMENT) {
switch (type) {
case XmlPullParser.START_TAG:
if ("infos".equals(parser.getName())) {
// 解析到了全局開始標簽。
weatherinfos = new ArrayList<WeatherInfo>();
} else if ("city".equals(parser.getName())) {
weatherinfo = new WeatherInfo();
// 得到id
String id = parser.getAttributeValue(0);
weatherinfo.setId(Integer.parseInt(id));
} else if ("temp".equals(parser.getName())) {
String temp = parser.nextText();
weatherinfo.setTemp(temp);
}
break;
case XmlPullParser.END_TAG:
if ("city".equals(parser.getName())) {
// 一個城市的信息處理完畢。
weatherinfos.add(weatherinfo);
weatherinfo = null;
}
break;
}
type = parser.next();
}
復制代碼
xml的解析後,我們還要保存它的值,所以我就把每次xml解析後的值,放到集合中,
這裡要注意幾點,
parser.getAttributeValue(0);是得到標簽中的id值。
每解析完一次後,我們要把循環往下走,所以type = parser.next();
這樣我們就可以解析出xml中的數據了。
 Android開發中Activity的生命周期及加載模式詳解
Android開發中Activity的生命周期及加載模式詳解
 Android的分辨率和屏幕適配詳解
Android的分辨率和屏幕適配詳解
 Android之聯系人PinnedHeaderListView使用介紹
Android之聯系人PinnedHeaderListView使用介紹
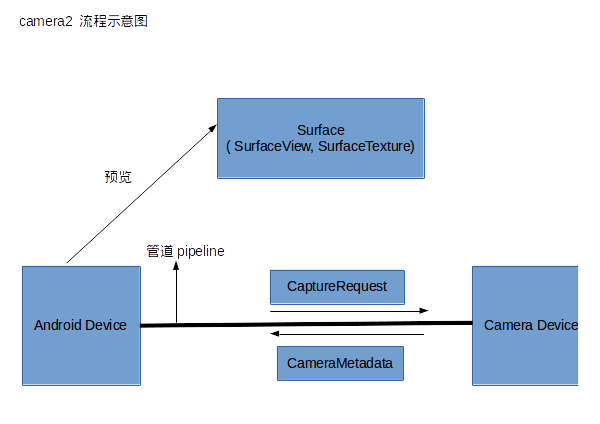 Android.Camera2相機超詳細講解
Android.Camera2相機超詳細講解