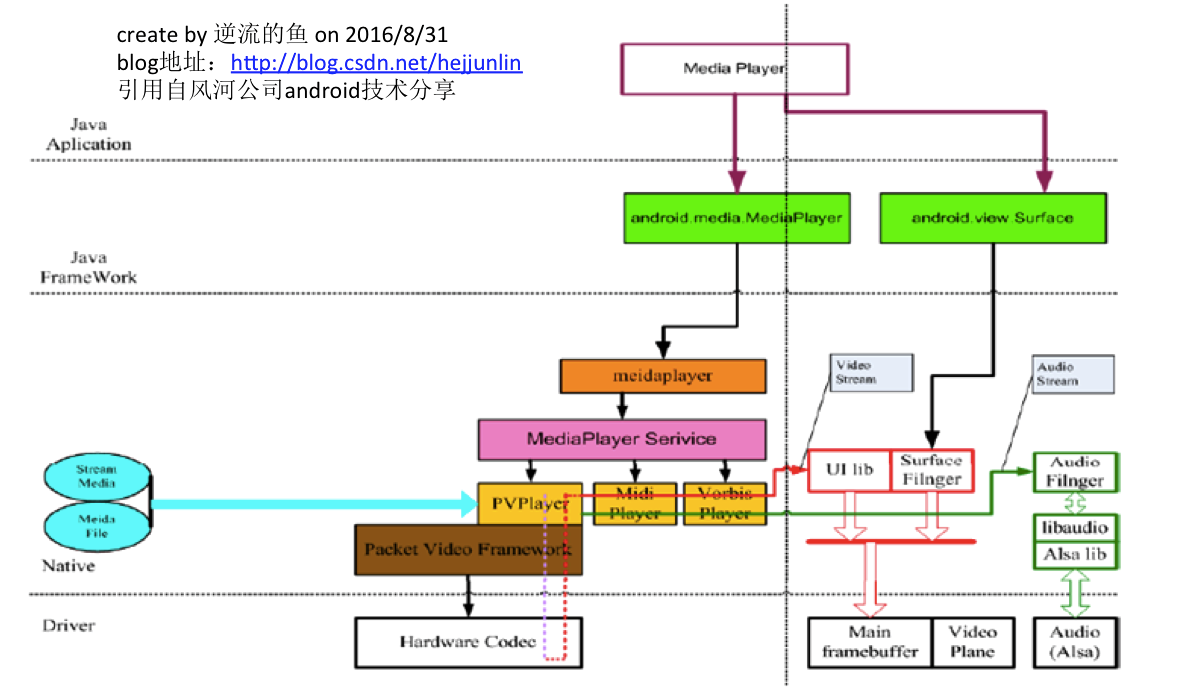
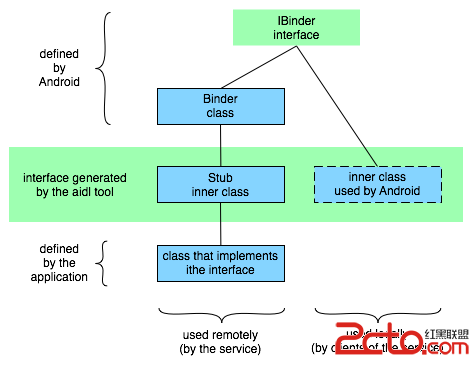
編輯:關於Android編程
在我們做有關android項目的時候,肯定會涉及到對xml文件的解析操作,下面給大家介紹一下xml文件的解析,包含DOM、SAX、Pull以及以前我們用到的DOM4J和JDOM:
要解析的XML文件:person.xml
zhangsan 25lisi 23
package cn.itcast.domain;
public class Person {
private Integer id;
private String name;
private Short age;
public Person(){}
public Person(Integer id, String name, Short age) {
this.id = id;
this.name = name;
this.age = age;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Short getAge() {
return age;
}
public void setAge(Short age) {
this.age = age;
}
@Override
public String toString() {
return "Person [age=" + age + ", id=" + id + ", name=" + name + "]";
}
}
public static ListgetPersons(InputStream inStream) throws Throwable{ List persons = new ArrayList (); //創建解析器工廠 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //創建解析器 DocumentBuilder builder = factory.newDocumentBuilder(); //創建文檔樹模型,所有的Node都以一定的順序包含在Document對象之內, //排列成一個樹狀結構,以後對XML文檔的所有操作都與解析器無關 Document documnet = builder.parse(inStream); //獲取根元素 Element root = documnet.getDocumentElement(); //獲得根元素下的person節點列表 NodeList personNodes = root.getElementsByTagName("person"); for(int i=0 ; i < personNodes.getLength(); i++){ Person person = new Person(); //獲得節點中的元素 Element personElement = (Element)personNodes.item(i); //獲得person中id屬性 person.setId(new Integer(personElement.getAttribute("id"))); //獲得person節點下的子節點 NodeList personChilds = personElement.getChildNodes(); for(int y=0 ; y < personChilds.getLength(); y++){ if(personChilds.item(y).getNodeType()==Node.ELEMENT_NODE){//判斷當前節點是否是元素類型節點 Element childElement = (Element)personChilds.item(y); if("name".equals(childElement.getNodeName())){ //獲得相應元素的值 person.setName(childElement.getFirstChild().getNodeValue()); }else if("age".equals(childElement.getNodeName())){ person.setAge(new Short(childElement.getFirstChild().getNodeValue())); } } } persons.add(person); } return persons; }
public ListgetPersons(InputStream inStream) throws Throwable{ //創建SAXParserFactory SAXParserFactory factory = SAXParserFactory.newInstance(); //創建SAX解析器 SAXParser parser = factory.newSAXParser(); //創建XML解析處理器 PersonParser personParser = new PersonParser(); //將XML解析處理器分配給解析器,對文檔進行解析,將每個事件發送給處理器 parser.parse(inStream, personParser); inStream.close(); return personParser.getPersons(); } //定義解析處理器 private final class PersonParser extends DefaultHandler{ private List persons = null;//將解析的數據放在List集合中 private String tag = null;//定義一個全局變量的標簽名稱 private Person person = null; public List getPersons() { return persons; } //解析Document @Override public void startDocument() throws SAXException { //解析 部分 persons = new ArrayList (); } @Override public void endDocument() throws SAXException { System.out.println("end parse xml"); } /** * 解析Element * namespaceURI 命名空間 * localName 不帶前綴部分 --->person * qName 帶前綴部分---->abc:worker * attributes 屬性集合 ---->id="001".... */ @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //解析 部分 if("person".equals(localName)){ person = new Person(); person.setId(new Integer(attributes.getValue(0))); } tag = localName; } @Override public void characters(char[] ch, int start, int length) throws SAXException { //解析其中的文本 zhangsan -->zhangsan if(tag!=null){ String data = new String(ch, start, length);//獲取文本節點的數據 if("name".equals(tag)){ person.setName(data); }else if("age".equals(tag)){ person.setAge(new Short(data)); } } } //解析結束元素 @Override public void endElement(String uri, String localName, String qName) throws SAXException { if("person".equals(localName)){ persons.add(person); person = null; } tag = null; } }
/** * 使用pull解析XML文檔 * @param inStream * @return * @throws Throwable */ public static List采用pull解析器創建一個xml文檔:getPersons(InputStream inStream) throws Throwable{ List persons = null; Person person = null; XmlPullParser parser = Xml.newPullParser(); parser.setInput(inStream, "UTF-8"); int eventType = parser.getEventType();//產生第一個事件 while(eventType!=XmlPullParser.END_DOCUMENT){//只要不是文檔結束事件 switch (eventType) { case XmlPullParser.START_DOCUMENT://判斷當前事件是否是文檔開始事件 persons = new ArrayList ();//初始化Person集合 break; case XmlPullParser.START_TAG://判斷當前事件是否是標簽元素開始事件 String name = parser.getName();//獲取解析器當前指向的元素的名稱 if("person".equals(name)){ person = new Person(); //得到相應的標簽的屬性值 person.setId(new Integer(parser.getAttributeValue(0))); } if(person!=null){ if("name".equals(name)){ //獲取解析器當前指向元素的下一個文本節點的值 person.setName(parser.nextText()); } if("age".equals(name)){ person.setAge(new Short(parser.nextText())); } } break; case XmlPullParser.END_TAG://判斷當前事件是否是標簽元素結束事件 if("person".equals(parser.getName())){ persons.add(person); person = null; } break; } //進入下一元素並觸發相應事件 eventType = parser.next(); } return persons; }
/** * 使用pull解析器創建一個xml文檔 * @param persons * @param writer * @throws Throwable */ public static void save(List在android項目中通過Junit對各方法進行測試:persons, Writer writer) throws Throwable{ XmlSerializer serializer = Xml.newSerializer(); serializer.setOutput(writer); serializer.startDocument("UTF-8", true); serializer.startTag(null, "persons"); for(Person person : persons){ serializer.startTag(null, "person"); serializer.attribute(null, "id", person.getId().toString()); serializer.startTag(null, "name"); serializer.text(person.getName()); serializer.endTag(null, "name"); serializer.startTag(null, "age"); serializer.text(person.getAge().toString()); serializer.endTag(null, "age"); serializer.endTag(null, "person"); } serializer.endTag(null, "persons"); serializer.endDocument(); writer.flush(); writer.close(); }
注意在使用junit的時候,需要在AndroidMainifest.xml中加入:
編寫我們的java測試類:
public class PersonServiceTest extends AndroidTestCase {
private static final String TAG = "PersonServiceTest";
public void testSAXGetPersons() throws Throwable{
SAXPersonService service = new SAXPersonService();
InputStream inStream = getClass().getClassLoader().getResourceAsStream("person.xml");
List persons = service.getPersons(inStream);
for(Person person : persons){
Log.i(TAG, person.toString());
}
}
public void testDomGetPersons() throws Throwable{
InputStream inStream = getClass().getClassLoader().getResourceAsStream("person.xml");
List persons = DOMPersonService.getPersons(inStream);
for(Person person : persons){
Log.i(TAG, person.toString());
}
}
public void testPullGetPersons() throws Throwable{
InputStream inStream = getClass().getClassLoader().getResourceAsStream("person.xml");
List persons = PULLPersonService.getPersons(inStream);
for(Person person : persons){
Log.i(TAG, person.toString());
}
}
}
運行輸出即可得到我們想要的結果!
幾種方法比較: SAX:一行一行讀取,效率高,讀取到相應需要的數據後不再往下操作,操作復雜,適合移動設備
DOM:操作簡單,一開始加載一個DOM樹,當XML文件相對比計較大的時候影響效率,速度慢
* Pull解析和Sax解析不一樣的地方有
* (1)pull讀取xml文件後觸發相應的事件調用方法返回的是數字
* (2)pull可以在程序中控制想解析到哪裡就可以停止解析
其實pull解析xml不僅適用於android,在我們的javase中也可以使用pull解析器來解析xml文件,不過需要導入相應的jar包:
kxml2-2.3.0.jar,下載地址:http://kxml.sourceforge.net/
xmlpull_1_1_3_4c.jar 下載地址:http://www.xmlpull.org/
以前我們還使用了DOM4J和JDOM來解析xml,可以參見我的博客,不過需要導入相應的支持jar包:
DOM4J解析XML:http://blog.csdn.net/harderxin/article/details/7285770
JDOM解析XML:http://blog.csdn.net/harderxin/article/details/7285754
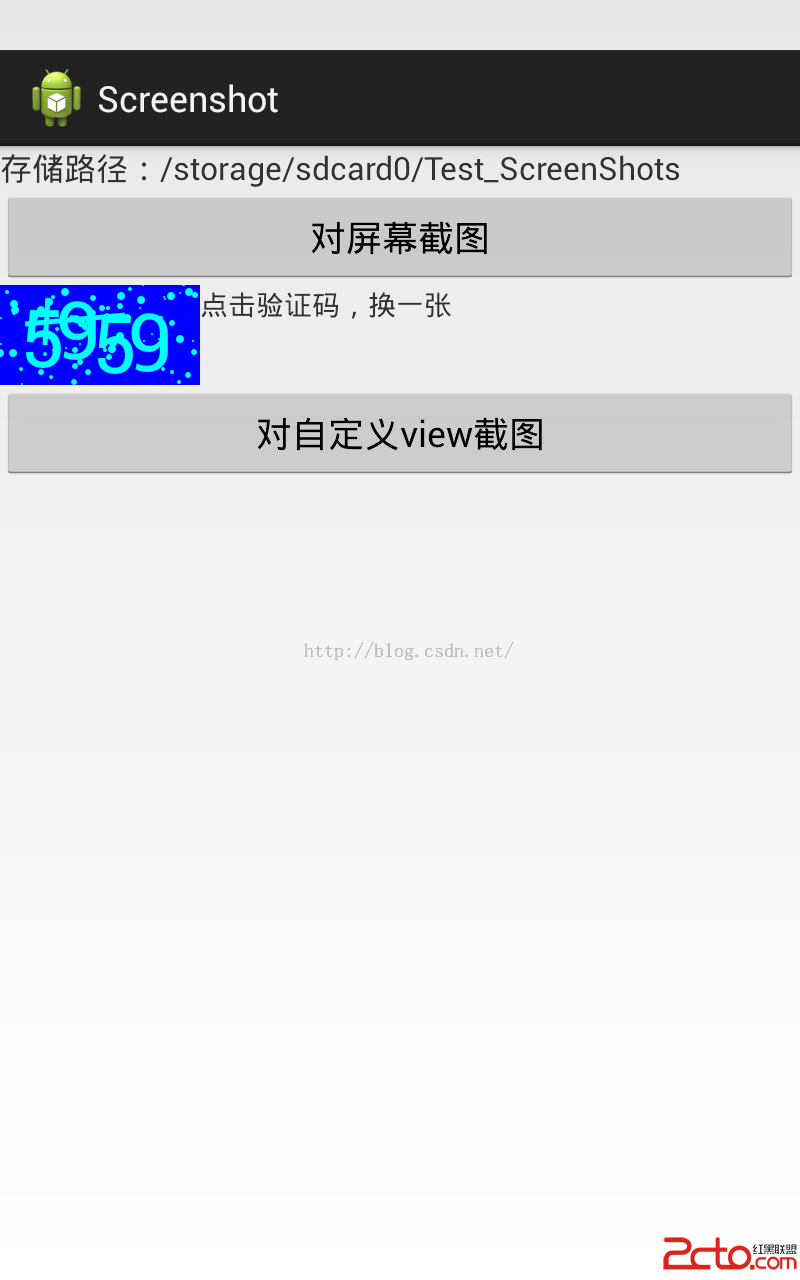 android 關於屏幕截屏的幾種辦法
android 關於屏幕截屏的幾種辦法
年末較閒,就上個星期查找各方面的資料關於android截圖事情,自已也測試一些代碼,已改改進或者優化。接下來進行總結一下。其實,如果真正android系統截屏是需要roo
 Android基礎之——MacOSX下elipse開發環境的配置
Android基礎之——MacOSX下elipse開發環境的配置
前不久換了台macbook,然後自己就把開發環境給配好了,本來這事就這麼過去了,今天有位博友留言讓我寫一篇關於配置的文章,考慮到這個東西確實以後可能還會用,那就寫下來,分
 Android - ScrollView添加提示Arrow(箭頭)
Android - ScrollView添加提示Arrow(箭頭)
ScrollView添加提示Arrow(箭頭) 在ScrollView的滑動功能中,需要給用戶提示,可以滑動,可以添加兩個箭頭。
 Android開源框架Image-Loader詳解
Android開源框架Image-Loader詳解
如果說評價一下哪個圖片開源庫最被廣泛使用的話,我想應該可以說是Universal-Image-Loader,在主流的應用中如果你隨便去反編譯幾個,基本都能看到他的身影,它