一、理論准備
Pull解析器的運行方式與 SAX 解析器相似。它提供了類似的事件,如:開始元素和結束元素事件,使用parser.next()可以進入下一個元素並觸發相應事件。跟SAX不同的是, Pull解析器產生的事件是一個數字,而非方法,因此可以使用一個switch對感興趣的事件進行處理。當元素開始解析時,調用parser.nextText()方法可以獲取下一個Text類型節點的值。
工程結構如下:
image
為什麼把xml放在assets目錄下呢,它和res/values目錄的區別是系統不分配ID,好像沒解決問題,暫時沒查到資料。
二、上代碼
package com.example.and_0003;
import java.io.InputStream;
import java.util.List;
import com.hpu.entity.Student;
import com.hpu.util.PullService;
import android.app.Activity;
import android.content.res.AssetManager;
import android.os.Bundle;
import android.util.Log;
public class MainActivity extends Activity {
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
AssetManager asset = getAssets();
try {
InputStream input = asset.open("student.xml");
List<Student> list = PullService.getStudents(input);
for (Student stu : list) {
Log.e("StudentInfo","Person ID: " + stu.getId() + ","
+ stu.getName() + ", " + stu.getAge() + ", "
+ stu.getSex());
}
} catch (Throwable e) {
e.printStackTrace();
}
}
}
1: <?xml version="1.0" encoding="utf-8"?>
2: <students>
3: <student id="20110806100">
4: <name>小明</name>
5: <age>22</age>
6: <sex>男</sex>
7: </student>
8: <student id="20110806101">
9: <name>小李</name>
10: <age>24</age>
11: <sex>男</sex>
12: </student>
13: <student id="20110806102">
14: <name>小麗</name>
15: <age>21</age>
16: <sex>女</sex>
17: </student>
18: </students>
+ View Code
1: package com.hpu.util;
2:
3: import java.io.InputStream;
4: import java.util.ArrayList;
5: import java.util.List;
6:
7: import org.xmlpull.v1.XmlPullParser;
8: import org.xmlpull.v1.XmlPullParserFactory;
9:
10: import com.hpu.entity.Student;
11:
12: import android.util.Xml;
13:
14: public class PullService {
15:
16: // 采用XmlPullParser來解析XML文件
17: public static List<Student> getStudents(InputStream inStream)
18: throws Throwable {
19: List<Student> students = null;
20: Student mStudent = null;
21:
22: // ========創建XmlPullParser,有兩種方式=======
23: // 方式一:使用工廠類XmlPullParserFactory
24: XmlPullParserFactory pullFactory = XmlPullParserFactory.newInstance();
25: XmlPullParser parser = pullFactory.newPullParser();
26: // 方式二:使用Android提供的實用工具類android.util.Xml
27: // XmlPullParser parser = Xml.newPullParser();
28:
29: // 解析文件輸入流
30: parser.setInput(inStream, "UTF-8");
31: // 產生第一個事件
32: int eventType = parser.getEventType();
33: // 只要不是文檔結束事件,就一直循環
34: while (eventType != XmlPullParser.END_DOCUMENT) {
35: switch (eventType) {
36: // 觸發開始文檔事件
37: case XmlPullParser.START_DOCUMENT:
38: students = new ArrayList<Student>();
39: break;
40: // 觸發開始元素事件
41: case XmlPullParser.START_TAG:
42: // 獲取解析器當前指向的元素的名稱
43: String name = parser.getName();
44: if ("student".equals(name)) {
45: // 通過解析器獲取id的元素值,並設置student的id
46: mStudent = new Student();
47: mStudent.setId(parser.getAttributeValue(0));
48: }
49: if (mStudent != null) {
50: if ("name".equals(name)) {
51: // 獲取解析器當前指向元素的下一個文本節點的值
52: mStudent.setName(parser.nextText());
53: }
54: if ("age".equals(name)) {
55: // 獲取解析器當前指向元素的下一個文本節點的值
56: mStudent.setAge(new Short(parser.nextText()));
57: }
58: if ("sex".equals(name)) {
59: // 獲取解析器當前指向元素的下一個文本節點的值
60: mStudent.setSex(parser.nextText());
61: }
62: }
63: break;
64: // 觸發結束元素事件
65: case XmlPullParser.END_TAG:
66: //
67: if ("student".equals(parser.getName())) {
68: students.add(mStudent);
69: mStudent = null;
70: }
71: break;
72: default:
73: break;
74: }
75: eventType = parser.next();
76: }
77: return students;
78: }
79:
80: }
81:
 Android實現獲取SD卡總容量,可用大小,機身內存總容量及可用大小的方法
Android實現獲取SD卡總容量,可用大小,機身內存總容量及可用大小的方法
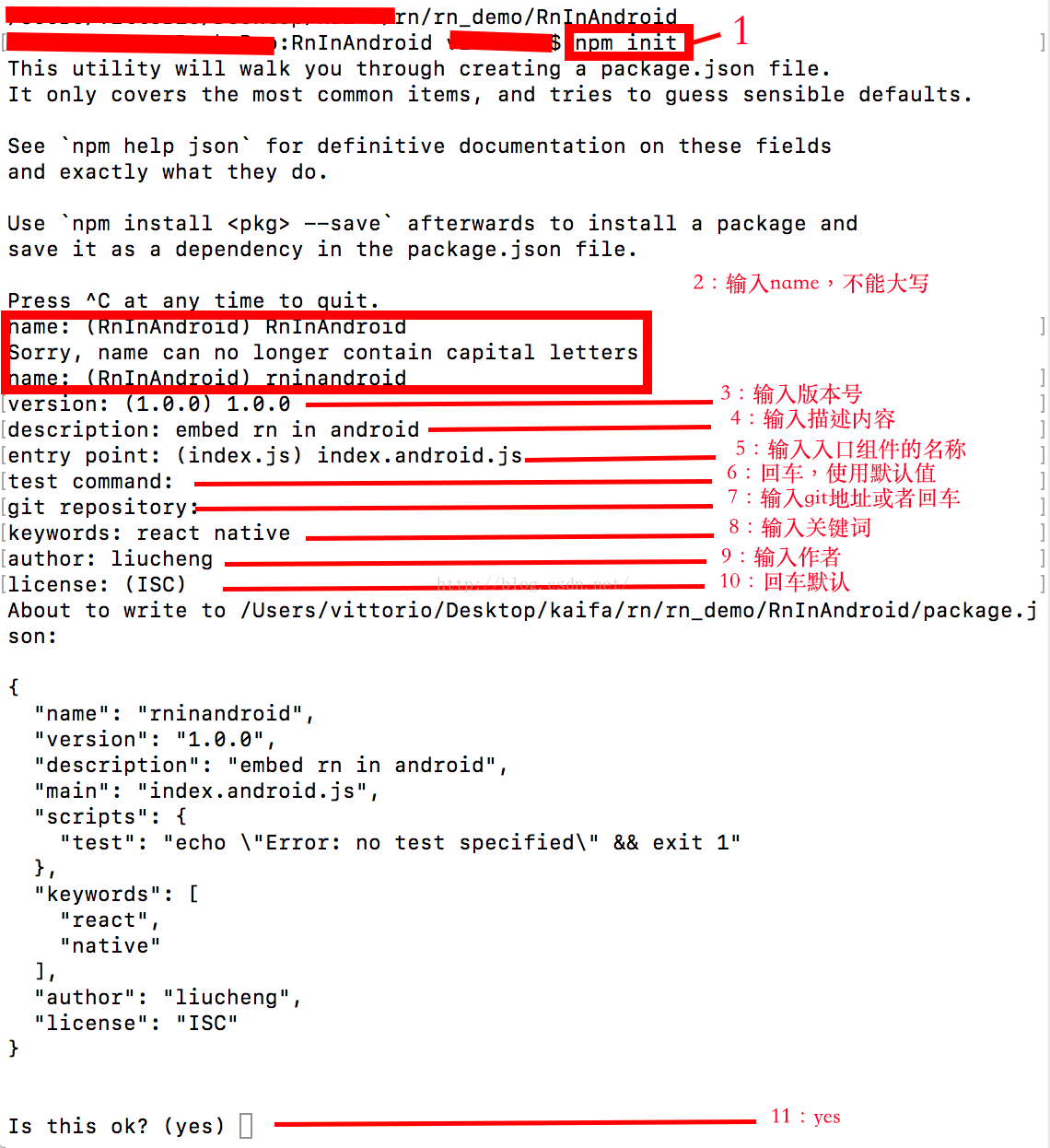 如何把React Native嵌入到原生android應用中
如何把React Native嵌入到原生android應用中
 android設置軟鍵盤搜索鍵以及監聽搜索鍵點擊時發生兩次事件的問題解決
android設置軟鍵盤搜索鍵以及監聽搜索鍵點擊時發生兩次事件的問題解決
 Android仿QQ、新浪相冊的實現
Android仿QQ、新浪相冊的實現