編輯:關於Android編程
XML為一種可擴展的標記語言,是一種簡單的數據存儲語言,使用一系列簡單的標記來描述。
即Simple API for XML,以事件的形式通知程序,對Xml進行解析。
1、首先在Web項目中發布一個XML文檔,名字為persons.xml,具體內容為:
周傑倫 20小明 21
2、SAX解析的流程主要如下:
通過創建SAXParserFactory對象獲得一個實例,然後再通過工廠獲得一個SaxParser,依靠SaxParser的parse方法,完成解析,其中parse方法的參數為一個InputStream類和一個DefaultHandler類,defaultHandler需 要重寫
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser parse = spf.newSAXParser();
Myhandler handler = new Myhandler("person");
parse.parse(is, handler);
list = handler.getList();
3、重寫處理類DefaultHandler。
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class Myhandler extends DefaultHandler {
List> list = null;// 存儲所有的解析對象
String currentTag = null; // 正在解析的標簽
String currentValue = null; // 正在解析元素的值
String nodename = null; // 正在解析節點名稱
HashMap map = null;// 存儲單個解析的完整對象
public Myhandler(String nodename) {
this.nodename = nodename;
}
public List> getList() {
return list;
}
@Override
// 讀到第一個開始標簽的時候觸發
public void startDocument() throws SAXException {
list = new ArrayList>();
}
@Override
// 當遇到所要解析的節點名稱時觸發
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if (qName.equals(nodename)) {
map = new HashMap();
}
if (attributes != null && map != null) {
for (int i = 0; i < attributes.getLength(); i++) {
map.put(attributes.getQName(i), attributes.getValue(i));
}
}
currentTag = qName;
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if (qName.equals(nodename)) {
list.add(map);
map = null;
}
super.endElement(uri, localName, qName);
}
@Override
// 處理xml文件讀取到的內容
public void characters(char[] ch, int start, int length)
throws SAXException {
if (currentTag != null && map != null) {
currentValue = new String(ch, start, length);
if (currentValue != null && !currentValue.trim().equals("")
&& !currentValue.trim().equals("\n")) {
map.put(currentTag, currentValue);
}
}
currentTag = null;
currentValue = null;
}
}
4、通過自定義的HttpUtils類,從服務器獲取數據,以流的形式返回,也就是XML文檔的輸入流,這裡不再給出,關於獲得服務器數據的三種方式下次會下次更新。
5、最後通過返回的List
類似於SAX方式,程序以“拉取”的方式對Xml進行解析。
1、與SAX解析類似,但比SAX解析容易,需要JAR包,下載地址:
http://pan.baidu.com/s/1hq3JnKg
2、首先通過XMLPullFactory創建一個工廠,然後再由工廠創建一個XMLPullParser對象,由對象進行相關處理。
3、通過對eventType進行XML文件的節點解析,獲得數據,並存放在List中進行返回。
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
import org.xmlpull.v1.XmlPullParserFactory;
public class PullXmlHandler {
public static List parseXml(InputStream is, String encode)
throws Exception {
List list = null;
Person p = null;
try {
XmlPullParserFactory xmlPullF = XmlPullParserFactory.newInstance();
XmlPullParser parser = xmlPullF.newPullParser();
parser.setInput(is, encode);
int eventType = parser.getEventType();
//如果還沒到文檔結束節點就一直循環
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
list = new ArrayList();
break;
case XmlPullParser.START_TAG:
if (parser.getName().equals("person")) {
p = new Person();
if (parser.getAttributeCount() != 0) {
p.setId(parser.getAttributeValue(0));
}
} else if (parser.getName().equals("name")) {
p.setName(parser.nextText());
} else if (parser.getName().equals("age")) {
p.setAge(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if (parser.getName().equals("person")) {
list.add(p);
p = null;
}
break;
default:
break;
}
//進行下次循環
eventType = parser.next();
}
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return list;
}
}
“文檔對象模型”方式,解析完的Xml將生成一個樹狀結構的對象。
1、DOM解析相對前兩種比較麻煩,代碼如下:
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import com.xml.httputils.http_post;
public class DomService {
public DomService() {
}
public static List parseXML(InputStream is) throws Exception {
List list = new ArrayList();
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(is);
// 獲得節點
Element element = document.getDocumentElement();
NodeList nodeList = element.getElementsByTagName("person");
for (int i = 0; i < nodeList.getLength(); i++) {
Element personElement = (Element) nodeList.item(i);
Person p = new Person();
p.setId(personElement.getAttribute("id"));
NodeList personList = personElement.getChildNodes();
for (int j = 0; j < personList.getLength(); j++) {
if (personList.item(j).getNodeType() == Node.ELEMENT_NODE) {
if ("name".equals(personList.item(j).getNodeName())) {
p.setName(personList.item(j).getFirstChild()
.getNodeValue());
} else if ("age".equals(personList.item(j).getNodeName())) {
p.setAge(personList.item(j).getFirstChild()
.getNodeValue());
}
}
}
list.add(p);
}
return list;
}
public static void main(String[] args) throws Exception {
DomService dom = new DomService();
List ps = dom.parseXML(http_post.getXMLStream());
for (Person p : ps) {
System.out.println(p);
}
}
}
對於小內存的設備,尤其是Android設備,使用PULL解析或者SAX解析遠優於DOM解析。
 android圖片加載庫Glide
android圖片加載庫Glide
什麼是Glide?Glide是一個加載圖片的庫,作者是bumptech,它是在泰國舉行的google 開發者論壇上google為我們介紹的,這個庫被廣泛的運用在googl
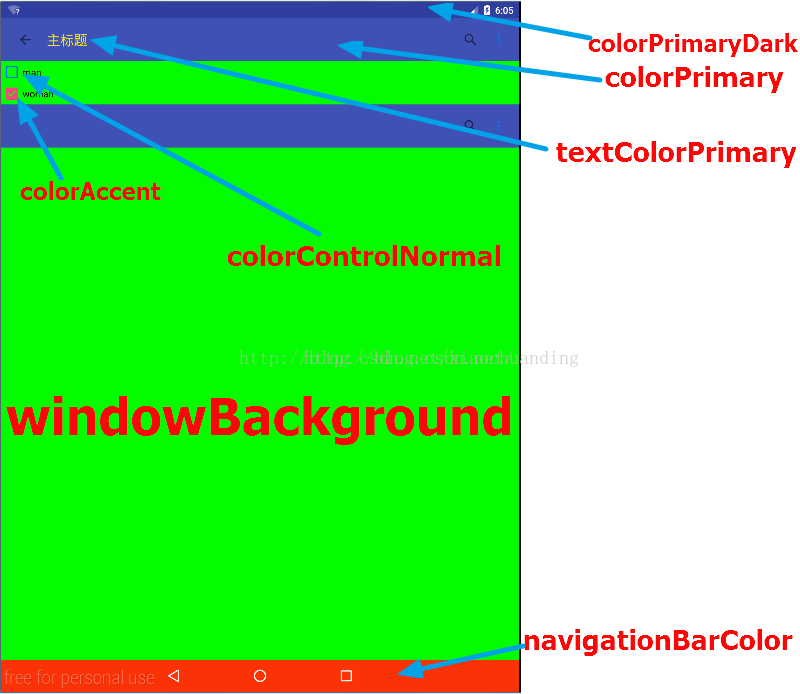 android 5.0 界面常用的顏色屬性
android 5.0 界面常用的顏色屬性
android 5.0 以後,app可以在styles.xml中通過設置主題theme的顏色來設置指定的Activity或者整個app的顯示的顏色,一直對幾個屬性混淆,這
 android 自定義組合控件
android 自定義組合控件
自定義控件是一些android程序員感覺很難攻破的難點,起碼對我來說是這樣的,但是我們可以在網上找一些好的博客關於自定義控件好好拿過來學習研究下,多練,多寫點也能找到感覺
 Android開發本地及網絡Mp3音樂播放器(六)實現獨立音樂播放界面
Android開發本地及網絡Mp3音樂播放器(六)實現獨立音樂播放界面
實現功能:功能1:點擊MyMusicListFragment(本地音樂)底部UI中的專輯封面圖片打開的PlayActivity(獨立音樂播放界面)PlayActivity