編輯:關於Android編程
上篇blog說到了經過對文件夾進行掃描如果後綴符合系統設定的一些格式,那麼就會進行文件內容掃描下面我們緊接著STEP 14中的
[cpp]
status_t StagefrightMediaScanner::processFile(
const char *path, const char *mimeType,
MediaScannerClient &client) {
LOGV("processFile '%s'.", path);
client.setLocale(locale());
client.beginFile();
const char *extension = strrchr(path, '.');
if (!extension) {
return UNKNOWN_ERROR;
}
if (!FileHasAcceptableExtension(extension)) {
client.endFile();
return UNKNOWN_ERROR;
}
if (!strcasecmp(extension, ".mid")
|| !strcasecmp(extension, ".smf")
|| !strcasecmp(extension, ".imy")
|| !strcasecmp(extension, ".midi")
|| !strcasecmp(extension, ".xmf")
|| !strcasecmp(extension, ".rtttl")
|| !strcasecmp(extension, ".rtx")
|| !strcasecmp(extension, ".ota")) {
return HandleMIDI(path, &client);
}
if (mRetriever->setDataSource(path) == OK) {
const char *value;
if ((value = mRetriever->extractMetadata(
METADATA_KEY_MIMETYPE)) != NULL) {
client.setMimeType(value);
}
struct KeyMap {
const char *tag;
int key;
};
static const KeyMap kKeyMap[] = {
{ "tracknumber", METADATA_KEY_CD_TRACK_NUMBER },
{ "discnumber", METADATA_KEY_DISC_NUMBER },
{ "album", METADATA_KEY_ALBUM },
{ "artist", METADATA_KEY_ARTIST },
{ "albumartist", METADATA_KEY_ALBUMARTIST },
{ "composer", METADATA_KEY_COMPOSER },
{ "genre", METADATA_KEY_GENRE },
{ "title", METADATA_KEY_TITLE },
{ "year", METADATA_KEY_YEAR },
{ "duration", METADATA_KEY_DURATION },
{ "writer", METADATA_KEY_WRITER },
{ "compilation", METADATA_KEY_COMPILATION },
};
static const size_t kNumEntries = sizeof(kKeyMap) / sizeof(kKeyMap[0]);
for (size_t i = 0; i < kNumEntries; ++i) {
const char *value;
if ((value = mRetriever->extractMetadata(kKeyMap[i].key)) != NULL) {
client.addStringTag(kKeyMap[i].tag, value);
}
}
}
client.endFile();
return OK;
}
status_t StagefrightMediaScanner::processFile(
const char *path, const char *mimeType,
MediaScannerClient &client) {
LOGV("processFile '%s'.", path);
client.setLocale(locale());
client.beginFile();
const char *extension = strrchr(path, '.');
if (!extension) {
return UNKNOWN_ERROR;
}
if (!FileHasAcceptableExtension(extension)) {
client.endFile();
return UNKNOWN_ERROR;
}
if (!strcasecmp(extension, ".mid")
|| !strcasecmp(extension, ".smf")
|| !strcasecmp(extension, ".imy")
|| !strcasecmp(extension, ".midi")
|| !strcasecmp(extension, ".xmf")
|| !strcasecmp(extension, ".rtttl")
|| !strcasecmp(extension, ".rtx")
|| !strcasecmp(extension, ".ota")) {
return HandleMIDI(path, &client);
}
if (mRetriever->setDataSource(path) == OK) {
const char *value;
if ((value = mRetriever->extractMetadata(
METADATA_KEY_MIMETYPE)) != NULL) {
client.setMimeType(value);
}
struct KeyMap {
const char *tag;
int key;
};
static const KeyMap kKeyMap[] = {
{ "tracknumber", METADATA_KEY_CD_TRACK_NUMBER },
{ "discnumber", METADATA_KEY_DISC_NUMBER },
{ "album", METADATA_KEY_ALBUM },
{ "artist", METADATA_KEY_ARTIST },
{ "albumartist", METADATA_KEY_ALBUMARTIST },
{ "composer", METADATA_KEY_COMPOSER },
{ "genre", METADATA_KEY_GENRE },
{ "title", METADATA_KEY_TITLE },
{ "year", METADATA_KEY_YEAR },
{ "duration", METADATA_KEY_DURATION },
{ "writer", METADATA_KEY_WRITER },
{ "compilation", METADATA_KEY_COMPILATION },
};
static const size_t kNumEntries = sizeof(kKeyMap) / sizeof(kKeyMap[0]);
for (size_t i = 0; i < kNumEntries; ++i) {
const char *value;
if ((value = mRetriever->extractMetadata(kKeyMap[i].key)) != NULL) {
client.addStringTag(kKeyMap[i].tag, value);
}
}
}
client.endFile();
return OK;
}來進行代碼跟進說明,首先StagefrightMediaScanner是Stagefright的一部分,它負責媒體掃描工作,而stagefright是整個android系統media處理的框架,包括音視頻的播放。
mRetriever->setDataSource(path),mRetriever是在StagefrightMediaScanner的構造函數中創建的
[cpp]
StagefrightMediaScanner::StagefrightMediaScanner()
: mRetriever(new MediaMetadataRetriever) {
}
StagefrightMediaScanner::StagefrightMediaScanner()
: mRetriever(new MediaMetadataRetriever) {
}STEP15
[cpp]
status_t MediaMetadataRetriever::setDataSource(const char* srcUrl)
{
LOGV("setDataSource");
Mutex::Autolock _l(mLock);
if (mRetriever == 0) {
LOGE("retriever is not initialized");
return INVALID_OPERATION;
}
if (srcUrl == NULL) {
LOGE("data source is a null pointer");
return UNKNOWN_ERROR;
}
LOGV("data source (%s)", srcUrl);
return mRetriever->setDataSource(srcUrl);
}
status_t MediaMetadataRetriever::setDataSource(const char* srcUrl)
{
LOGV("setDataSource");
Mutex::Autolock _l(mLock);
if (mRetriever == 0) {
LOGE("retriever is not initialized");
return INVALID_OPERATION;
}
if (srcUrl == NULL) {
LOGE("data source is a null pointer");
return UNKNOWN_ERROR;
}
LOGV("data source (%s)", srcUrl);
return mRetriever->setDataSource(srcUrl);
}
再看下MediaMetadataRetriever裡面的mRetriever也是在MediaMetadataRetriever的構造函數中創建的。並且是通過MediaPlayerService來創建,實際就是創建的StagefrightMetadataRetriever對象。緊接著看StagefrightMetadataRetriever的setDataSource函數
STEP15
[cpp]
status_t StagefrightMetadataRetriever::setDataSource(const char *uri) {
LOGV("setDataSource(%s)", uri);
mParsedMetaData = false;
mMetaData.clear();
delete mAlbumArt;
mAlbumArt = NULL;
mSource = DataSource::CreateFromURI(uri);
if (mSource == NULL) {
return UNKNOWN_ERROR;
}
mExtractor = MediaExtractor::Create(mSource);
if (mExtractor == NULL) {
mSource.clear();
return UNKNOWN_ERROR;
}
return OK;
}
status_t StagefrightMetadataRetriever::setDataSource(const char *uri) {
LOGV("setDataSource(%s)", uri);
mParsedMetaData = false;
mMetaData.clear();
delete mAlbumArt;
mAlbumArt = NULL;
mSource = DataSource::CreateFromURI(uri);
if (mSource == NULL) {
return UNKNOWN_ERROR;
}
mExtractor = MediaExtractor::Create(mSource);
if (mExtractor == NULL) {
mSource.clear();
return UNKNOWN_ERROR;
}
return OK;
}
有閱讀過stagefright源碼的同學可能看到這個地方就會感覺很熟悉,首先根據URI創建了一個DataSource DataSource::CreateFromURI(uri);DataSource我們實際可以將它理解為文件的源,它裡面會先把文件打開,然後對文件描述符進行讀取操作。
看源碼可以知道它會創建一個FileSource。然後根據這個DataSource創建一個MediaExtractor::Create(mSource); MediaExtractor就是文件解析器
STEP16
[cpp]
sp<MediaExtractor> MediaExtractor::Create(
const sp<DataSource> &source, const char *mime) {
sp<AMessage> meta;
String8 tmp;
if (mime == NULL) {
float confidence;
if (!source->sniff(&tmp, &confidence, &meta)) {
LOGV("FAILED to autodetect media content.");
return NULL;
}
mime = tmp.string();
LOGV("Autodetected media content as '%s' with confidence %.2f",
mime, confidence);
}
if (!strcasecmp(mime, MEDIA_MIMETYPE_CONTAINER_MPEG4)
|| !strcasecmp(mime, "audio/mp4")) {
return new MPEG4Extractor(source);
}
...
}
...
}
sp<MediaExtractor> MediaExtractor::Create(
const sp<DataSource> &source, const char *mime) {
sp<AMessage> meta;
String8 tmp;
if (mime == NULL) {
float confidence;
if (!source->sniff(&tmp, &confidence, &meta)) {
LOGV("FAILED to autodetect media content.");
return NULL;
}
mime = tmp.string();
LOGV("Autodetected media content as '%s' with confidence %.2f",
mime, confidence);
}
if (!strcasecmp(mime, MEDIA_MIMETYPE_CONTAINER_MPEG4)
|| !strcasecmp(mime, "audio/mp4")) {
return new MPEG4Extractor(source);
}
...
}
...
}這裡面有一個很關鍵的函數source->sniff(&tmp, &confidence, &meta),字面上看就是嗅探的意思,非常形象,DataSource裡面有一個sniff函數
STEP 17
[cpp]
bool DataSource::sniff(
String8 *mimeType, float *confidence, sp<AMessage> *meta) {
*mimeType = "";
*confidence = 0.0f;
meta->clear();
Mutex::Autolock autoLock(gSnifferMutex);
for (List<SnifferFunc>::iterator it = gSniffers.begin();
it != gSniffers.end(); ++it) {
String8 newMimeType;
float newConfidence;
sp<AMessage> newMeta;
if ((*it)(this, &newMimeType, &newConfidence, &newMeta)) {
if (newConfidence > *confidence) {
*mimeType = newMimeType;
*confidence = newConfidence;
*meta = newMeta;
}
}
}
return *confidence > 0.0;
}
bool DataSource::sniff(
String8 *mimeType, float *confidence, sp<AMessage> *meta) {
*mimeType = "";
*confidence = 0.0f;
meta->clear();
Mutex::Autolock autoLock(gSnifferMutex);
for (List<SnifferFunc>::iterator it = gSniffers.begin();
it != gSniffers.end(); ++it) {
String8 newMimeType;
float newConfidence;
sp<AMessage> newMeta;
if ((*it)(this, &newMimeType, &newConfidence, &newMeta)) {
if (newConfidence > *confidence) {
*mimeType = newMimeType;
*confidence = newConfidence;
*meta = newMeta;
}
}
}
return *confidence > 0.0;
}gSniffers是一個系統支持的一些媒體格式的嗅探器列表,函數的作用就是用這些嗅探器一個一個的試,並給出一個confidence 信任值,也就是說值越高,它就越可能是這種格式。而這些嗅探器是在StagefrightMetadataRetriever的構造函數中注冊的 DataSource::RegisterDefaultSniffers();
我們可以挑選其中的SniffMPEG4來看看,嗅探器都是在對應格式的文件解析器中,SniffMPEG4在MPEG4Extractor中。
[cpp]
bool SniffMPEG4(
const sp<DataSource> &source, String8 *mimeType, float *confidence,
sp<AMessage> *) {
if (BetterSniffMPEG4(source, mimeType, confidence)) {
return true;
}
if (LegacySniffMPEG4(source, mimeType, confidence)) {
LOGW("Identified supported mpeg4 through LegacySniffMPEG4.");
return true;
}
const char LegacyAtom[][8]={
{"moov"},
{"mvhd"},
{"trak"},
};
uint8_t header[12];
if (source->readAt(0, header, 12) != 12){
return false;
}
for(int i=0; i<sizeof(LegacyAtom)/sizeof(LegacyAtom[0]);i++){
if (!memcmp(LegacyAtom[i], &header[4], strlen(LegacyAtom[i]))) {
*mimeType = MEDIA_MIMETYPE_CONTAINER_MPEG4;
*confidence = 0.4f;
return true;
}
}
return false;
}
bool SniffMPEG4(
const sp<DataSource> &source, String8 *mimeType, float *confidence,
sp<AMessage> *) {
if (BetterSniffMPEG4(source, mimeType, confidence)) {
return true;
}
if (LegacySniffMPEG4(source, mimeType, confidence)) {
LOGW("Identified supported mpeg4 through LegacySniffMPEG4.");
return true;
}
const char LegacyAtom[][8]={
{"moov"},
{"mvhd"},
{"trak"},
};
uint8_t header[12];
if (source->readAt(0, header, 12) != 12){
return false;
}
for(int i=0; i<sizeof(LegacyAtom)/sizeof(LegacyAtom[0]);i++){
if (!memcmp(LegacyAtom[i], &header[4], strlen(LegacyAtom[i]))) {
*mimeType = MEDIA_MIMETYPE_CONTAINER_MPEG4;
*confidence = 0.4f;
return true;
}
}
return false;
}
這裡面涉及到幾個函數BetterSniffMPEG4 LegacySniffMPEG4 這實際是一步一步來根據MEPG4的格式來試探這個文件是否符合MPEG4。
在這就不多講了,想看懂這兩個函數,你必須看MPEG4格式的標准文檔。
拿到打分後也就知道了media的format,然後就根據這個類型創建一個MediaExtractor。回到STEP14,mRetriever->setDataSource(path)所有動作已經完成,總結下就是根據android設備支持的媒體格式一個一個的試,然後得到一個和該文件最相符的格式。到此實際解析工作已經做完,下面一步是將得到的格式會送給java層,
[cpp]
if ((value = mRetriever->extractMetadata(
METADATA_KEY_MIMETYPE)) != NULL) {
client.setMimeType(value);
}
if ((value = mRetriever->extractMetadata(
METADATA_KEY_MIMETYPE)) != NULL) {
client.setMimeType(value);
}
就是完成這個動作。然後有一個kKeyMap,這些實際就是我們需要存儲於數據庫中的媒體信息,包括時長,專輯之類的東西。也是通過mRetriever->extractMetadata函數得到。
STEP18
[cpp]
const char *StagefrightMetadataRetriever::extractMetadata(int keyCode) {
if (mExtractor == NULL) {
return NULL;
}
if (!mParsedMetaData) {
parseMetaData();
mParsedMetaData = true;
}
ssize_t index = mMetaData.indexOfKey(keyCode);
if (index < 0) {
return NULL;
}
return strdup(mMetaData.valueAt(index).string());
const char *StagefrightMetadataRetriever::extractMetadata(int keyCode) {
if (mExtractor == NULL) {
return NULL;
}
if (!mParsedMetaData) {
parseMetaData();
mParsedMetaData = true;
}
ssize_t index = mMetaData.indexOfKey(keyCode);
if (index < 0) {
return NULL;
}
return strdup(mMetaData.valueAt(index).string());
首次調用肯定是進入parseMetaData,這個函數完成解析工作,將所有需要的媒體信息全部從文件中讀出來並保存到mMetaData這個鍵值對數組中。
具體解析工作也不說了,跟具體的格式相關。
下面最重要的一步就是將解析後得到的信息反饋給java層client.addStringTag(kKeyMap[i].tag, value);
STEP19
[cpp]
bool MediaScannerClient::addStringTag(const char* name, const char* value)
{
if (mLocaleEncoding != kEncodingNone) {
// don't bother caching strings that are all ASCII.
// call handleStringTag directly instead.
// check to see if value (which should be utf8) has any non-ASCII characters
bool nonAscii = false;
const char* chp = value;
char ch;
while ((ch = *chp++)) {
if (ch & 0x80) {
nonAscii = true;
break;
}
}
if (nonAscii) {
// save the strings for later so they can be used for native encoding detection
mNames->push_back(name);
mValues->push_back(value);
return true;
}
// else fall through
}
// autodetection is not necessary, so no need to cache the values
// pass directly to the client instead
return handleStringTag(name, value);
}
bool MediaScannerClient::addStringTag(const char* name, const char* value)
{
if (mLocaleEncoding != kEncodingNone) {
// don't bother caching strings that are all ASCII.
// call handleStringTag directly instead.
// check to see if value (which should be utf8) has any non-ASCII characters
bool nonAscii = false;
const char* chp = value;
char ch;
while ((ch = *chp++)) {
if (ch & 0x80) {
nonAscii = true;
break;
}
}
if (nonAscii) {
// save the strings for later so they can be used for native encoding detection
mNames->push_back(name);
mValues->push_back(value);
return true;
}
// else fall through
}
// autodetection is not necessary, so no need to cache the values
// pass directly to the client instead
return handleStringTag(name, value);
}
直接看handleStringTag根據上面的經驗,直接看java層的MyMediaScannerClient的handleStringTag函數
STEP 20
[java]
public void handleStringTag(String name, String value) {
if (name.equalsIgnoreCase("title") || name.startsWith("title;")) {
// Don't trim() here, to preserve the special \001 character
// used to force sorting. The media provider will trim() before
// inserting the title in to the database.
mTitle = value;
} else if (name.equalsIgnoreCase("artist") || name.startsWith("artist;")) {
mArtist = value.trim();
} else if (name.equalsIgnoreCase("albumartist") || name.startsWith("albumartist;")) {
mAlbumArtist = value.trim();
} else if (name.equalsIgnoreCase("album") || name.startsWith("album;")) {
mAlbum = value.trim();
} else if (name.equalsIgnoreCase("composer") || name.startsWith("composer;")) {
mComposer = value.trim();
} else if (name.equalsIgnoreCase("genre") || name.startsWith("genre;")) {
// handle numeric genres, which PV sometimes encodes like "(20)"
if (value.length() > 0) {
int genreCode = -1;
char ch = value.charAt(0);
if (ch == '(') {
genreCode = parseSubstring(value, 1, -1);
} else if (ch >= '0' && ch <= '9') {
genreCode = parseSubstring(value, 0, -1);
}
if (genreCode >= 0 && genreCode < ID3_GENRES.length) {
value = ID3_GENRES[genreCode];
} else if (genreCode == 255) {
// 255 is defined to be unknown
value = null;
}
}
mGenre = value;
} else if (name.equalsIgnoreCase("year") || name.startsWith("year;")) {
mYear = parseSubstring(value, 0, 0);
} else if (name.equalsIgnoreCase("tracknumber") || name.startsWith("tracknumber;")) {
// track number might be of the form "2/12"
// we just read the number before the slash
int num = parseSubstring(value, 0, 0);
mTrack = (mTrack / 1000) * 1000 + num;
} else if (name.equalsIgnoreCase("discnumber") ||
name.equals("set") || name.startsWith("set;")) {
// set number might be of the form "1/3"
// we just read the number before the slash
int num = parseSubstring(value, 0, 0);
mTrack = (num * 1000) + (mTrack % 1000);
} else if (name.equalsIgnoreCase("duration")) {
mDuration = parseSubstring(value, 0, 0);
} else if (name.equalsIgnoreCase("writer") || name.startsWith("writer;")) {
mWriter = value.trim();
} else if (name.equalsIgnoreCase("compilation")) {
mCompilation = parseSubstring(value, 0, 0);
}
}
public void handleStringTag(String name, String value) {
if (name.equalsIgnoreCase("title") || name.startsWith("title;")) {
// Don't trim() here, to preserve the special \001 character
// used to force sorting. The media provider will trim() before
// inserting the title in to the database.
mTitle = value;
} else if (name.equalsIgnoreCase("artist") || name.startsWith("artist;")) {
mArtist = value.trim();
} else if (name.equalsIgnoreCase("albumartist") || name.startsWith("albumartist;")) {
mAlbumArtist = value.trim();
} else if (name.equalsIgnoreCase("album") || name.startsWith("album;")) {
mAlbum = value.trim();
} else if (name.equalsIgnoreCase("composer") || name.startsWith("composer;")) {
mComposer = value.trim();
} else if (name.equalsIgnoreCase("genre") || name.startsWith("genre;")) {
// handle numeric genres, which PV sometimes encodes like "(20)"
if (value.length() > 0) {
int genreCode = -1;
char ch = value.charAt(0);
if (ch == '(') {
genreCode = parseSubstring(value, 1, -1);
} else if (ch >= '0' && ch <= '9') {
genreCode = parseSubstring(value, 0, -1);
}
if (genreCode >= 0 && genreCode < ID3_GENRES.length) {
value = ID3_GENRES[genreCode];
} else if (genreCode == 255) {
// 255 is defined to be unknown
value = null;
}
}
mGenre = value;
} else if (name.equalsIgnoreCase("year") || name.startsWith("year;")) {
mYear = parseSubstring(value, 0, 0);
} else if (name.equalsIgnoreCase("tracknumber") || name.startsWith("tracknumber;")) {
// track number might be of the form "2/12"
// we just read the number before the slash
int num = parseSubstring(value, 0, 0);
mTrack = (mTrack / 1000) * 1000 + num;
} else if (name.equalsIgnoreCase("discnumber") ||
name.equals("set") || name.startsWith("set;")) {
// set number might be of the form "1/3"
// we just read the number before the slash
int num = parseSubstring(value, 0, 0);
mTrack = (num * 1000) + (mTrack % 1000);
} else if (name.equalsIgnoreCase("duration")) {
mDuration = parseSubstring(value, 0, 0);
} else if (name.equalsIgnoreCase("writer") || name.startsWith("writer;")) {
mWriter = value.trim();
} else if (name.equalsIgnoreCase("compilation")) {
mCompilation = parseSubstring(value, 0, 0);
}
}這裡並沒有直接寫數據庫,而是暫時保存在成員變量中。接著回到STEP 11中,我們說到doScanFile的processFile,將文件解析處理並將信息上報上來存到成員變量中後,最後一步result = endFile(entry, ringtones, notifications, alarms, music, podcasts);肯定就得寫數據庫了。
STEP21
[java]
private Uri endFile(FileCacheEntry entry, boolean ringtones, boolean notifications,
boolean alarms, boolean music, boolean podcasts)
throws RemoteException {
. . .
}
private Uri endFile(FileCacheEntry entry, boolean ringtones, boolean notifications,
boolean alarms, boolean music, boolean podcasts)
throws RemoteException {
. . .
}
此函數篇幅太長,就不貼出來。有興趣的同學可以仔細瞧瞧這段代碼,它就是將前面解析出來的信息通過MediaProvider寫入數據庫的。
當然,寫入的時候會區分成好多個表,每個表都有不同的列,有興趣可以adb shell 進入你的android手機看看/data/data/com.android.providers.media/databases這個目錄下面是不是有幾個數據庫,internel.db、external.db等如果你熟練sqlite3命令可以看下這些數據庫中的內容,我看了下我手機中的外置卡數據庫中有哪些表
[plain]
qlite> .tables
.tables
album_art audio search
album_info audio_genres searchhelpertitle
albums audio_genres_map thumbnails
android_metadata audio_meta video
artist_info audio_playlists videothumbnails
artists audio_playlists_map
artists_albums_map images
sqlite> .tables
.tables
album_art audio search
album_info audio_genres searchhelpertitle
albums audio_genres_map thumbnails
android_metadata audio_meta video
artist_info audio_playlists videothumbnails
artists audio_playlists_map
artists_albums_map images看看有這麼多,分別存儲了不同種類的信息。
至於數據庫的操作以及ContentProvider的使用就不多說了,下面總結如下:
系統開機或者收到掛載消息後,MediaProvider程序會掃描sdcard(內外置區分),根據系統支持的文件類型的後綴先將文件過濾一遍,將得到的符合條件的文件再深入讀文件內容解析,看到底是什麼格式,並且將文件的一些重要信息讀取出來,最後保存於數據庫中,方便其他應用程序使用。我分析的是原生的android2.3的代碼,可能其他版本有所改變。這樣看的話,如果你把文件的後綴名改一下系統也許就掃描不出來了哦,大家可以試試!!!
 Android 網絡開發框架的選擇
Android 網絡開發框架的選擇
在看android基礎的時候,關於網絡操作一般都會介紹HttpClient以及HttpConnection這兩個包。前者是apache的開源庫,後者是android自帶的
 Android知識普及
Android知識普及
hybrid app編輯 Hybrid App(混合模式移動應用)是指介於web-app、native-app這兩者之間的app,兼具“Native App良
 android 學習教程六之----四大組件之一——BroadcastReciever
android 學習教程六之----四大組件之一——BroadcastReciever
博客好長時間沒有更新了,做個基礎總結,繼續之前的,溫故而知新!該系列為入門篇,大神可以繞道! 大家好,今天給大家詳
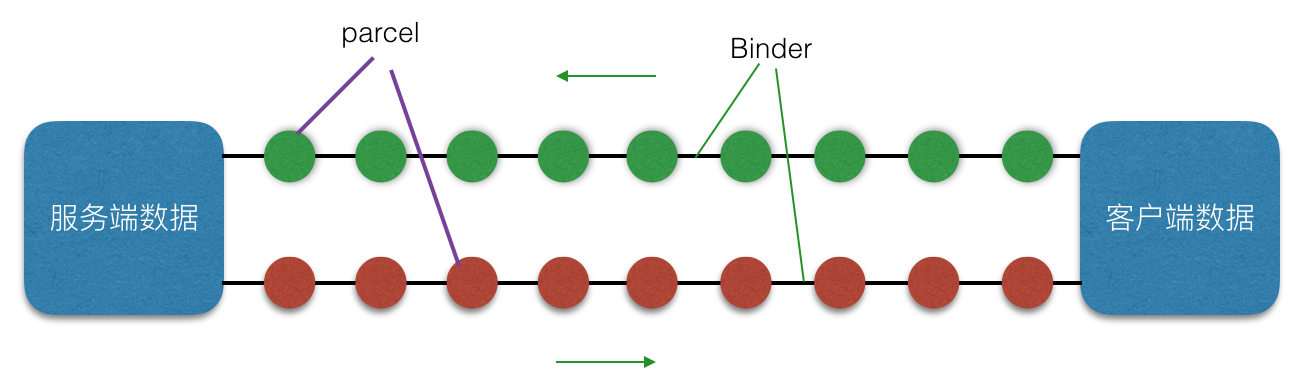 Android AIDL——進程通信機制詳解
Android AIDL——進程通信機制詳解
Android AIDL, Android進程機制通信機制,這裡就整理下AIDL 的知識,幫助大家學習理解此部分知識!什麼是 AIDLAIDL 全稱 Andr