采用DOM解析時具體處理步驟是:
1 首先利用DocumentBuilderFactory創建一個DocumentBuilderFactory實例
2 然後利用DocumentBuilderFactory創建DocumentBuilder
3 然後加載XML文檔(Document),
4 然後獲取文檔的根結點(Element),
5 然後獲取根結點中所有子節點的列表(NodeList),
6 然後使用再獲取子節點列表中的需要讀取的結點。
采用SAX解析時具體處理步驟是:
1 創建SAXParserFactory對象
2 根據SAXParserFactory.newSAXParser()方法返回一個SAXParser解析器
3 根據SAXParser解析器獲取事件源對象XMLReader
4 實例化一個DefaultHandler對象
5 連接事件源對象XMLReader到事件處理類DefaultHandler中
6 調用XMLReader的parse方法從輸入源中獲取到的xml數據
7 通過DefaultHandler返回我們需要的數據集合。
采用PULL解析基本處理方式:
1:當導航到XmlPullParser.START_DOCUMENT,可以不做處理,當然你可以實例化集合對象等等。
2:當導航到XmlPullParser.START_TAG,則判斷是否是river標簽,如果是,則實例化river對象,並調用getAttributeValue方法獲取標簽中屬性值。
3:當導航到其他標簽,比如Introduction時候,則判斷river對象是否為空,如不為空,則取出Introduction中的內容,nextText方法來獲取文本節點內容
4:它一定會導航到XmlPullParser.END_TAG的,有開始就要有結束嘛。在這裡我們就需要判讀是否是river結束標簽,如果是,則把river對象存進list集合中了,並設置river對象為null.
幾種解析技術的比較與總結:
對於Android的移動設備而言,因為設備的資源比較寶貴,內存是有限的,所以我們需要選擇適合的技術來解析XML,這樣有利於提高訪問的速度。
1 DOM在處理XML文件時,將XML文件解析成樹狀結構並放入內存中進行處理。當XML文件較小時,我們可以選DOM,因為它簡單、直觀。www.2cto.com
2 SAX則是以事件作為解析XML文件的模式,它將XML文件轉化成一系列的事件,由不同的事件處理器來決定如何處理。XML文件較大時,選擇SAX技術是比較合理的。雖然代碼量有些大,但是它不需要將所有的XML文件加載到內存中。這樣對於有限的Android內存更有效,而且Android提供了一種傳統的SAX使用方法以及一個便捷的SAX包裝器。
3 XML pull解析並未像SAX解析那樣監聽元素的結束,而是在開始處完成了大部分處理。這有利於提早讀取XML文件,可以極大的減少解析時間,這種優化對於連接速度較漫的移動設備而言尤為重要。對於XML文檔較大但只需要文檔的一部分時,XML Pull解析器則是更為有效的方法。
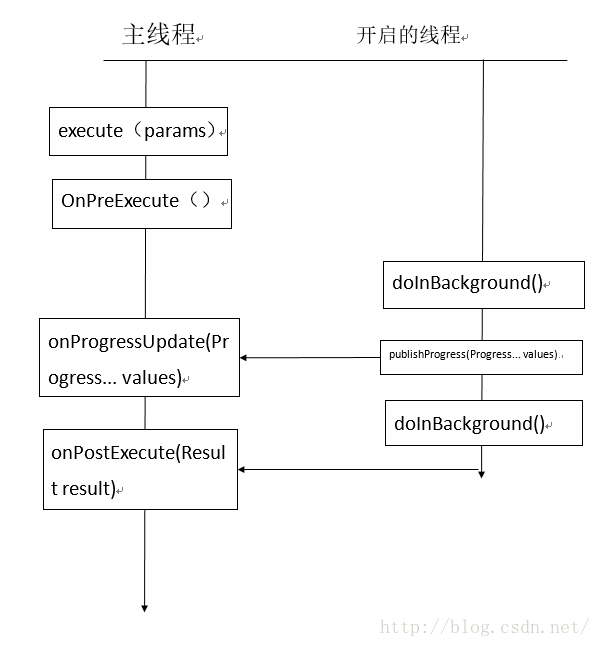 AsyncTask介紹
AsyncTask介紹
 DELPHI XE Android 開發筆記
DELPHI XE Android 開發筆記
 Android開發--React-Native之初體驗
Android開發--React-Native之初體驗
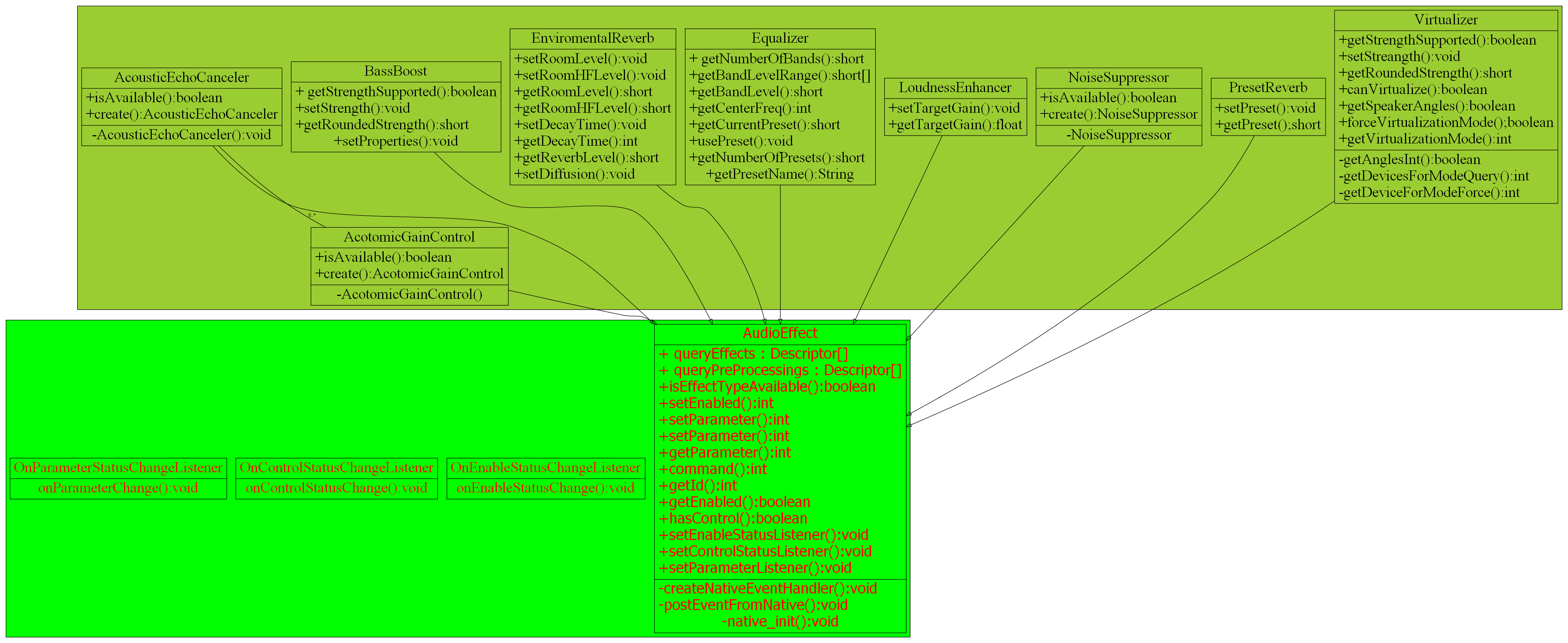 Android Audio Effect 機制初探
Android Audio Effect 機制初探